

Databricks Open-Sources Omnigent: A Meta-Harness That Composes, Governs, and Shares AI Agents Across Claude Code, Codex, and Pi
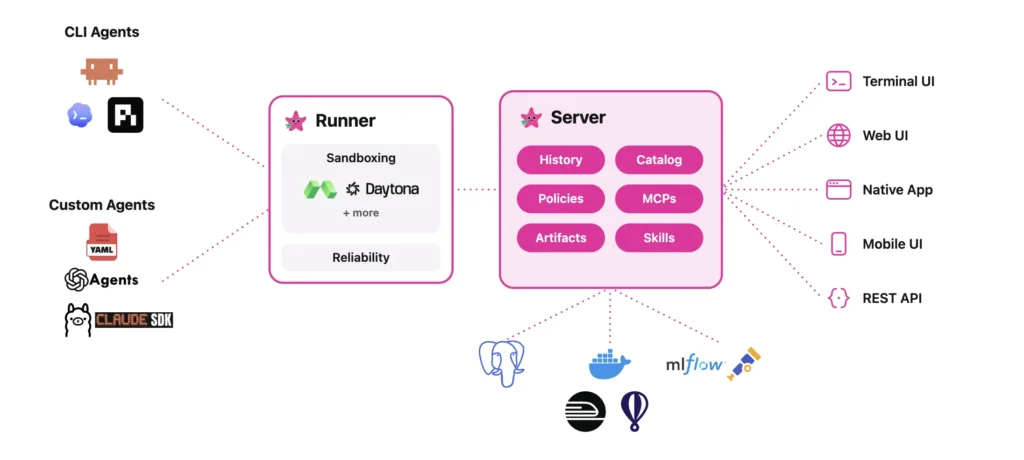
Databricks released Omnigent, an open source ‘meta-harness’ for AI agents. The project ships under the Apache 2.0 license. The Databricks AI team built it with Neon. A harness is the wrapper around a model that turns it into an agent. Claude Code, Codex, and Pi are harnesses. Omnigent sits one level above them. It treats each harness as an interchangeable part of a larger system. Many engineers now juggle four or five agents at once. They copy text between coding agents, search tools, Docs, and Slack. Each harness only understands its own sessions. Omnigent adds a shared layer where composition, control, and collaboration live. What is Omnigent Omnigent is a common interface above command-line agents and agent SDKs. It wraps terminal coding agents such as Claude Code, Codex, and Pi. It also wraps SDKs like OpenAI Agents and the Claude Agents SDK. The design rests on one observation. However a harness calls its model internally, the user-facing interface is the same. Messages and files go in. Text streams and tool calls come out. Omnigent standardizes that interface so harnesses become swappable. You supply the models and the infrastructure. Omnigent runs the agents on top. It can coordinate several of them as interchangeable workers under one orchestrator. How Omnigent Works The architecture has two parts. A runner wraps any agent in a sandboxed session with a uniform API. A server provides policies and sharing. The server exposes every session over the terminal, the app, and web APIs. One command starts a session in your terminal. It also launches a local web UI at localhost:6767. The same session appears in the browser or on a phone. Messages, sub-agents, terminals, and files stay in sync. The CLI installs under two names, omnigent and omni. They are interchangeable. On first run, it detects model credentials already in your environment. https://omnigent.ai/ Composition, Control, and Collaboration Databricks team frames Omnigent around three capabilities: Composition means combining models, harnesses, and techniques without rewriting code. You switch between Claude Code, Codex, Pi, and custom agents with one-line changes. Control means stateful, contextual policies. They track agent actions and enforce guardrails at the meta-harness layer, not through prompts. One example pauses an agent after every $100 it spends. Another requires human approval to git push once the agent installs a new npm package. Collaboration means sharing live agent sessions by URL. Teammates watch the agent work and chat with it in real time. They can comment on files, co-drive the session, or fork the conversation. An OS sandbox, called Omnibox, underpins this. It can lock down OS access and transform network requests. For instance, it can keep your GitHub token hidden from the agent. The token is injected only in the egress proxy on approved requests. Use Cases and Examples Two example agents ship with the repository: Polly is a multi-agent coding orchestrator. It writes no code itself. It plans, then delegates work to coding sub-agents in parallel git worktrees. Each diff routes to a reviewer from a different vendor than the writer. You merge the result. Debby is a brainstorming partner with two heads. One head is Claude, the other GPT. Every question goes to both, with answers shown side by side. Type /debate and the heads critique each other before converging. Other practical patterns follow the same shape. A frontier advisor model can guide a cheaper open-source worker. A lead agent can orchestrate parallel subagents. Different LLMs can handle planning, search, and code generation in one flow. Interactive Concept Demo Marktechpost team has created a interactive demo (below) that lets you experience Omnigent’s meta-harness workflow firsthand. You pick a task for the Polly orchestrator, which plans it and delegates to three sub-agents: Claude Code, Codex, and Pi that are running in parallel and streaming their steps live. A session cost meter ticks up as they work, and the two policy toggles show Omnigent’s control layer in action: the cost budget pauses the run at $3.00 for your approval, and a contextual policy halts a git push that follows an npm install until you allow it. Once the sub-agents finish, each diff is cross-reviewed by a different vendor than the one that wrote it, then marked ready to merge. Terminal, Web, and Mobile tabs show the same session staying in sync across interfaces. It’s an illustrative simulation, no live models are called. ◇ Omnigent Meta-Harness One orchestrator. Many harnesses. One governed session. Interactive concept demo 1 · Pick a task for the orchestrator (Polly) Build REST endpoint + tests Refactor auth module Add caching layer 2 · Policies (control layer) Cost budget — pause at $3.00 Approve git push after npm install Run session ⌘ Terminal ▤ Web UI ▢ Mobile same session · in sync Session LLM cost $0.00 Orchestrator · Polly (writes no code; plans & delegates) Idle. Pick a task and press “Run session”. Claude Codewaiting Codexwaiting Piwaiting ✓ Ready to merge. 3 diffs cross-reviewed by a different vendor than the writer. Illustrative simulation of the Omnigent workflow — no live models are called. Learn more at omnigent.ai · GitHub · Apache 2.0 · Alpha. Marktechpost · AI Dev & Research Media Policy paused the session Reason goes here. Deny / stop Approve & continue ◇ Omnigent Meta-Harness One orchestrator. Many harnesses. One governed session. Interactive concept demo 1 · Pick a task for the orchestrator (Polly) Build REST endpoint + tests Refactor auth module Add caching layer 2 · Policies (control layer) Cost budget — pause at $3.00 Approve git push after npm install Run session ⌘ Terminal ▤ Web UI ▢ Mobile same session · in sync Session LLM cost $0.00 Orchestrator · Polly (writes no code; plans & delegates) Idle. Pick a task and press “Run session”. Claude Codewaiting Codexwaiting Piwaiting ✓ Ready to merge. 3 diffs cross-reviewed by a different vendor than the writer. Illustrative simulation of the Omnigent workflow — no live models are called. Learn more at omnigent.ai · GitHub · Apache 2.0 · Alpha. Marktechpost · AI

