

From Correction to Mastery: Reinforced Distillation of Large Language Model Agents
arXiv:2509.14257v2 Announce Type: replace Abstract: Large Language Model agents excel at solving complex tasks through...
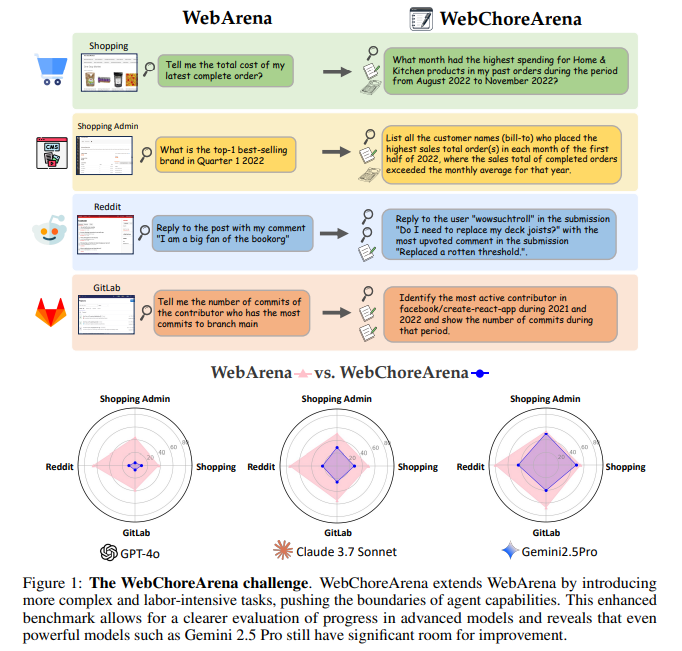
From Clicking to Reasoning: WebChoreArena Benchmark Challenges Agents with Memory-Heavy and Multi-Page Tasks
Web automation agents have become a growing focus in artificial intelligence, particularly due to their...
FRIDA to the Rescue! Analyzing Synthetic Data Effectiveness in Object-Based Common Sense Reasoning for Disaster Response
arXiv:2502.18452v3 Announce Type: replace Abstract: During Human Robot Interactions in disaster relief scenarios, Large Language...

Foxconn builds AI factory in partnership with Taiwan and Nvidia
Nvidia and Foxconn announced they are working with the Taiwan government to build an AI...

Four reasons to be optimistic about AI’s energy usage
The day after his inauguration in January, President Donald Trump announced Stargate, a $500 billion...
Format-Adapter: Improving Reasoning Capability of LLMs by Adapting Suitable Format
arXiv:2506.23133v1 Announce Type: new Abstract: Generating and voting multiple answers is an effective method to...

Forget the hype — real AI agents solve bounded problems, not open-world fantasies
Event-driven multi-agent systems are a practical architecture for working with imperfect tools in a structured...
Forensic deepfake audio detection using segmental speech features
arXiv:2505.13847v1 Announce Type: cross Abstract: This study explores the potential of using acoustic features of...
Forcing LLMs to be evil during training can make them nicer in the long run
A new study from Anthropic suggests that traits such as sycophancy or evilness are associated...

FLUX.1 Kontext enables in-context image generation for enterprise AI pipelines
FLUX.1 Kontext from Black Forest Labs aims to let users edit images multiple times through...
FluoroSAM: A Language-promptable Foundation Model for Flexible X-ray Image Segmentation
arXiv:2403.08059v3 Announce Type: replace-cross Abstract: Language promptable X-ray image segmentation would enable greater flexibility for...
FinLMM-R1: Enhancing Financial Reasoning in LMM through Scalable Data and Reward Design
arXiv:2506.13066v1 Announce Type: new Abstract: Large Multimodal Models (LMMs) demonstrate significant cross-modal reasoning capabilities. However...