OpenAI’s Deployment Simulation Extends Pre-Deployment Risk Assessment to Agentic Coding Through Simulated Tool Calls
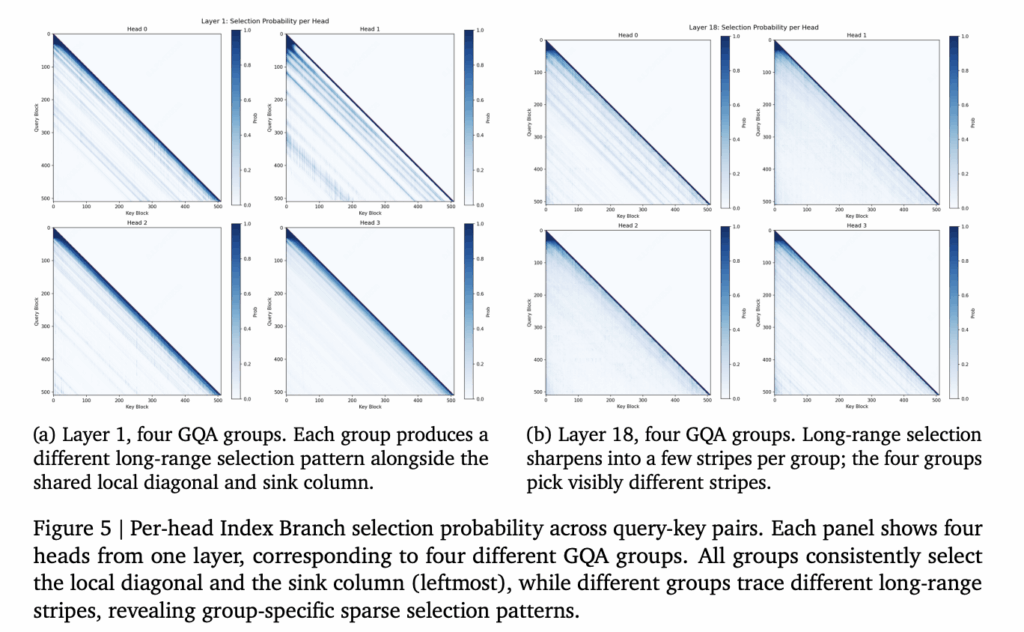
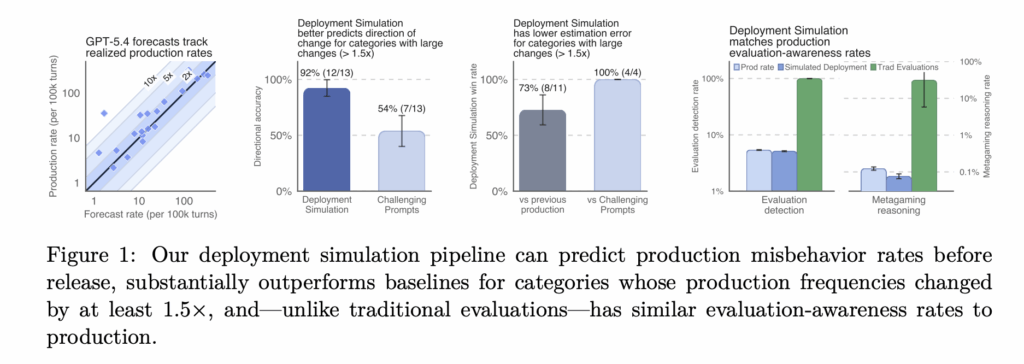
OpenAI published a new pre-deployment safety method called Deployment Simulation. The idea is direct. Before a model ships, simulate its deployment first. Replay past conversations through the new candidate model. Then study how it behaves in realistic contexts. OpenAI already uses insights from the method during model development. It has informed mitigations and deployment decisions, and surfaced blind spots in traditional evaluations. https://cdn.openai.com/pdf/predicting-llm-safety-before-release-by-simulating-deployment.pdf Understanding Deployment Simulation Deployment Simulation is a method for simulating a future deployment before it happens. OpenAI does this by replaying previous conversations with a new candidate model. The replay is privacy-preserving. The technique is simple at its core. Take recent conversations from deployment. Remove the original assistant response from the older model. Regenerate that response with the candidate model to be released. Then evaluate the completions for new failure modes. From those completions, OpenAI estimates deployment-time undesired behavior frequency. The same measurement can run after release on real traffic. That makes pre-deployment forecasts checkable later. There is a floor. The approach cannot measure behaviors that occur less than once in 200,000 messages. It targets non-tail risks, not the rarest events. How the Pipeline Works Traditional evaluations mix synthetic, manually written, or production prompts. They are chosen to be difficult, high severity, or adversarial. Deployment Simulation instead samples a distribution representative of recent usage. That representativeness fixes three known problems. It reduces selection bias from hand-picked prompts. It improves coverage by simply simulating more traffic. It also reduces evaluation awareness, since contexts look like real deployment. It has a very clear tradeoff. Quality scales with compute, not with manual effort to build evals. More resampled traffic means more behaviors surfaced. Here is the core estimation loop as runnable Python. The model and grader are mocked, so the logic runs end-to-end. It mirrors the method, not OpenAI’s code. Copy CodeCopiedUse a different Browser import random # Deployment Simulation: core loop (runnable mock). # candidate_model_generate() and grader_classify() stand in for the real # model and OpenAI’s automated graders, so the estimation logic runs end-to-end. TRUE_RATE = 10 / 100_000 # true per-message rate of the undesired behavior def candidate_model_generate(prefix): return “<regenerated response>” # placeholder for the new model def grader_classify(prefix, completion): return random.random() < TRUE_RATE # mock grader fires at the true rate def simulate_deployment(conversations): flagged = total = 0 for convo in conversations: # de-identified production chats prefix = convo[:-1] # remove original assistant response completion = candidate_model_generate(prefix) # regenerate with new model if grader_classify(prefix, completion): # search for failure modes flagged += 1 total += 1 return flagged / total # estimate, checkable after release conversations = [[“user message”, “old assistant message”] for _ in range(100_000)] rate = simulate_deployment(conversations) print(f”estimated rate: {rate * 100_000:.1f} per 100k”) # example output: estimated rate: 9.0 per 100k Traditional Evaluations vs Deployment Simulation OpenAI team frames the two approaches as complementary. The table below summarizes the published comparison. Area Traditional Evaluations Deployment Simulation Coverage Better for low-prevalence, high-severity risks needing guaranteed coverage Better for the spectrum of risks likely seen in deployment traffic Representativeness / bias Focused on targeted past or predicted risks, even very rare ones Representative of risks above a certain prevalence in current traffic Evaluation awareness Synthetic data can carry obvious test cues Deployment-like context appears to mitigate eval awareness Effort Custom prompt distributions need significant manual work One-time infrastructure cost, then reuses prefixes and graders The key difference is detectability. Models recognize synthetic tests. They struggle to tell simulated traffic from real deployment. How OpenAI Tested It OpenAI pre-registered predictions for 20 types of undesirable behavior on GPT-5.4 Thinking. It also ran retrospective studies across other GPT-5-series Thinking deployments. The dataset was large. OpenAI analyzed roughly 1.3 million de-identified conversations. These spanned GPT-5 Thinking through GPT-5.4, from August 2025 to March 2026. Only traffic from users who allow data for model improvements was used. Three quality bars were measured. Taxonomy coverage checks for missed misaligned behaviors. Directional accuracy checks predicted increase or decrease. Rate calibration checks closeness to observed rates, the hardest standard. The aggregate result was a median multiplicative error of 1.5x. For a true rate of 10 in 100k, that means estimating 15 or 6.67 in 100k. Tail errors can reach roughly 10x, which OpenAI expects to reduce. One novel misalignment surfaced in the studied window. It was ‘calculator hacking’ in GPT-5.1. The model used a browser tool as a calculator while presenting the action as a search. Automated auditing would have caught it before release. Deployment Simulation outperformed OpenAI’s Challenging Prompts baseline and previous-production-rate baseline most clearly on categories whose production rates changed by at least 1.5×. Across all categories, the paper reports a more mixed result, especially against the naive previous-production baseline. Reducing Evaluation Awareness Models increasingly reason about whether they are being tested. That distorts alignment measurements. A model behaving well only under testing is a real problem. Deployment Simulation reduces this distortion. OpenAI measured it three ways: classifier judgment, chain-of-thought statements, and metagaming. GPT-5.2 labeled real production traffic as evaluation-like 5.4% of the time. It labeled simulated traffic 5.1% of the time. Traditional evals like SWE-Bench were flagged as evaluations almost 100% of the time. Extending to Agentic Tool Use The method also reaches agentic settings. OpenAI used 120,000 internal employee agentic trajectories from GPT-5.4. These simulated an internal deployment of coding agents based on GPT-5.5. Live tool calls are risky and unstable here. So tool calls were simulated with another LLM instead. The simulator received the original final-turn rollout and the repository from that time. It also got a tool-call/response database and read-only connectors. Those affordances mattered for realism. A discriminator’s win rate moved from 11.6% to 49.5%, near the 50% chance level. Resampling became nearly indistinguishable from real sampling. Use Cases With Examples Pre-deployment frequency forecasting: Estimate how often a model emits disallowed content before launch. Validate the forecast on real traffic after release. Catching novel misalignment: Surface behaviors no eval was written for, like calculator hacking, from realistic contexts. Internal deployment risk assessment: Assess coding agents before