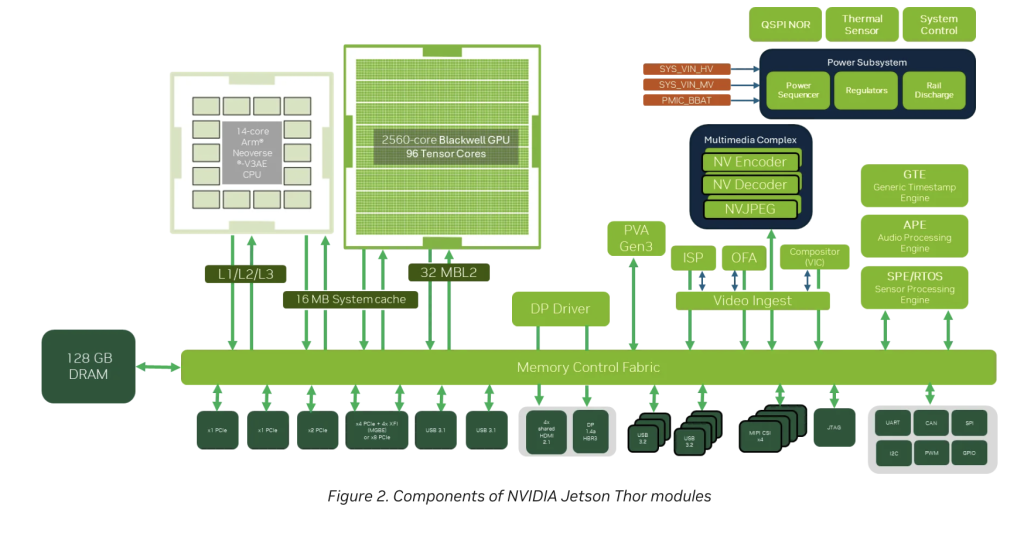
Last week, the NVIDIA robotics team released Jetson Thor that includes Jetson AGX Thor Developer Kit and the Jetson T5000 module, marking a significant milestone for real‑world AI robotics development. Engineered as a supercomputer for physical AI, Jetson Thor brings generative reasoning and multimodal sensor processing to power inference and decision-making at the edge. Architectural Highlights Compute Performance Jetson Thor delivers up to 2,070 FP4 teraflops (TFLOPS) of AI compute via its Blackwell‑based GPU—a leap of 7.5× over the previous Jetson Orin platform. This performance arrives in a 130‑watt power envelope, with configurable operation down to 40 W, balancing high throughput with energy efficiency—approximately 3.5× better than Orin. Compute Architecture At its core, Jetson Thor integrates a 2560‑core Blackwell GPU equipped with 96 fifth‑generation Tensor Cores and supports Multi‑Instance GPU (MIG), enabling flexible partitioning of GPU resources for parallel workloads. Complementing this is a 14‑core Arm® Neoverse‑V3AE CPU, with 1 MB L2 per core and 16 MB shared L3 cache. Memory and I/O The platform includes 128 GB LPDDR5X memory on a 256‑bit bus at 273 GB/s bandwidth. Storage features include a 1 TB NVMe M.2 slot, along with HDMI, DisplayPort, multiple USB, Gigabit Ethernet, CAN headers, and QSFP28 for up to four 25 GbE lanes—crucial for real-time sensor fusion. https://developer.nvidia.com/blog/introducing-nvidia-jetson-thor-the-ultimate-platform-for-physical-ai/ Software Ecosystem for Physical AI Jetson Thor supports a comprehensive NVIDIA software stack tailored for robotics and physical AI: Isaac (GR00T) for generative reasoning and humanoid control. Metropolis for vision AI. Holoscan for real-time, low-latency sensor processing and sensor-over-Ethernet (Holoscan Sensor Bridge). These components allow one system-on-module to execute multimodal AI workflows—vision, language, actuation—without offloading or combining multiple chips. https://developer.nvidia.com/blog/introducing-nvidia-jetson-thor-the-ultimate-platform-for-physical-ai/ Defining ‘Physical AI’ and Its Significance Generative Reasoning & Multimodal Processing Physical AI combines perception, reasoning, and action planning. Jetson Thor enables robots to “simulate possible sequences, anticipate consequences, and generate both high-level plans and low-level motion policies,” delivering adaptability akin to human reasoning. By supporting real-time inference over language and visual inputs, it transforms robots from simple automata into generalist agents. Applications Robots can better navigate unpredictable environments, manipulate objects, or follow complex instructions without reteaching. Use cases span manufacturing, logistics, healthcare, agriculture, and more. Developer Access and Pricing Jetson AGX Thor Developer Kit: priced at $3,499, now generally available. Jetson T5000 production modules: available through NVIDIA’s partners, with unit pricing around $2,999 for orders of 1,000. Pre-orders suggest wider availability soon, catering to both research and commercial robotics ecosystems. Conclusion NVIDIA Jetson Thor represents a pivotal shift in robotics compute—embedding server-grade, multimodal inference, and reasoning capabilities within a single, power-bounded module. Its combination of 2,070 FP4 TFLOPS, high-efficiency design, expansive I/O, and robust software stack positions it as a foundational platform for the next generation of physical AI systems. With early adoption among prominent robotics developers and ready availability, Jetson Thor brings the vision of adaptable, real-world AI agents closer to reality. Check out the FULL TECHNICAL DETAILS. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. The post NVIDIA AI Team Introduces Jetson Thor: The Ultimate Platform for Physical AI and Next-Gen Robotics appeared first on MarkTechPost.