
Enterprise alert: PostgreSQL just became the database you can’t ignore for AI applications
Analysts provide insight on what the latest acquisition of a PostgreSQL database vendor means for enterprise data and AI.Read More


Analysts provide insight on what the latest acquisition of a PostgreSQL database vendor means for enterprise data and AI.Read More
arXiv:2502.14830v2 Announce Type: replace Abstract: While large language models demonstrate remarkable capabilities at task-specific applications through fine-tuning, extending these benefits across diverse languages is essential for broad accessibility. However, effective cross-lingual transfer is hindered by LLM performance gaps across languages and the scarcity of fine-tuning data in many languages. Through analysis of LLM internal representations from over 1,000+ language pairs, we discover that middle layers exhibit the strongest potential for cross-lingual alignment. Building on this finding, we propose a middle-layer alignment objective integrated into task-specific training. Our experiments on slot filling, machine translation, and structured text generation show consistent improvements in cross-lingual transfer, especially to lower-resource languages. The method is robust to the choice of alignment languages and generalizes to languages unseen during alignment. Furthermore, we show that separately trained alignment modules can be merged with existing task-specific modules, improving cross-lingual capabilities without full re-training. Our code is publicly available (https://github.com/dannigt/mid-align).
Middle-Layer Representation Alignment for Cross-Lingual Transfer in Fine-Tuned LLMs Read Post »
arXiv:2505.24229v1 Announce Type: new Abstract: Inverse Text Normalization (ITN) is crucial for converting spoken Automatic Speech Recognition (ASR) outputs into well-formatted written text, enhancing both readability and usability. Despite its importance, the integration of streaming ITN within streaming ASR remains largely unexplored due to challenges in accuracy, efficiency, and adaptability, particularly in low-resource and limited-context scenarios. In this paper, we introduce a streaming pretrained language model for ITN, leveraging pretrained linguistic representations for improved robustness. To address streaming constraints, we propose Dynamic Context-Aware during training and inference, enabling adaptive chunk size adjustments and the integration of right-context information. Experimental results demonstrate that our method achieves accuracy comparable to non-streaming ITN and surpasses existing streaming ITN models on a Vietnamese dataset, all while maintaining low latency, ensuring seamless integration into ASR systems.
Dynamic Context-Aware Streaming Pretrained Language Model For Inverse Text Normalization Read Post »
arXiv:2502.01349v2 Announce Type: replace Abstract: The advent of Large Language Models (LLMs) has revolutionized product recommenders, yet their susceptibility to adversarial manipulation poses critical challenges, particularly in real-world commercial applications. Our approach is the first one to tap into human psychological principles, seamlessly modifying product descriptions, making such manipulations hard to detect. In this work, we investigate cognitive biases as black-box adversarial strategies, drawing parallels between their effects on LLMs and human purchasing behavior. Through extensive evaluation across models of varying scale, we find that certain biases, such as social proof, consistently boost product recommendation rate and ranking, while others, like scarcity and exclusivity, surprisingly reduce visibility. Our results demonstrate that cognitive biases are deeply embedded in state-of-the-art LLMs, leading to highly unpredictable behavior in product recommendations and posing significant challenges for effective mitigation.
Bias Beware: The Impact of Cognitive Biases on LLM-Driven Product Recommendations Read Post »
arXiv:2505.24826v1 Announce Type: new Abstract: As large language models (LLMs) are increasingly used in legal applications, current evaluation benchmarks tend to focus mainly on factual accuracy while largely neglecting important linguistic quality aspects such as clarity, coherence, and terminology. To address this gap, we propose three steps: First, we develop a regression model to evaluate the quality of legal texts based on clarity, coherence, and terminology. Second, we create a specialized set of legal questions. Third, we analyze 49 LLMs using this evaluation framework. Our analysis identifies three key findings: First, model quality levels off at 14 billion parameters, with only a marginal improvement of $2.7%$ noted at 72 billion parameters. Second, engineering choices such as quantization and context length have a negligible impact, as indicated by statistical significance thresholds above 0.016. Third, reasoning models consistently outperform base architectures. A significant outcome of our research is the release of a ranking list and Pareto analysis, which highlight the Qwen3 series as the optimal choice for cost-performance tradeoffs. This work not only establishes standardized evaluation protocols for legal LLMs but also uncovers fundamental limitations in current training data refinement approaches. Code and models are available at: https://github.com/lyxx3rd/LegalEval-Q.
LegalEval-Q: A New Benchmark for The Quality Evaluation of LLM-Generated Legal Text Read Post »
arXiv:2505.24040v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated remarkable performance on various medical question-answering (QA) benchmarks, including standardized medical exams. However, correct answers alone do not ensure correct logic, and models may reach accurate conclusions through flawed processes. In this study, we introduce the MedPAIR (Medical Dataset Comparing Physicians and AI Relevance Estimation and Question Answering) dataset to evaluate how physician trainees and LLMs prioritize relevant information when answering QA questions. We obtain annotations on 1,300 QA pairs from 36 physician trainees, labeling each sentence within the question components for relevance. We compare these relevance estimates to those for LLMs, and further evaluate the impact of these “relevant” subsets on downstream task performance for both physician trainees and LLMs. We find that LLMs are frequently not aligned with the content relevance estimates of physician trainees. After filtering out physician trainee-labeled irrelevant sentences, accuracy improves for both the trainees and the LLMs. All LLM and physician trainee-labeled data are available at: http://medpair.csail.mit.edu/.
MedPAIR: Measuring Physicians and AI Relevance Alignment in Medical Question Answering Read Post »

Claude 4’s “whistle-blow” surprise shows why agentic AI risk lives in prompts and tool access, not benchmarks. Learn the 6 controls every enterprise must adopt.Read More
When your LLM calls the cops: Claude 4’s whistle-blow and the new agentic AI risk stack Read Post »
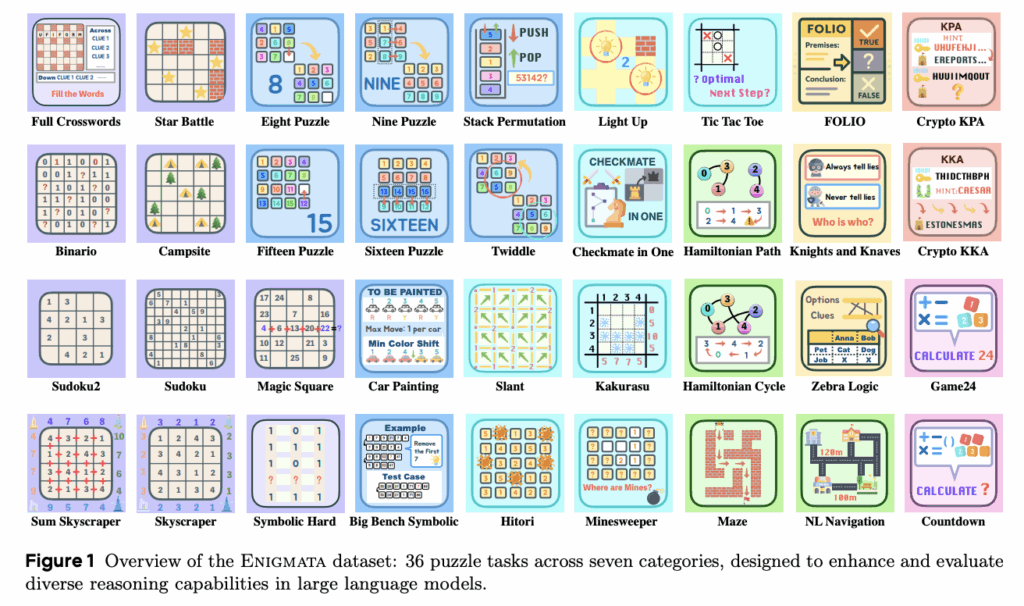
Large Reasoning Models (LRMs), trained from LLMs using reinforcement learning (RL), demonstrated great performance in complex reasoning tasks, including mathematics, STEM, and coding. However, existing LRMs face challenges in completing various puzzle tasks that require purely logical reasoning skills, which are easy and obvious for humans. Current methods targeting puzzles focus only on designing benchmarks for evaluation, lacking the training methods and resources for modern LLMs to tackle this challenge. Current puzzle datasets lack diversity and scalability, covering limited puzzle types with little control over generation or difficulty. Moreover, due to the success of the “LLM+RLVR” paradigm, it has become crucial to obtain large, diverse, and challenging sets of verifiable puzzle prompts for training agents. Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key method for improving models’ reasoning capabilities, removing the need for reward models by directly assigning rewards based on objectively verifiable answers. Puzzles are particularly well-suited for RLVR. However, most prior RLVR research has overlooked the puzzles’ potential for delivering effective reward signals. In puzzle reasoning of LLMs, existing benchmarks evaluate different types of reasoning, including abstract, deductive, and compositional reasoning. Few benchmarks support scalable generation and difficulty control but lack puzzle diversity. Moreover, the improvement of LLMs’ puzzle-solving abilities mainly falls into two categories: tool integration and RLVR. Researchers from ByteDance Seed, Fudan University, Tsinghua University, Nanjing University, and Shanghai Jiao Tong University have proposed Enigmata, the first comprehensive toolkit designed for improving LLMs with puzzle reasoning skills. It contains 36 tasks across seven categories, each featuring a generator that produces unlimited examples with controllable difficulty and a rule-based verifier for automatic evaluation. The researchers further developed Enigmata-Eval as a rigorous benchmark and created optimized multi-task RLVR strategies. Puzzle data from Enigmata enhances SoTA performance on advanced math and STEM reasoning tasks like AIME, BeyondAIME, and GPQA when trained on larger models like Seed1.5-Thinking. This shows the generalization benefits of Enigmata. The Enigmata-Data comprises 36 puzzle tasks organized into 7 primary categories, including Crypto, Arithmetic, Logic, Grid, Graph, Search, and Sequential Puzzle, making it the only dataset having multiple task categories with scalability, automatic verification, and public availability. The data construction follows a three-phase pipeline: Tasks Collection and Design, Auto-Generator and Verifier Development, and Sliding Difficulty Control. Moreover, the Enigmata-Eval is developed by systematically sampling from the broader dataset, aiming to extract 50 instances per difficulty level for each task. The final evaluation set contains 4,758 puzzle instances rather than the theoretical maximum of 5,400, due to inherent constraints, where some tasks generate fewer instances per difficulty level. The proposed model outperforms most public models on Enigmata-Eval with 32B parameters, showing the effectiveness of the dataset and training recipe. The model stands out on the challenging ARC-AGI benchmark, surpassing strong reasoning models such as Gemini 2.5 Pro, o3-mini, and o1. The Qwen2.5-32B-Enigmata shows outstanding performance in structured reasoning categories, outperforming in Crypto, Arithmetic, and Logic tasks, suggesting effective development of rule-based reasoning capabilities. The model shows competitive performance in search tasks that require strategic exploration and planning capabilities. Moreover, Crypto and Arithmetic tasks tend to provide the highest accuracy, while spatial and sequential tasks remain more difficult. In this paper, researchers introduced Enigmata, a comprehensive suite for equipping LLMs with advanced puzzle reasoning that integrates seamlessly with RL using verifiable rule-based rewards. The trained Enigmata-Model shows superior performance and robust generalization skills through RLVR training. Experiments reveal that when applied to larger models such as Seed1.5-Thinking (20B/200B parameters), synthetic puzzle data brings additional benefits in other domains, including mathematics and STEM reasoning over state-of-the-art models. Enigmata provides a solid foundation for the research community to advance reasoning model development, offering a unified framework that effectively bridges logical puzzle-solving with broader reasoning capabilities in LLMs. Check out the Paper, GitHub Page and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter. The post Enigmata’s Multi-Stage and Mix-Training Reinforcement Learning Recipe Drives Breakthrough Performance in LLM Puzzle Reasoning appeared first on MarkTechPost.

Enterprises should experiment with MCP where it adds value, isolate dependencies and prepare for a multi-protocol future.Read More
Model Context Protocol: A promising AI integration layer, but not a standard (yet) Read Post »

Micro Center, an electronics retailer, has opened a store in Silicon Valley in California And so the nerd kingdom has returned.Read More
Micro Center nerd store fills the Fry’s vacuum with its return to Silicon Valley Read Post »
We use cookies to improve your experience and performance on our website. You can learn more at Privacy Policy and manage your privacy settings by clicking Settings.