

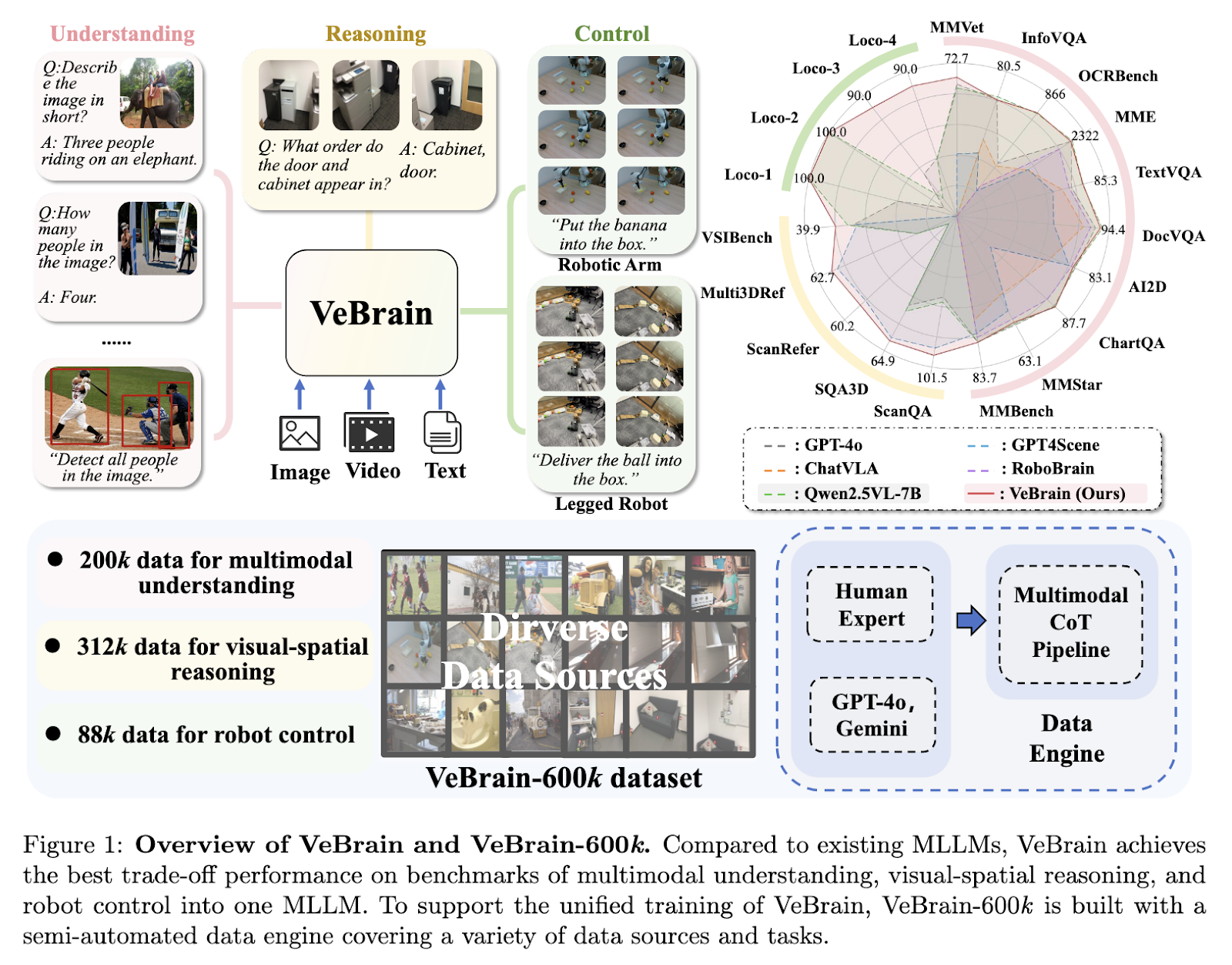
VeBrain: A Unified Multimodal AI Framework for Visual Reasoning and Real-World Robotic Control
Bridging Perception and Action in Robotics Multimodal Large Language Models (MLLMs) hold promise for enabling...
Validating Distributed LLM Serving Benchmarks with NVIDIA srt-slurm, SLURM Recipes, Parameter Sweeps, and Pareto Analysis
In this tutorial, we explore NVIDIA’s srt-slurm framework and learn how we use srtctl to...
UtterTune: LoRA-Based Target-Language Pronunciation Edit and Control in Multilingual Text-to-Speech
arXiv:2508.09767v3 Announce Type: replace-cross Abstract: We propose UtterTune, a lightweight method for adapting a multilingual...
UT-ACA: Uncertainty-Triggered Adaptive Context Allocation for Long-Context Inference
arXiv:2603.18446v1 Announce Type: new Abstract: Long-context inference remains challenging for large language models due to...
Using Sentiment Analysis to Investigate Peer Feedback by Native and Non-Native English Speakers
arXiv:2507.22924v1 Announce Type: new Abstract: Graduate-level CS programs in the U.S. increasingly enroll international students...

Using Scikit-LLM with Open-Source LLMs
This article will teach you how to perform a language task like text classification by...

Using NotebookLM as Your Machine Learning Study Guide
Learning machine learning can be challenging...
US investigators are using AI to detect child abuse images made by AI
Generative AI has enabled the production of child sexual abuse images to skyrocket. Now the...
US deputy health secretary: Vaccine guidelines are still subject to change
Over the past year, Jim O’Neill has become one of the most powerful people in...
UPLex: Fine-Grained Personality Control in Large Language Models via Unsupervised Lexical Modulation
arXiv:2310.16582v3 Announce Type: replace Abstract: Personality is a crucial factor that shapes human communication patterns...
UPCORE: Utility-Preserving Coreset Selection for Balanced Unlearning
arXiv:2502.15082v2 Announce Type: replace-cross Abstract: User specifications or legal frameworks often require information to be...
Unsupervised Hallucination Detection by Inspecting Reasoning Processes
arXiv:2509.10004v1 Announce Type: new Abstract: Unsupervised hallucination detection aims to identify hallucinated content generated by...