


Can We Improve Llama 3’s Reasoning Through Post-Training Alone? ASTRO Shows +16% to +20% Benchmark Gains
Improving the reasoning capabilities of large language models (LLMs) without architectural changes is a core...

Can Vision Language Models Infer Human Gaze Direction? A Controlled Study
arXiv:2506.05412v1 Announce Type: cross Abstract: Gaze-referential inference–the ability to infer what others are looking at–is...
Can structural correspondences ground real world representational content in Large Language Models?
arXiv:2506.16370v1 Announce Type: new Abstract: Large Language Models (LLMs) such as GPT-4 produce compelling responses...
Can Prompting LLMs Unlock Hate Speech Detection across Languages? A Zero-shot and Few-shot Study
arXiv:2505.06149v1 Announce Type: new Abstract: Despite growing interest in automated hate speech detection, most existing...
Can nuclear power really fuel the rise of AI?
In the AI arms race, all the major players say they want to go nuclear. ...
Can Multimodal Foundation Models Understand Schematic Diagrams? An Empirical Study on Information-Seeking QA over Scientific Papers
arXiv:2507.10787v1 Announce Type: new Abstract: This paper introduces MISS-QA, the first benchmark specifically designed to...
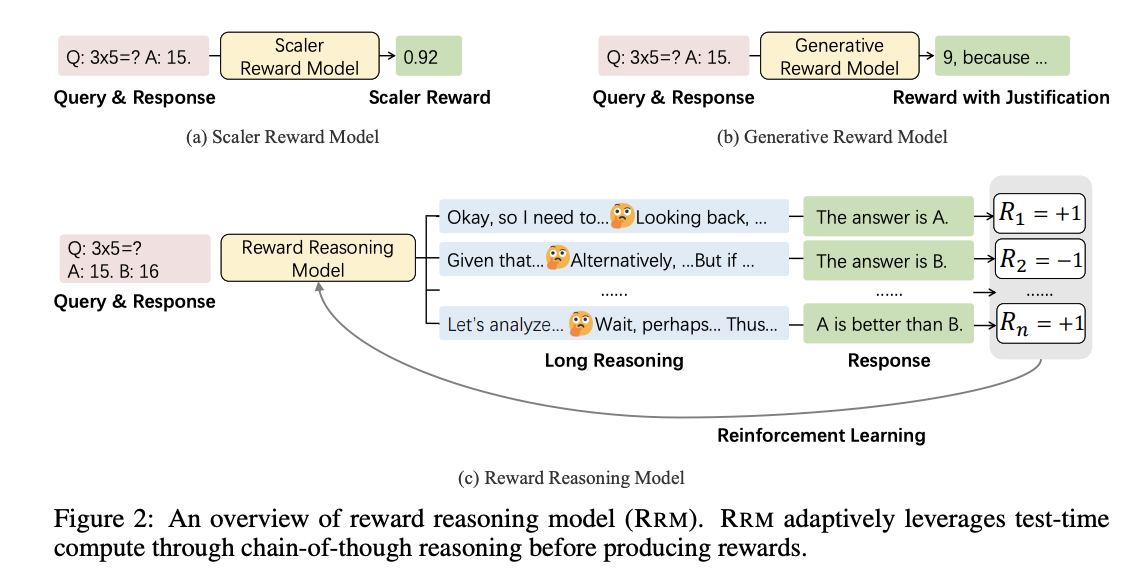
Can LLMs Really Judge with Reasoning? Microsoft and Tsinghua Researchers Introduce Reward Reasoning Models to Dynamically Scale Test-Time Compute for Better Alignment
Reinforcement learning (RL) has emerged as a fundamental approach in LLM post-training, utilizing supervision signals...
Can LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
arXiv:2506.06821v3 Announce Type: replace Abstract: Large Language Models (LLMs) have demonstrated remarkable capabilities in code...
Can Large Language Models Express Uncertainty Like Human?
arXiv:2509.24202v1 Announce Type: new Abstract: Large language models (LLMs) are increasingly used in high-stakes settings...

Can crowdsourced fact-checking curb misinformation on social media?
In a 2019 speech at Georgetown University, Mark Zuckerberg famously declared that he didn’t want...
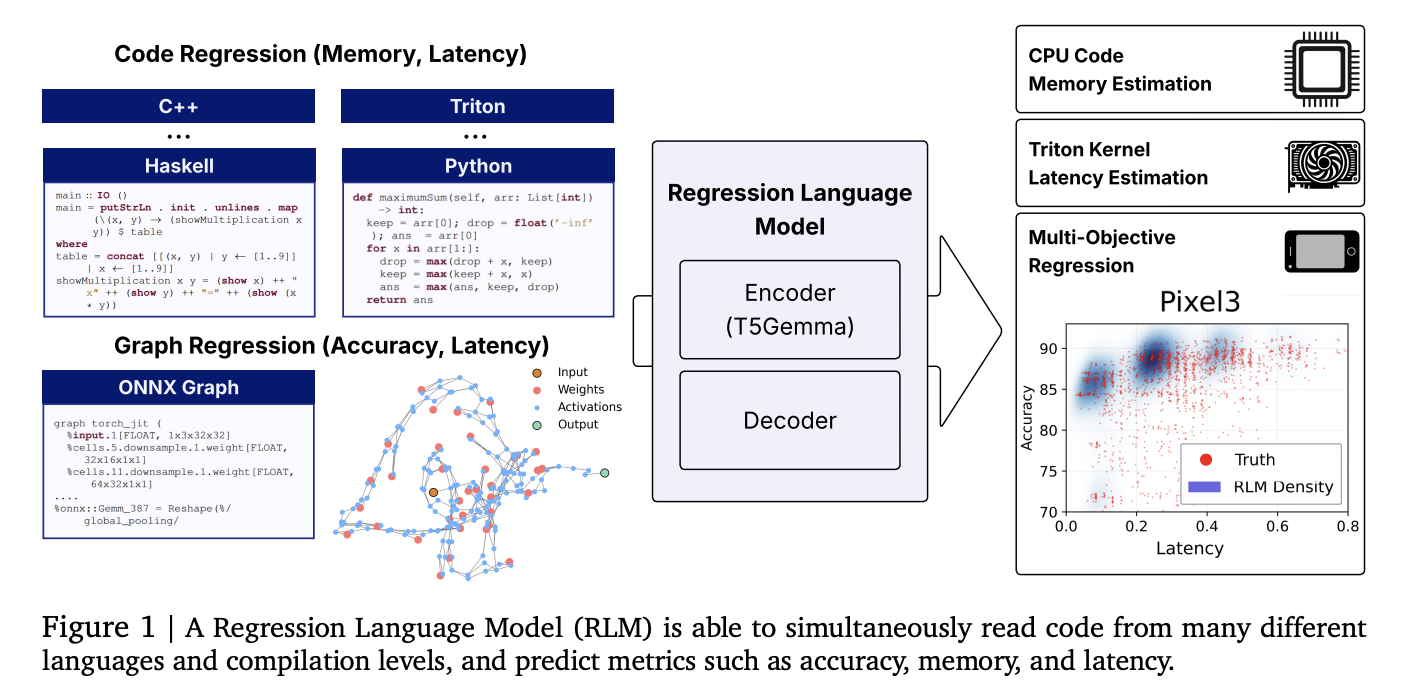
Can a Small Language Model Predict Kernel Latency, Memory, and Model Accuracy from Code? A New Regression Language Model (RLM) Says Yes
Researchers from Cornell and Google introduce a unified Regression Language Model (RLM) that predicts numeric...
Can a Crow Hatch a Falcon? Lineage Matters in Predicting Large Language Model Performance
arXiv:2504.19811v2 Announce Type: replace Abstract: Accurately forecasting the performance of Large Language Models (LLMs) before...