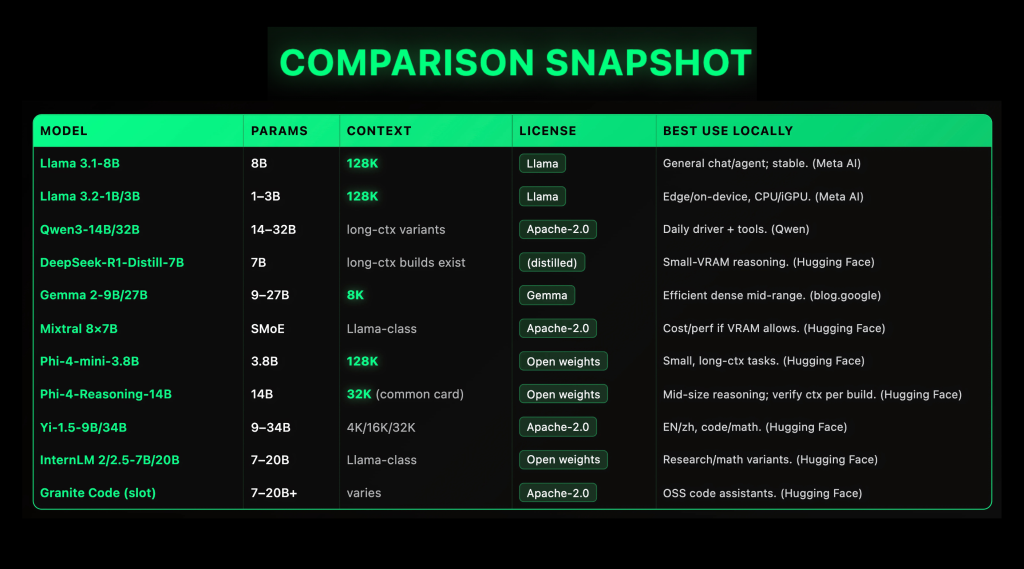
Local LLMs matured fast in 2025: open-weight families like Llama 3.1 (128K context length (ctx)), Qwen3 (Apache-2.0, dense + MoE), Gemma 2 (9B/27B, 8K ctx), Mixtral 8×7B (Apache-2.0 SMoE), and Phi-4-mini (3.8B, 128K ctx) now ship reliable specs and first-class local runners (GGUF/llama.cpp, LM Studio, Ollama), making on-prem and even laptop inference practical if you match context length and quantization to VRAM. This guide lists the ten most deployable options by license clarity, stable GGUF availability, and reproducible performance characteristics (params, context length (ctx), quant presets). Top 10 Local LLMs (2025) 1) Meta Llama 3.1-8B — robust “daily driver,” 128K context Why it matters. A stable, multilingual baseline with long context and first-class support across local toolchains.Specs. Dense 8B decoder-only; official 128K context; instruction-tuned and base variants. Llama license (open weights). Common GGUF builds and Ollama recipes exist. Typical setup: Q4_K_M/Q5_K_M for ≤12-16 GB VRAM, Q6_K for ≥24 GB. 2) Meta Llama 3.2-1B/3B — edge-class, 128K context, on-device friendly Why it matters. Small models that still take 128K tokens and run acceptably on CPUs/iGPUs when quantized; good for laptops and mini-PCs.Specs. 1B/3B instruction-tuned models; 128K context confirmed by Meta. Works well via llama.cpp GGUF and LM Studio’s multi-runtime stack (CPU/CUDA/Vulkan/Metal/ROCm). 3) Qwen3-14B / 32B — open Apache-2.0, strong tool-use & multilingual Why it matters. Broad family (dense+MoE) under Apache-2.0 with active community ports to GGUF; widely reported as a capable general/agentic “daily driver” locally.Specs. 14B/32B dense checkpoints with long-context variants; modern tokenizer; rapid ecosystem updates. Start at Q4_K_M for 14B on 12 GB; move to Q5/Q6 when you have 24 GB+. (Qwen) 4) DeepSeek-R1-Distill-Qwen-7B — compact reasoning that fits Why it matters. Distilled from R1-style reasoning traces; delivers step-by-step quality at 7B with widely available GGUFs. Excellent for math/coding on modest VRAM.Specs. 7B dense; long-context variants exist per conversion; curated GGUFs cover F32→Q4_K_M. For 8–12 GB VRAM try Q4_K_M; for 16–24 GB use Q5/Q6. 5) Google Gemma 2-9B / 27B — efficient dense; 8K context (explicit) Why it matters. Strong quality-for-size and quantization behavior; 9B is a great mid-range local model.Specs. Dense 9B/27B; 8K context (don’t overstate); open weights under Gemma terms; widely packaged for llama.cpp/Ollama. 9B@Q4_K_M runs on many 12 GB cards. 6) Mixtral 8×7B (SMoE) — Apache-2.0 sparse MoE; cost/perf workhorse Why it matters. Mixture-of-Experts throughput benefits at inference: ~2 experts/token selected at runtime; great compromise when you have ≥24–48 GB VRAM (or multi-GPU) and want stronger general performance.Specs. 8 experts of 7B each (sparse activation); Apache-2.0; instruct/base variants; mature GGUF conversions and Ollama recipes. 7) Microsoft Phi-4-mini-3.8B — small model, 128K context Why it matters. Realistic “small-footprint reasoning” with 128K context and grouped-query attention; solid for CPU/iGPU boxes and latency-sensitive tools.Specs. 3.8B dense; 200k vocab; SFT/DPO alignment; model card documents 128K context and training profile. Use Q4_K_M on ≤8–12 GB VRAM. 8) Microsoft Phi-4-Reasoning-14B — mid-size reasoning (check ctx per build) Why it matters. A 14B reasoning-tuned variant that is materially better for chain-of-thought-style tasks than generic 13–15B baselines.Specs. Dense 14B; context varies by distribution (model card for a common release lists 32K). For 24 GB VRAM, Q5_K_M/Q6_K is comfortable; mixed-precision runners (non-GGUF) need more. 9) Yi-1.5-9B / 34B — Apache-2.0 bilingual; 4K/16K/32K variants Why it matters. Competitive EN/zh performance and permissive license; 9B is a strong alternative to Gemma-2-9B; 34B steps toward higher reasoning under Apache-2.0.Specs. Dense; context variants 4K/16K/32K; open weights under Apache-2.0 with active HF cards/repos. For 9B use Q4/Q5 on 12–16 GB. 10) InternLM 2 / 2.5-7B / 20B — research-friendly; math-tuned branches Why it matters. An open series with lively research cadence; 7B is a practical local target; 20B moves you toward Gemma-2-27B-class capability (at higher VRAM).Specs. Dense 7B/20B; multiple chat/base/math variants; active HF presence. GGUF conversions and Ollama packs are common. source: marktechpost.com Summary In local LLMs, the trade-offs are clear: pick dense models for predictable latency and simpler quantization (e.g., Llama 3.1-8B with a documented 128K context; Gemma 2-9B/27B with an explicit 8K window), move to sparse MoE like Mixtral 8×7B when your VRAM and parallelism justify higher throughput per cost, and treat small reasoning models (Phi-4-mini-3.8B, 128K) as the sweet spot for CPU/iGPU boxes. Licenses and ecosystems matter as much as raw scores: Qwen3’s Apache-2.0 releases (dense + MoE) and Meta/Google/Microsoft model cards give the operational guardrails (context, tokenizer, usage terms) you’ll actually live with. On the runtime side, standardize on GGUF/llama.cpp for portability, layer Ollama/LM Studio for convenience and hardware offload, and size quantization (Q4→Q6) to your memory budget. In short: choose by context + license + hardware path, not just leaderboard vibes. The post Top 10 Local LLMs (2025): Context Windows, VRAM Targets, and Licenses Compared appeared first on MarkTechPost.