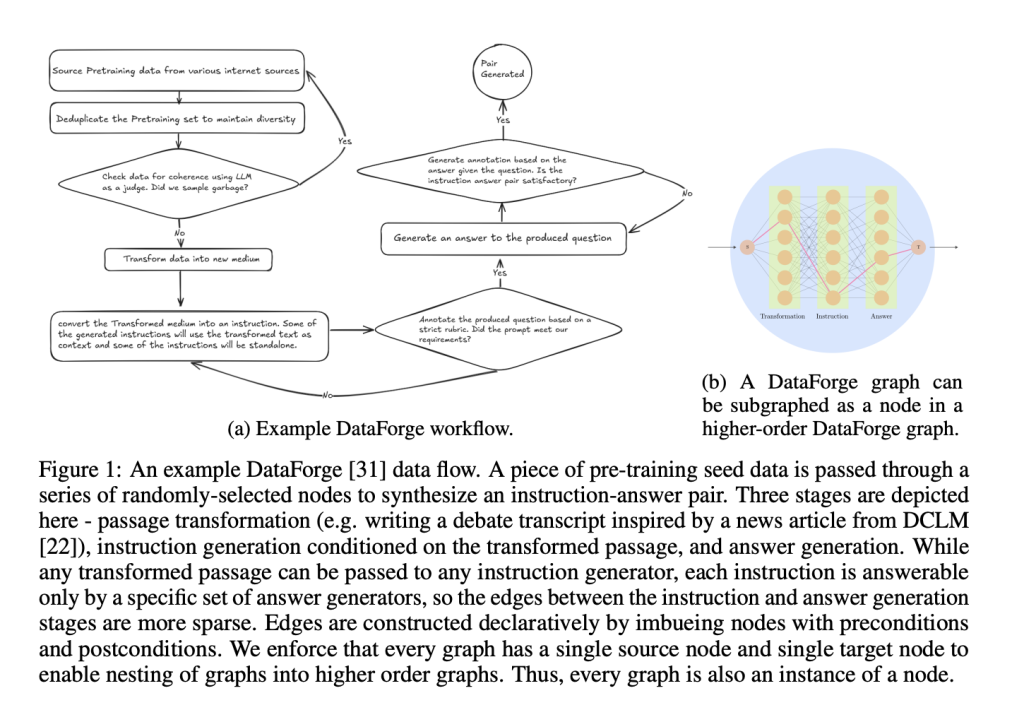
Nous Research has released Hermes 4, a family of open-weight models (14B, 70B, and 405B parameter sizes based on Llama 3.1 checkpoints) that achieves frontier-level performance through pure post-training techniques. Hermes 4 introduces hybrid reasoning – models can toggle between standard responses and explicit reasoning using <think>…</think> tags when complex problems require deeper deliberation. What makes Hermes 4 particularly significant is its achievement of state-of-the-art performance among open-weight models while maintaining complete transparency and neutral alignment philosophy, demonstrating that sophisticated reasoning capabilities can be developed entirely through open-source methodologies. DataForge: Graph-Based Synthetic Data Generation DataForge is the main component behind Hermes 4’s core structure. But what is DataForge? DataForge is a revolutionary graph-based synthetic data generation system that transforms how training data is created. Unlike traditional curation approaches, DataForge operates through a directed acyclic graph (DAG) where each node implements a PDDL (Planning Domain Definition Language) action interface. Each node specifies preconditions, postconditions, and transformations, facilitating the automatic creation of complex data pipelines. By using pre-training seed data from DCLM and FineWeb, the system can transform a Wikipedia article into a rap song, and then generate instruction-answer pairs based on that transformation. This approach generates approximately 5 million samples totaling 19 billion tokens, with reasoning samples being intentionally token-heavy – averaging five times more tokens than non-reasoning counterparts to accommodate thinking traces up to 16,000 tokens long. https://arxiv.org/pdf/2508.18255 Rejection Sampling at Unprecedented Scale Hermes 4 uses Atropos, Nous Research’s open-source reinforcement learning environment, to implement rejection sampling across approximately 1,000 different task-specific verifiers. This massive verification infrastructure filters for high-quality reasoning trajectories across diverse domains. Key verification environments include Answer Format Training (rewarding correct formatting across 150+ output formats), Instruction Following (using RLVR-IFEval tasks with complex constraints), Schema Adherence (for JSON generation using Pydantic models), and Tool Use training for agentic behavior. The rejection sampling process creates a large corpus of verified reasoning trajectories, with multiple unique solution paths to the same verified result. This approach ensures the model learns robust reasoning patterns rather than memorizing specific solution templates. Length Control: Solving Overlong Generation One of Hermes 4’s most innovative contributions addresses the overlong reasoning problem – where reasoning models generate excessively long chains of thought without termination. The research team discovered their 14B model reached maximum context length 60% of the time on LiveCodeBench when in reasoning mode. Their super effective solution involves a second supervised fine-tuning stage teaching models to stop reasoning at exactly 30,000 tokens: Generate reasoning traces from the current policy Insert </think> tokens at exactly 30,000 tokens Train only on the termination decision, not the reasoning chain Apply gradient updates solely to </think> and <eos> tokens This approach achieves remarkable results: 78.4% reduction in overlong generation on AIME’24, 65.3% on AIME’25, and 79.8% on LiveCodeBench, with only 4.7% to 12.7% relative accuracy cost. By focusing learning signals entirely on the termination decision, the method avoids model collapse risks while teaching effective “counting behavior.” https://hermes4.nousresearch.com/ https://hermes4.nousresearch.com/ Benchmark Performance and Neutral Alignment Hermes 4 demonstrates state-of-the-art performance among open-weight models. The 405B model achieves 96.3% on MATH-500 (reasoning mode), 81.9% on AIME’24, 78.1% on AIME’25, 70.5% on GPQA Diamond, and 61.3% on LiveCodeBench. Particularly notable is its performance on RefusalBench, achieving 57.1% in reasoning mode – the highest score among evaluated models, significantly outperforming GPT-4o (17.67%) and Claude Sonnet 4 (17%). This demonstrates the model’s willingness to engage with controversial topics while maintaining appropriate boundaries, reflecting Nous Research’s neutral alignment philosophy. https://arxiv.org/pdf/2508.18255 Technical Architecture and Training Hermes 4 training leverages a modified TorchTitan across 192 NVIDIA B200 GPUs. The system handles highly heterogeneous sample length distribution through efficient packing (achieving >99.9% batch efficiency), flex attention, and sophisticated loss masking where only assistant-role tokens contribute to cross-entropy loss. Training follows a cosine learning rate schedule with 300 warmup steps and 9,000 total steps at 16,384 token context length with global batch size of 384 samples, combining Data Parallelism, Tensor Parallelism, and Fully Sharded Data Parallelism. Summary Hermes 4 marks a significant advancement in open-source AI development, proving that frontier-level reasoning capabilities can be achieved through transparent, reproducible methodologies without relying on proprietary training data or closed development processes. By combining innovative graph-based synthetic data generation, massive-scale rejection sampling, and elegant length control mechanisms, Nous Research has created models that not only match the performance of leading proprietary systems but also maintain the neutral alignment and steerability that make them genuinely useful tools rather than restrictive assistants Check out the Paper, Technical details, Model on Hugging Face and Chat. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. The post Nous Research Team Releases Hermes 4: A Family of Open-Weight AI Models with Hybrid Reasoning appeared first on MarkTechPost.