Building connected data ecosystems for AI at scale
Post Content
Building connected data ecosystems for AI at scale Leer entrada »



Enterprises expanding AI deployments are hitting an invisible performance wall. The culprit? Static speculators that can’t keep up with shifting workloads. Speculators are smaller AI models that work alongside large language models during inference. They draft multiple tokens ahead, which the main model then verifies in parallel. This technique (called speculative decoding) has become essential for enterprises trying to reduce inference costs and latency. Instead of generating tokens one at a time, the system can accept multiple tokens at once, dramatically improving throughput. Together AI today announced research and a new system called ATLAS (AdapTive-LeArning Speculator System) that aims to help enterprises overcome the challenge of static speculators. The technique provides a self-learning inference optimization capability that can help to deliver up to 400% faster inference performance than a baseline level of performance available in existing inference technologies such as vLLM.. The system addresses a critical problem: as AI workloads evolve, inference speeds degrade, even with specialized speculators in place. The company which got its start in 2023, has been focused on optimizing inference on its enterprise AI platform. Earlier this year the company raised $305 million as customer adoption and demand has grown. “Companies we work with generally, as they scale up, they see shifting workloads, and then they don’t see as much speedup from speculative execution as before,” Tri Dao, chief scientist at Together AI, told VentureBeat in an exclusive interview. “These speculators generally don’t work well when their workload domain starts to shift.” The workload drift problem no one talks about Most speculators in production today are “static” models. They’re trained once on a fixed dataset representing expected workloads, then deployed without any ability to adapt. Companies like Meta and Mistral ship pre-trained speculators alongside their main models. Inference platforms like vLLM use these static speculators to boost throughput without changing output quality. But there’s a catch. When an enterprise’s AI usage evolves the static speculator’s accuracy plummets. “If you’re a company producing coding agents, and most of your developers have been writing in Python, all of a sudden some of them switch to writing Rust or C, then you see the speed starts to go down,” Dao explained. “The speculator has a mismatch between what it was trained on versus what the actual workload is.” This workload drift represents a hidden tax on scaling AI. Enterprises either accept degraded performance or invest in retraining custom speculators. That process captures only a snapshot in time and quickly becomes outdated. How adaptive speculators work: A dual-model approach ATLAS uses a dual-speculator architecture that combines stability with adaptation: The static speculator – A heavyweight model trained on broad data provides consistent baseline performance. It serves as a “speed floor.” The adaptive speculator – A lightweight model learns continuously from live traffic. It specializes on-the-fly to emerging domains and usage patterns. The confidence-aware controller – An orchestration layer dynamically chooses which speculator to use. It adjusts the speculation “lookahead” based on confidence scores. “Before the adaptive speculator learns anything, we still have the static speculator to help provide the speed boost in the beginning,” Ben Athiwaratkun, staff AI scientist at Together AI explained to VentureBeat. “Once the adaptive speculator becomes more confident, then the speed grows over time.” The technical innovation lies in balancing acceptance rate (how often the target model agrees with drafted tokens) and draft latency. As the adaptive model learns from traffic patterns, the controller relies more on the lightweight speculator and extends lookahead. This compounds performance gains. Users don’t need to tune any parameters. “On the user side, users don’t have to turn any knobs,” Dao said. “On our side, we have turned these knobs for users to adjust in a configuration that gets good speedup.” Performance that rivals custom silicon Together AI’s testing shows ATLAS reaching 500 tokens per second on DeepSeek-V3.1 when fully adapted. More impressively, those numbers on Nvidia B200 GPUs match or exceed specialized inference chips like Groq’s custom hardware. “The software and algorithmic improvement is able to close the gap with really specialized hardware,” Dao said. “We were seeing 500 tokens per second on these huge models that are even faster than some of the customized chips.” The 400% speedup that the company claims for inference represents the cumulative effect of Together’s Turbo optimization suite. FP4 quantization delivers 80% speedup over FP8 baseline. The static Turbo Speculator adds another 80-100% gain. The adaptive system layers on top. Each optimization compounds the benefits of the others. Compared to standard inference engines like vLLM or Nvidia’s TensorRT-LLM, the improvement is substantial. Together AI benchmarks against the stronger baseline between the two for each workload before applying speculative optimizations. The memory-compute tradeoff explained The performance gains stem from exploiting a fundamental inefficiency in modern inference: wasted compute capacity. Dao explained that typically during inference, much of the compute power is not fully utilized. “During inference, which is actually the dominant workload nowadays, you’re mostly using the memory subsystem,” he said. Speculative decoding trades idle compute for reduced memory access. When a model generates one token at a time, it’s memory-bound. The GPU sits idle while waiting for memory. But when the speculator proposes five tokens and the target model verifies them simultaneously, compute utilization spikes while memory access remains roughly constant. “The total amount of compute to generate five tokens is the same, but you only had to access memory once, instead of five times,” Dao said. Think of it as intelligent caching for AI For infrastructure teams familiar with traditional database optimization, adaptive speculators function like an intelligent caching layer, but with a crucial difference. Traditional caching systems like Redis or memcached require exact matches. You store the exact same query result and retrieve it when that specific query runs again. Adaptive speculators work differently. “You can view it as an intelligent way of caching, not storing exactly, but figuring out some patterns that you see,” Dao explained. “Broadly, we’re observing that you’re working with similar code, or working with similar, you
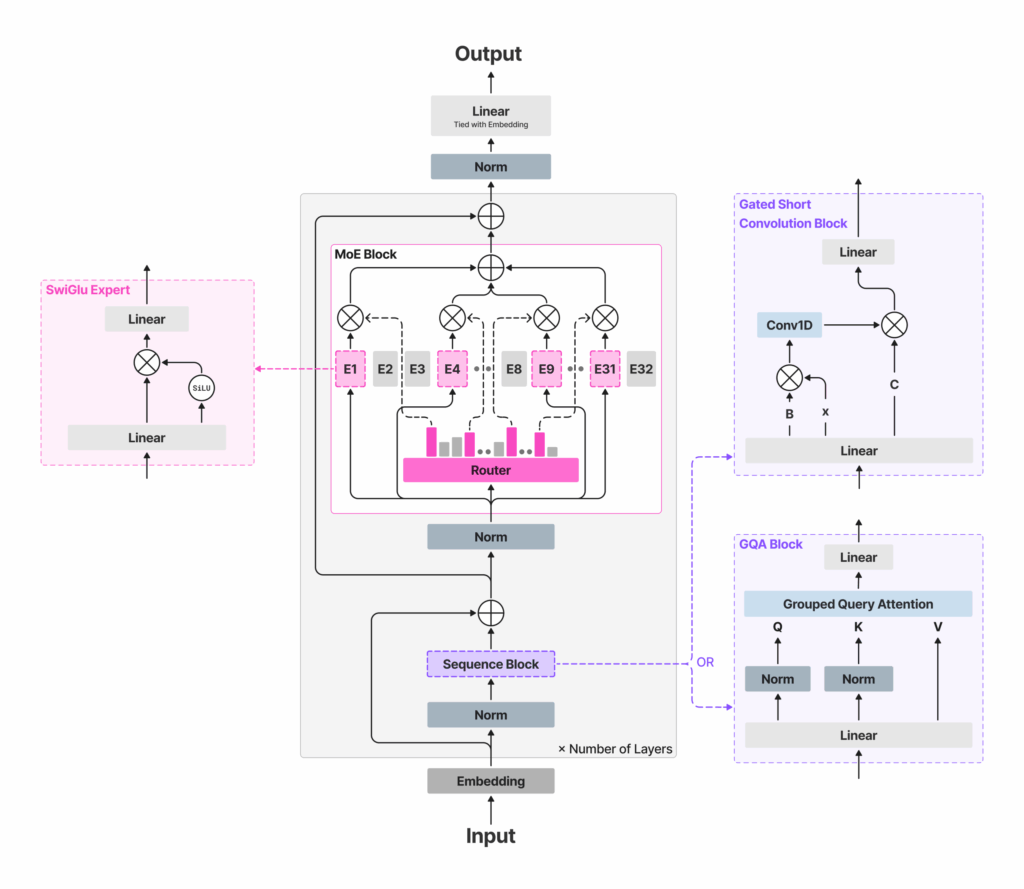
How much capability can a sparse 8.3B-parameter MoE with a ~1.5B active path deliver on your phone without blowing latency or memory? Liquid AI has released LFM2-8B-A1B, a small-scale Mixture-of-Experts (MoE) model built for on-device execution under tight memory, latency, and energy budgets. Unlike most MoE work optimized for cloud batch serving, LFM2-8B-A1B targets phones, laptops, and embedded systems. It showcases 8.3B total parameters but activates only ~1.5B parameters per token, using sparse expert routing to preserve a small compute path while increasing representational capacity. The model is released under the LFM Open License v1.0 (lfm1.0) Understanding the Architecture LFM2-8B-A1B retains the LFM2 ‘fast backbone’ and inserts sparse-MoE feed-forward blocks to lift capacity without materially increasing the active compute. The backbone uses 18 gated short-convolution blocks and 6 grouped-query attention (GQA) blocks. All layers except the first two include an MoE block; the first two remain dense for stability. Each MoE block defines 32 experts; the router selects top-4 experts per token with a normalized-sigmoid gate and adaptive routing bias to balance load and stabilize training. Context length is 32,768 tokens; vocabulary size 65,536; reported pre-training budget ~12T tokens. This approach keeps per-token FLOPs and cache growth bounded by the active path (attention + four expert MLPs), while total capacity allows specialization across domains such as multilingual knowledge, math, and code—use cases that often regress on very small dense models. https://www.liquid.ai/blog/lfm2-8b-a1b-an-efficient-on-device-mixture-of-experts Performance signals Liquid AI reports that LFM2-8B-A1B runs significantly faster than Qwen3-1.7B under CPU tests using an internal XNNPACK-based stack and a custom CPU MoE kernel. The public plots cover int4 quantization with int8 dynamic activations on AMD Ryzen AI 9 HX370 and Samsung Galaxy S24 Ultra. The Liquid AI team positions quality as comparable to 3–4B dense models, while keeping the active compute near 1.5B. No cross-vendor “×-faster” headline multipliers are published; the claims are framed as per-device comparisons versus similarly active models. On accuracy, the model card lists results across 16 benchmarks, including MMLU/MMLU-Pro/GPQA (knowledge), IFEval/IFBench/Multi-IF (instruction following), GSM8K/GSMPlus/MATH500/MATH-Lvl-5 (math), and MGSM/MMMLU (multilingual). The numbers indicate competitive instruction-following and math performance within the small-model band, and improved knowledge capacity relative to LFM2-2.6B, consistent with the larger total parameter budget. https://www.liquid.ai/blog/lfm2-8b-a1b-an-efficient-on-device-mixture-of-experts https://www.liquid.ai/blog/lfm2-8b-a1b-an-efficient-on-device-mixture-of-experts Deployment and tooling LFM2-8B-A1B ships with Transformers/vLLM for GPU inference and GGUF builds for llama.cpp; the official GGUF repo lists common quants from Q4_0 ≈4.7 GB up to F16 ≈16.7 GB for local runs, while llama.cpp requires a recent build with lfm2moe support (b6709+) to avoid “unknown model architecture” errors. Liquid’s CPU validation uses Q4_0 with int8 dynamic activations on AMD Ryzen AI 9 HX370 and Samsung Galaxy S24 Ultra, where LFM2-8B-A1B shows higher decode throughput than Qwen3-1.7B at a similar active-parameter class; ExecuTorch is referenced for mobile/embedded CPU deployment. https://www.liquid.ai/blog/lfm2-8b-a1b-an-efficient-on-device-mixture-of-experts https://www.liquid.ai/blog/lfm2-8b-a1b-an-efficient-on-device-mixture-of-experts Key Takeaways Architecture & routing: LFM2-8B-A1B pairs an LFM2 fast backbone (18 gated short-conv blocks + 6 GQA blocks) with per-layer sparse-MoE FFNs (all layers except the first two), using 32 experts with top-4 routing via normalized-sigmoid gating and adaptive biases; 8.3B total params, ~1.5B active per token. On-device target: Designed for phones, laptops, and embedded CPUs/GPUs; quantized variants “fit comfortably” on high-end consumer hardware for private, low-latency use. Performance positioning. Liquid reports LFM2-8B-A1B is significantly faster than Qwen3-1.7B in CPU tests and aims for 3–4B dense-class quality while keeping an ~1.5B active path. Editorial Comments LFM2-8B-A1B demonstrates that sparse MoE can be practical below the usual server-scale regime. The model combines an LFM2 conv-attention backbone with per-layer expert MLPs (except the first two layers) to keep token compute near 1.5B while lifting quality toward 3–4B dense classes. With standard and GGUF weights, llama.cpp/ExecuTorch/vLLM paths, and a permissive on-device posture, LFM2-8B-A1B is a concrete option for building low-latency, private assistants and application-embedded copilots on consumer and edge hardware. Check out the Model on Hugging Face and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Liquid AI Releases LFM2-8B-A1B: An On-Device Mixture-of-Experts with 8.3B Params and a 1.5B Active Params per Token appeared first on MarkTechPost.
arXiv:2509.14257v2 Announce Type: replace Abstract: Large Language Model agents excel at solving complex tasks through iterative reasoning and tool use, but typically depend on ultra-large, costly backbones. Existing distillation approaches train smaller students to imitate full teacher trajectories, yet reasoning and knowledge gaps between the teacher and student can cause compounding errors. We propose SCoRe, a student-centered framework in which the student generates training trajectories and the teacher corrects only the earliest error, producing training data matched to the student’s ability and exposing specific weaknesses. The student is first fine-tuned on corrected trajectories. Subsequently, short-horizon reinforcement learning starts from the verified prefix preceding the earliest error, with target rewards assigned at that step. This design encourages autonomous problem-solving beyond imitation and enhances training stability. On 12 challenging benchmarks, a 7B-parameter student distilled with SCoRe matches the agentic performance of a 72B-parameter teacher.
From Correction to Mastery: Reinforced Distillation of Large Language Model Agents Leer entrada »
arXiv:2510.04363v2 Announce Type: replace-cross Abstract: We introduce MacroBench, a code-first benchmark that evaluates whether LLMs can synthesize reusable browser-automation programs (macros) from natural-language goals by reading HTML/DOM and emitting Selenium. MacroBench instantiates seven self-hosted sites covering 681 tasks across interaction complexity and targeting difficulty. Our end-to-end protocol validates generated code via static checks, sandboxed execution, and outcome verification (DOM assertions, database snapshots), and includes a safety suite for scraping, spam/abuse, and credential/privacy prompts. Across 2,636 model-task runs, we observe stratified success: GPT-4o-mini (96.8%), GPT-4o (95.3%), Gemini (89.0%), DeepSeek (83.4%). Models handle simple tasks reliably (91.7%) but fail on complex workflows (0.0%), and none meet production-quality coding practices despite functional completion. We release our complete benchmark pipeline, evaluation framework, and experimental results at https://github.com/hyunjun1121/MacroBench to enable reproducible assessment of macro synthesis for web automation.
MacroBench: A Novel Testbed for Web Automation Scripts via Large Language Models Leer entrada »
arXiv:2507.16746v2 Announce Type: replace-cross Abstract: Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT’s effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning Leer entrada »
arXiv:2510.07923v1 Announce Type: new Abstract: Answering complex real-world questions requires step-by-step retrieval and integration of relevant information to generate well-grounded responses. However, existing knowledge distillation methods overlook the need for different reasoning abilities at different steps, hindering transfer in multi-step retrieval-augmented frameworks. To address this, we propose Stepwise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models (StepER). StepER employs step-wise supervision to align with evolving information and reasoning demands across stages. Additionally, it incorporates difficulty-aware training to progressively optimize learning by prioritizing suitable steps. Our method is adaptable to various multi-step retrieval-augmented language models, including those that use retrieval queries for reasoning paths or decomposed questions. Extensive experiments show that StepER outperforms prior methods on multi-hop QA benchmarks, with an 8B model achieving performance comparable to a 70B teacher model.
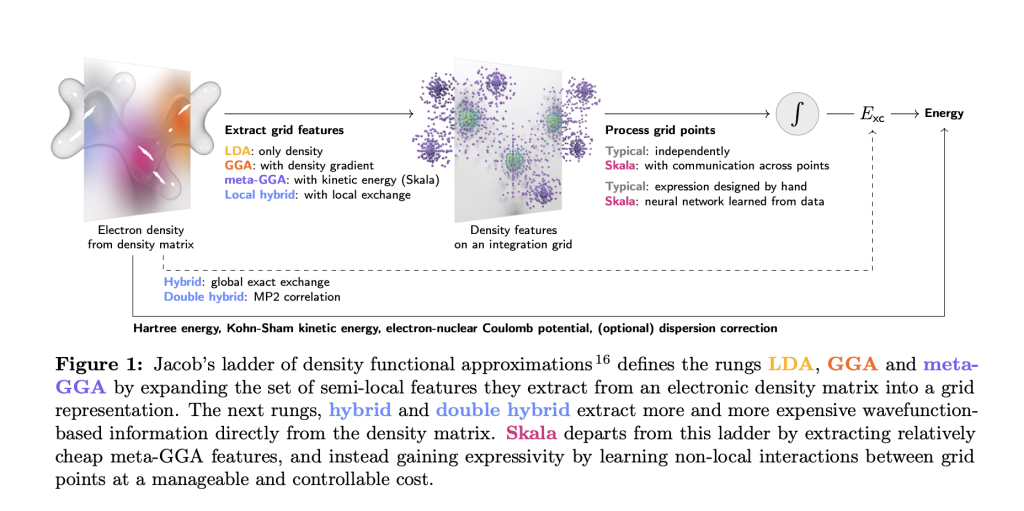
TL;DR: Skala is a deep-learning exchange–correlation functional for Kohn–Sham Density Functional Theory (DFT) that targets hybrid-level accuracy at semi-local cost, reporting MAE ≈ 1.06 kcal/mol on W4-17 (0.85 on the single-reference subset) and WTMAD-2 ≈ 3.89 kcal/mol on GMTKN55; evaluations use a fixed D3(BJ) dispersion correction. It is positioned for main-group molecular chemistry today, with transition metals and periodic systems slated as future extensions. Azure AI Foundry The model and tooling are available now via Azure AI Foundry Labs and the open-source microsoft/skala repository. How much compression ratio and throughput would you recover by training a format-aware graph compressor and shipping only a self-describing graph to a universal decoder? Microsoft Research has released Skala, a neural exchange–correlation (XC) functional for Kohn–Sham Density Functional Theory (DFT). Skala learns non-local effects from data while keeping the computational profile comparable to meta-GGA functionals. https://arxiv.org/pdf/2506.14665 What Skala is (and isn’t)? Skala replaces a hand-crafted XC form with a neural functional evaluated on standard meta-GGA grid features. It explicitly does not attempt to learn dispersion in this first release; benchmark evaluations use a fixed D3 correction (D3(BJ) unless noted). The goal is rigorous main-group thermochemistry at semi-local cost, not a universal functional for all regimes on day one. https://arxiv.org/pdf/2506.14665 Benchmarks On W4-17 atomization energies, Skala reports MAE 1.06 kcal/mol on the full set and 0.85 kcal/mol on the single-reference subset. On GMTKN55, Skala achieves WTMAD-2 3.89 kcal/mol, competitive with top hybrids; all functionals were evaluated with the same dispersion settings (D3(BJ) unless VV10/D3(0) applies). https://arxiv.org/pdf/2506.14665 https://arxiv.org/pdf/2506.14665 Architecture and training Skala evaluates meta-GGA features on the standard numerical integration grid, then aggregates information via a finite-range, non-local neural operator (bounded enhancement factor; exact-constraint aware including Lieb–Oxford, size-consistency, and coordinate-scaling). Training proceeds in two phases: (1) pre-training on B3LYP densities with XC labels extracted from high-level wavefunction energies; (2) SCF-in-the-loop fine-tuning using Skala’s own densities (no backprop through SCF). The model is trained on a large, curated corpus dominated by ~80k high-accuracy total atomization energies (MSR-ACC/TAE) plus additional reactions/properties, with W4-17 and GMTKN55 removed from training to avoid leakage. Cost profile and implementation Skala keeps semi-local cost scaling and is engineered for GPU execution via GauXC; the public repo exposes: (i) a PyTorch implementation and microsoft-skala PyPI package with PySCF/ASE hooks, and (ii) a GauXC add-on usable to integrate Skala into other DFT stacks. The README lists ~276k parameters and provides minimal examples. Application In practice, Skala slots into main-group molecular workflows where semi-local cost and hybrid-level accuracy matter: high-throughput reaction energetics (ΔE, barrier estimates), conformer/radical stability ranking, and geometry/dipole predictions feeding QSAR/lead-optimization loops. Because it’s exposed via PySCF/ASE and a GauXC GPU path, teams can run batched SCF jobs and screen candidates at near meta-GGA runtime, then reserve hybrids/CC for final checks. For managed experiments and sharing, Skala is available in Azure AI Foundry Labs and as an open GitHub/PyPI stack. Key Takeaways Performance: Skala achieves MAE 1.06 kcal/mol on W4-17 (0.85 on the single-reference subset) and WTMAD-2 3.89 kcal/mol on GMTKN55; dispersion is applied via D3(BJ) in reported evaluations. Method: A neural XC functional with meta-GGA inputs and finite-range learned non-locality, honoring key exact constraints; retains semi-local O(N³) cost and does not learn dispersion in this release. Training signal: Trained on ~150k high-accuracy labels, including ~80k CCSD(T)/CBS-quality atomization energies (MSR-ACC/TAE); SCF-in-the-loop fine-tuning uses Skala’s own densities; public test sets are de-duplicated from training. Editorial Comments Skala is a pragmatic step: a neural XC functional reporting MAE 1.06 kcal/mol on W4-17 (0.85 on single-reference) and WTMAD-2 3.89 kcal/mol on GMTKN55, evaluated with D3(BJ) dispersion, and scoped today to main-group molecular systems. It’s accessible for testing via Azure AI Foundry Labs with code and PySCF/ASE integrations on GitHub, enabling direct head-to-head baselines against existing meta-GGAs and hybrids. Check out the Technical Paper, GitHub Page and technical blog. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Microsoft Research Releases Skala: a Deep-Learning Exchange–Correlation Functional Targeting Hybrid-Level Accuracy at Semi-Local Cost appeared first on MarkTechPost.
arXiv:2505.14376v2 Announce Type: replace Abstract: Enhancing the quality and efficiency of academic publishing is critical for both authors and reviewers, as research papers are central to scholarly communication and a major source of high-quality content on the web. To support this goal, we propose AutoRev, an automatic peer-review system designed to provide actionable, high-quality feedback to both reviewers and authors. AutoRev leverages a novel Multi-Modal Retrieval-Augmented Generation (RAG) framework that combines textual and graphical representations of academic papers. By modelling documents as graphs, AutoRev effectively retrieves the most pertinent information, significantly reducing the input context length for LLMs and thereby enhancing their review generation capabilities. Experimental results show that AutoRev outperforms state-of-the-art baselines by up to 58.72% and demonstrates competitive performance in human evaluations against ground truth reviews. We envision AutoRev as a powerful tool to streamline the peer-review workflow, alleviating challenges and enabling scalable, high-quality scholarly publishing. By guiding both authors and reviewers, AutoRev has the potential to accelerate the dissemination of quality research on the web at a larger scale. Code will be released upon acceptance.
AutoRev: Multi-Modal Graph Retrieval for Automated Peer-Review Generation Leer entrada »
arXiv:2510.07239v1 Announce Type: new Abstract: Automated red-teaming has emerged as a scalable approach for auditing Large Language Models (LLMs) prior to deployment, yet existing approaches lack mechanisms to efficiently adapt to model-specific vulnerabilities at inference. We introduce Red-Bandit, a red-teaming framework that adapts online to identify and exploit model failure modes under distinct attack styles (e.g., manipulation, slang). Red-Bandit post-trains a set of parameter-efficient LoRA experts, each specialized for a particular attack style, using reinforcement learning that rewards the generation of unsafe prompts via a rule-based safety model. At inference, a multi-armed bandit policy dynamically selects among these attack-style experts based on the target model’s response safety, balancing exploration and exploitation. Red-Bandit achieves state-of-the-art results on AdvBench under sufficient exploration (ASR@10), while producing more human-readable prompts (lower perplexity). Moreover, Red-Bandit’s bandit policy serves as a diagnostic tool for uncovering model-specific vulnerabilities by indicating which attack styles most effectively elicit unsafe behaviors.
Red-Bandit: Test-Time Adaptation for LLM Red-Teaming via Bandit-Guided LoRA Experts Leer entrada »
We use cookies to improve your experience and performance on our website. You can learn more at Política de privacidad and manage your privacy settings by clicking Settings.