


Evaluating Creative Short Story Generation in Humans and Large Language Models
arXiv:2411.02316v5 Announce Type: replace Abstract: Story-writing is a fundamental aspect of human imagination, relying heavily...

Evaluating and Improving Robustness in Large Language Models: A Survey and Future Directions
arXiv:2506.11111v1 Announce Type: new Abstract: Large Language Models (LLMs) have gained enormous attention in recent...
Evaluating $n$-Gram Novelty of Language Models Using Rusty-DAWG
arXiv:2406.13069v4 Announce Type: replace Abstract: How novel are texts generated by language models (LMs) relative...
EvalTree: Profiling Language Model Weaknesses via Hierarchical Capability Trees
arXiv:2503.08893v2 Announce Type: replace Abstract: An ideal model evaluation should achieve two goals: identifying where...
Estimating LLM Uncertainty with Logits
arXiv:2502.00290v4 Announce Type: replace Abstract: Over the past few years, Large Language Models (LLMs) have...
Erasing Conceptual Knowledge from Language Models
arXiv:2410.02760v3 Announce Type: replace Abstract: In this work, we introduce Erasure of Language Memory (ELM)...
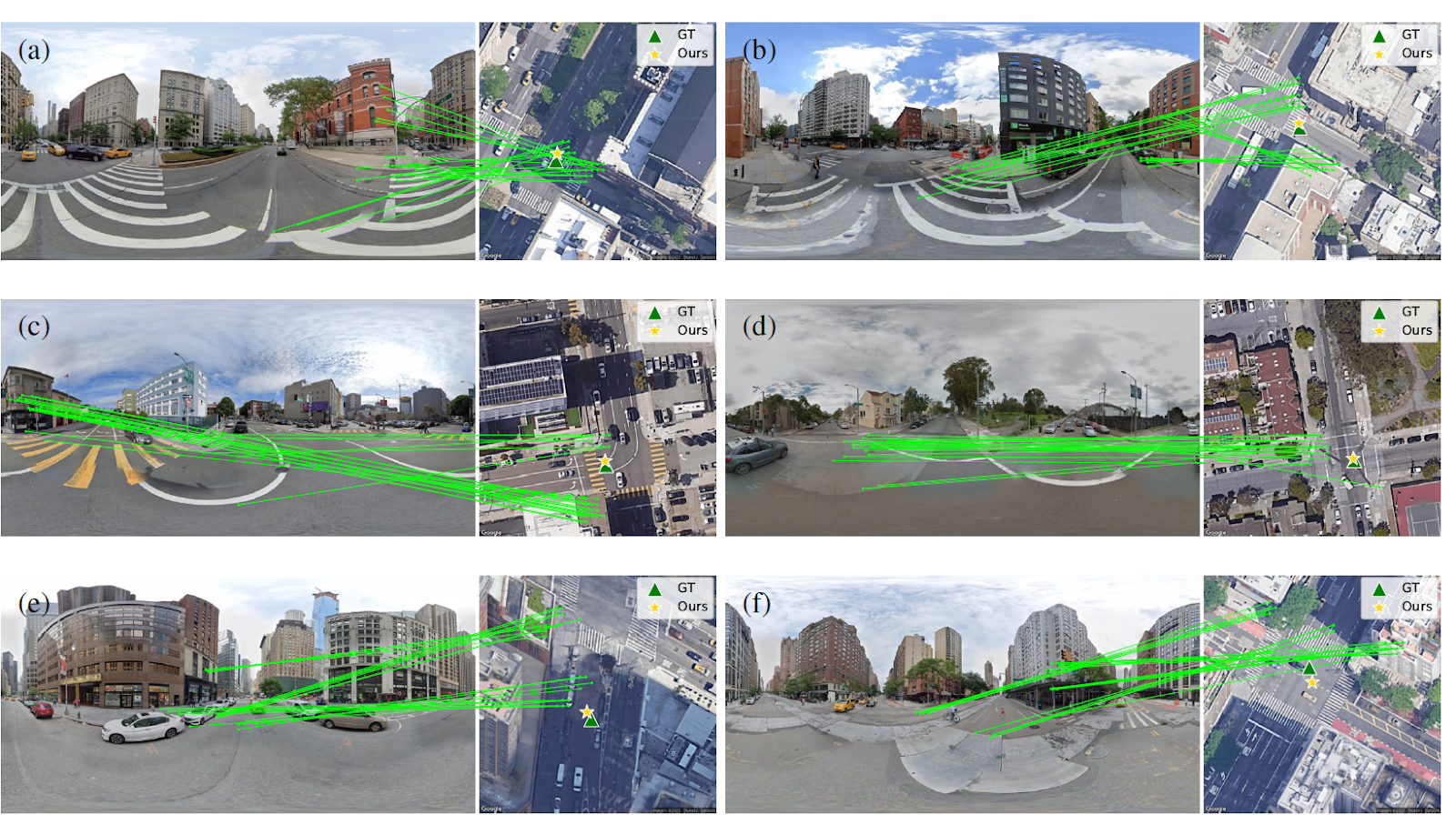
EPFL Researchers Unveil FG2 at CVPR: A New AI Model That Slashes Localization Errors by 28% for Autonomous Vehicles in GPS-Denied Environments
Navigating the dense urban canyons of cities like San Francisco or New York can be...
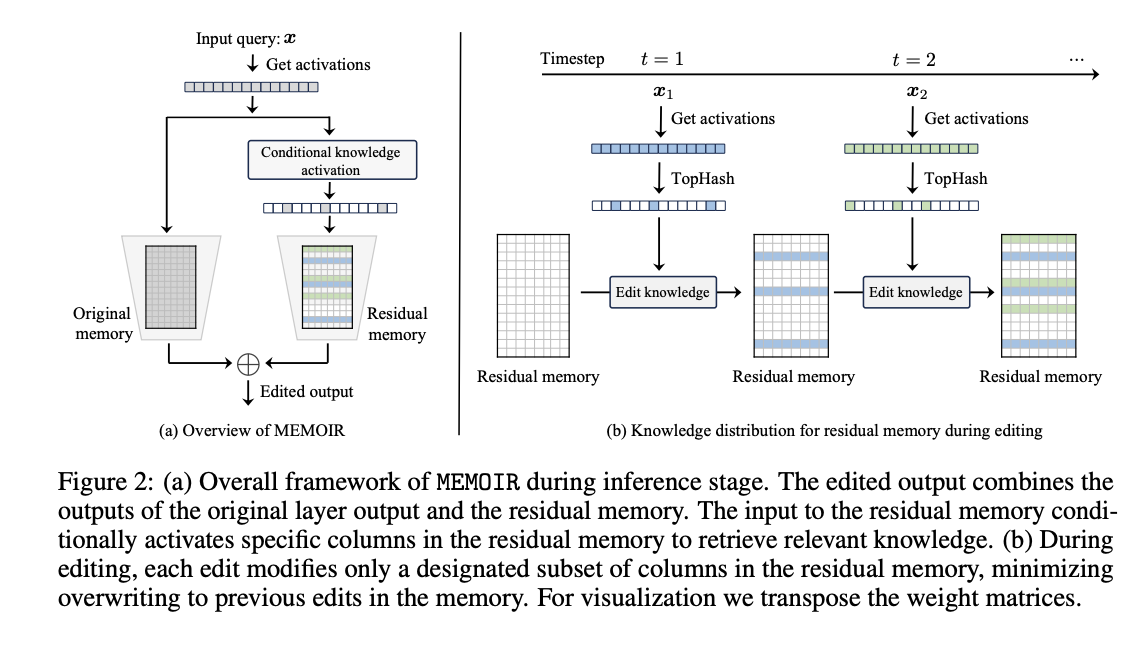
EPFL Researchers Introduce MEMOIR: A Scalable Framework for Lifelong Model Editing in LLMs
The Challenge of Updating LLM Knowledge LLMs have shown outstanding performance for various tasks through...
Entropy2Vec: Crosslingual Language Modeling Entropy as End-to-End Learnable Language Representations
arXiv:2509.05060v1 Announce Type: new Abstract: We introduce Entropy2Vec, a novel framework for deriving cross-lingual language...

Enterprise alert: PostgreSQL just became the database you can’t ignore for AI applications
Analysts provide insight on what the latest acquisition of a PostgreSQL database vendor means for...
Enterprise AI Without GPU Burn: Salesforce’s xGen-small Optimizes for Context, Cost, and Privacy
Language processing in enterprise environments faces critical challenges as business workflows increasingly depend on synthesising...
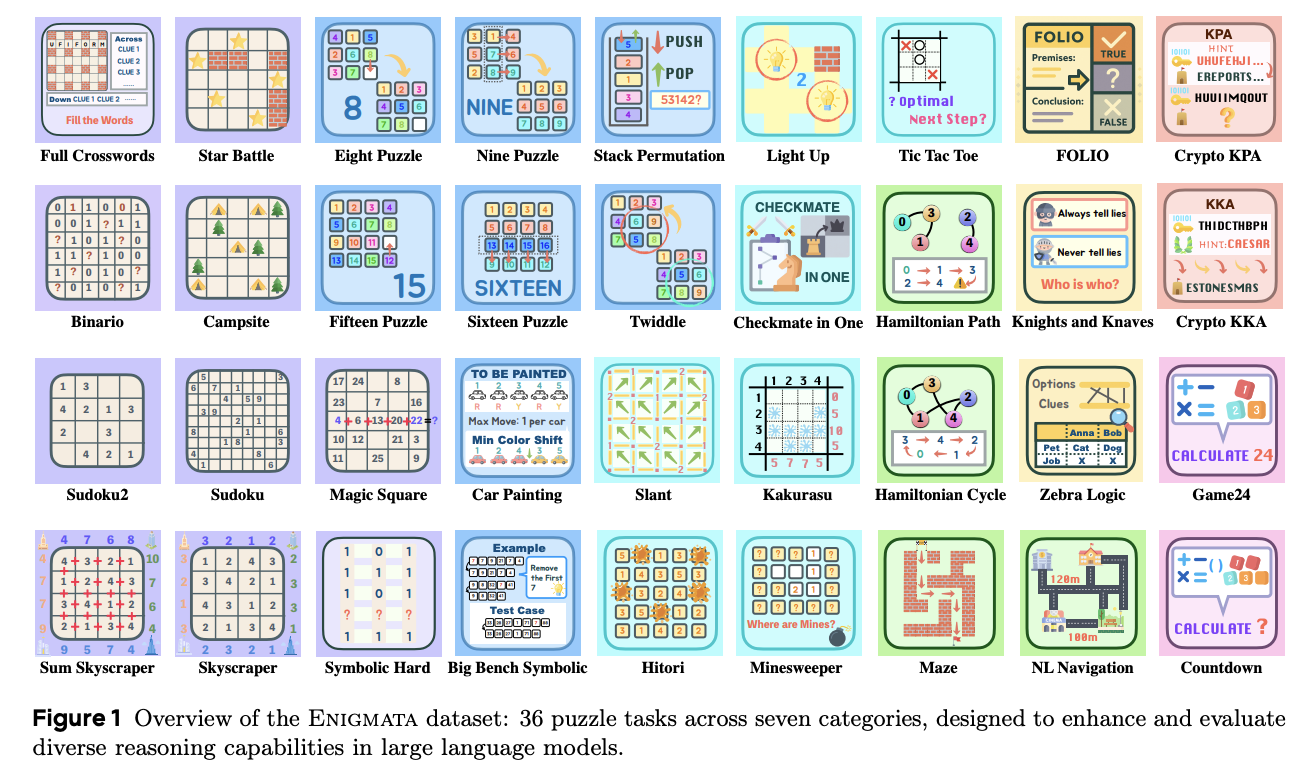
Enigmata’s Multi-Stage and Mix-Training Reinforcement Learning Recipe Drives Breakthrough Performance in LLM Puzzle Reasoning
Large Reasoning Models (LRMs), trained from LLMs using reinforcement learning (RL), demonstrated great performance in...