

Prompt-R1: Collaborative Automatic Prompting Framework via End-to-end Reinforcement Learning
arXiv:2511.01016v3 Announce Type: replace Abstract: Recently, advanced large language models (LLMs) have emerged at an...
Prompt Optimization as a State-Space Search Problem
arXiv:2511.18619v1 Announce Type: new Abstract: Language Models are extremely susceptible to performance collapse with even...
Prompt engineering does not universally improve Large Language Model performance across clinical decision-making tasks
arXiv:2512.22966v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated promise in medical knowledge...
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
arXiv:2509.26574v3 Announce Type: replace-cross Abstract: While large language models (LLMs) with reasoning capabilities are progressing...
Probing Neural Topology of Large Language Models
arXiv:2506.01042v3 Announce Type: replace Abstract: Probing large language models (LLMs) has yielded valuable insights into...
Probabilistic Aggregation and Targeted Embedding Optimization for Collective Moral Reasoning in Large Language Models
arXiv:2506.14625v2 Announce Type: replace Abstract: Large Language Models (LLMs) have shown impressive moral reasoning abilities...
Proactive Defense: Compound AI for Detecting Persuasion Attacks and Measuring Inoculation Effectiveness
arXiv:2511.21749v1 Announce Type: new Abstract: This paper introduces BRIES, a novel compound AI architecture designed...
PRISM: Prompt-Refined In-Context System Modelling for Financial Retrieval
arXiv:2511.14130v1 Announce Type: cross Abstract: With the rapid progress of large language models (LLMs), financial...
Prioritizing Image-Related Tokens Enhances Vision-Language Pre-Training
arXiv:2505.08971v1 Announce Type: cross Abstract: In standard large vision-language models (LVLMs) pre-training, the model typically...
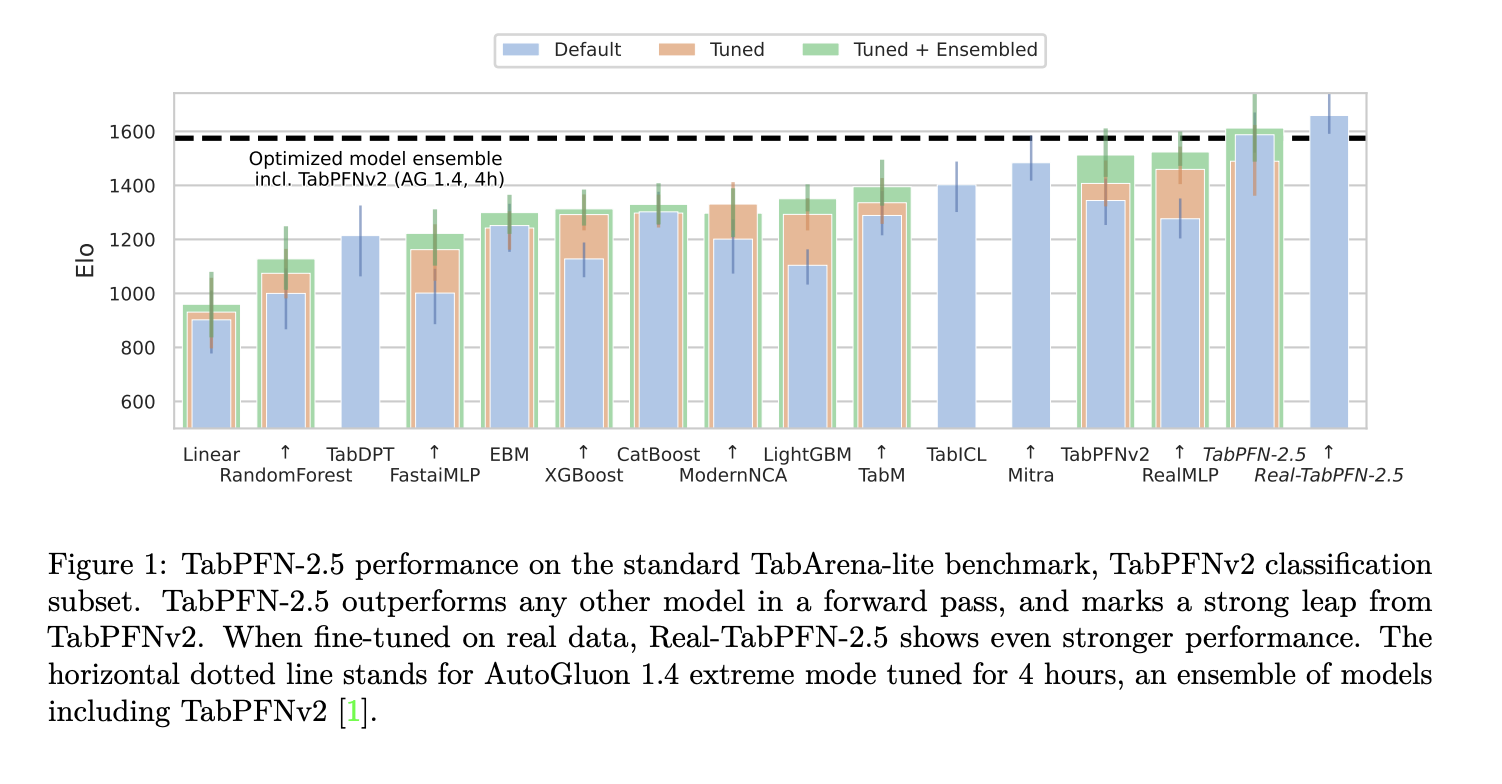
Prior Labs Releases TabPFN-2.5: The Latest Version of TabPFN that Unlocks Scale and Speed for Tabular Foundation Models
Tabular data is still where many important models run in production. Finance, healthcare, energy and...

Pretrain a BERT Model from Scratch
This article is divided into three parts; they are: • Creating a BERT Model the...

Preparing Data for BERT Training
This article is divided into four parts; they are: • Preparing Documents • Creating Sentence...