


Teaching AI to Say ‘I Don’t Know’: A New Dataset Mitigates Hallucinations from Reinforcement Finetuning
Reinforcement finetuning uses reward signals to guide the large language model toward desirable behavior. This...
TaxoBell: Gaussian Box Embeddings for Self-Supervised Taxonomy Expansion
arXiv:2601.09633v1 Announce Type: new Abstract: Taxonomies form the backbone of structured knowledge representation across diverse...

TaxoAdapt: Aligning LLM-Based Multidimensional Taxonomy Construction to Evolving Research Corpora
arXiv:2506.10737v1 Announce Type: new Abstract: The rapid evolution of scientific fields introduces challenges in organizing...
Take Out Your Calculators: Estimating the Real Difficulty of Question Items with LLM Student Simulations
arXiv:2601.09953v1 Announce Type: new Abstract: Standardized math assessments require expensive human pilot studies to establish...
Tag&Tab: Pretraining Data Detection in Large Language Models Using Keyword-Based Membership Inference Attack
arXiv:2501.08454v2 Announce Type: replace-cross Abstract: Large language models (LLMs) have become essential tools for digital...
TAG-EQA: Text-And-Graph for Event Question Answering via Structured Prompting Strategies
arXiv:2510.01391v1 Announce Type: new Abstract: Large language models (LLMs) excel at general language tasks but...
T3DM: Test-Time Training-Guided Distribution Shift Modelling for Temporal Knowledge Graph Reasoning
arXiv:2507.01597v1 Announce Type: cross Abstract: Temporal Knowledge Graph (TKG) is an efficient method for describing...
T2ISafety: Benchmark for Assessing Fairness, Toxicity, and Privacy in Image Generation
arXiv:2501.12612v3 Announce Type: replace Abstract: Text-to-image (T2I) models have rapidly advanced, enabling the generation of...
T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
arXiv:2505.00703v2 Announce Type: replace-cross Abstract: Recent advancements in large language models have demonstrated how chain-of-thought...
T-pro 2.0: An Efficient Russian Hybrid-Reasoning Model and Playground
arXiv:2512.10430v1 Announce Type: new Abstract: We introduce T-pro 2.0, an open-weight Russian LLM for hybrid...
System Report for CCL25-Eval Task 10: SRAG-MAV for Fine-Grained Chinese Hate Speech Recognition
arXiv:2507.18580v1 Announce Type: new Abstract: This paper presents our system for CCL25-Eval Task 10, addressing...
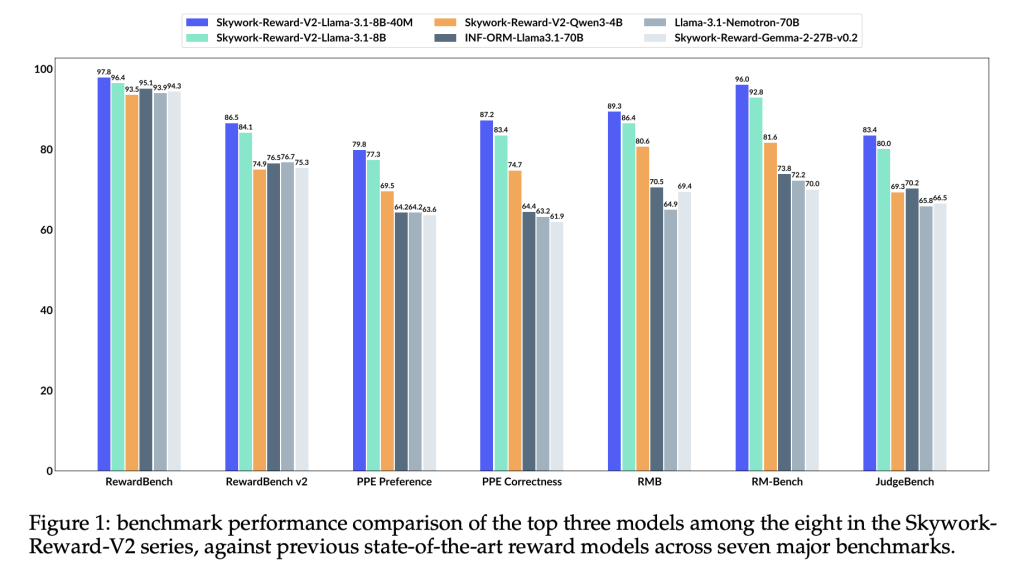
SynPref-40M and Skywork-Reward-V2: Scalable Human-AI Alignment for State-of-the-Art Reward Models
Understanding Limitations of Current Reward Models Although reward models play a crucial role in Reinforcement...