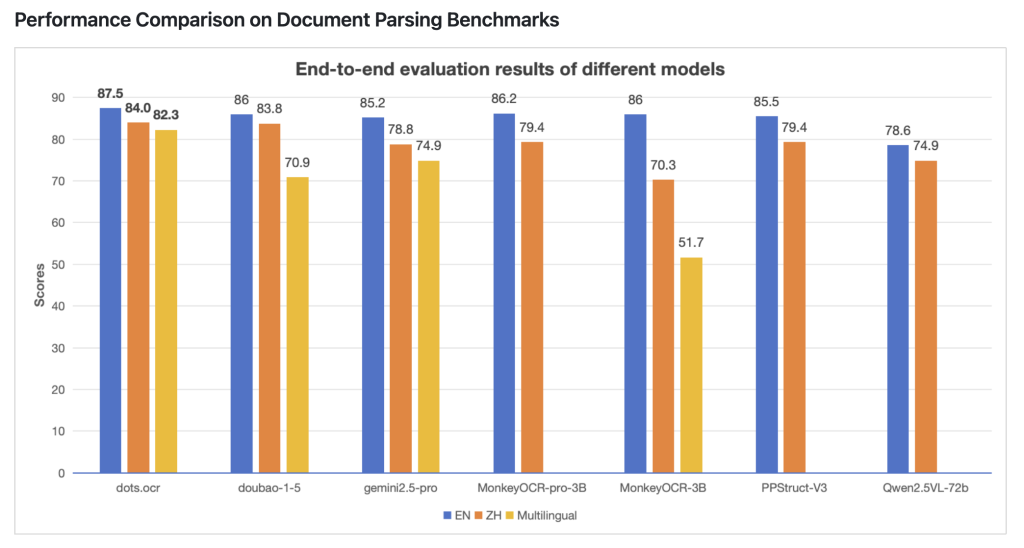
What is AI Inference? A Technical Deep Dive and Top 9 AI Inference Providers (2025 Edition)
Artificial Intelligence (AI) has evolved rapidly—especially in how models are deployed and operated in real-world systems. The core function that connects model training to practical applications is “inference”. This article offers a technical deep dive into AI inference as of 2025, covering its distinction from training, latency challenges for modern models, and optimization strategies such as quantization, pruning, and hardware acceleration. Inference vs. Training: The Critical Difference AI model deployment consists of two primary phases: Training is the process where a model learns patterns from massive, labeled datasets, using iterative algorithms (typically, backpropagation on neural networks). This phase is computation-heavy and generally done offline, leveraging accelerators like GPUs. Inference is the model’s “in action” phase—making predictions on new, unseen data. Here, the trained network is fed input, and the output is produced via a forward pass only. Inference happens in production environments, often requiring rapid responses and lower resource use. Aspect Training Inference Purpose Learn patterns, optimize weights Make predictions on new data Computation Heavy, iterative, uses backpropagation Lighter, forward pass only Time Sensitivity Offline, can take hours/days/weeks Real-time or near-real-time Hardware GPUs/TPUs, datacenter-scale CPUs, GPUs, FPGAs, edge devices Inference Latency: Challenges for 2025 Latency—the time from input to output—is one of the top technical challenges in deploying AI, especially large language models (LLMs) and real-time applications (autonomous vehicles, conversational bots, etc.). Key Sources of Latency Computational Complexity: Modern architectures—like transformers—have quadratic computational costs due to self-attention. (e.g., O ( n 2 d ) O(n 2 d) for sequence length n n and embedding dimension d d). Memory Bandwidth: Large models (with billions of parameters) require tremendous data movement, which often bottlenecks on memory speed and system I/O. Network Overhead: For cloud inference, network latency and bandwidth become critical—especially for distributed and edge deployments. Predictable vs. Unpredictable Latency: Some delays can be designed for (e.g., batch inference), while others—hardware contention, network jitter—cause unpredictable delays. Real-World Impact Latency directly affects user experience (voice assistants, fraud detection), system safety (driverless cars), and operational cost (cloud compute resources). As models grow, optimizing latency becomes increasingly complex and essential. Quantization: Lightening the Load Quantization reduces model size and computational requirements by lowering the numerical precision (e.g., converting 32-bit floats to 8-bit integers). How It Works: Quantization replaces high-precision parameters with lower-precision approximations, decreasing memory and compute needs. Types: Uniform/Non-uniform quantization Post-Training Quantization (PTQ) Quantization-Aware Training (QAT) Trade-offs: While quantization can dramatically speed up inference, it might slightly reduce model accuracy—careful application maintains performance within acceptable bounds. LLMs & Edge Devices: Especially valuable for LLMs and battery-powered devices, allowing for fast, low-cost inference. Pruning: Model Simplification Pruning is the process of removing redundant or non-essential model components—such as neural network weights or decision tree branches. Techniques: L1 Regularization: Penalizes large weights, shrinking less useful ones to zero. Magnitude Pruning: Removes lowest-magnitude weights or neurons. Taylor Expansion: Estimates the least impactful weights and prunes them. SVM Pruning: Reduces support vectors to simplify decision boundaries. Benefits: Lower memory. Faster inference. Reduced overfitting. Easier model deployment to resource-constrained environments. Risks: Aggressive pruning may degrade accuracy—balancing efficiency and accuracy is key. Hardware Acceleration: Speeding Up Inference Specialized hardware is transforming AI inference in 2025: GPUs: Offer massive parallelism, ideal for matrix and vector operations. NPUs (Neural Processing Units): Custom processors, optimized for neural network workloads. FPGAs (Field-Programmable Gate Arrays): Configurable chips for targeted, low-latency inference in embedded/edge devices. ASICs (Application-Specific Integrated Circuits): Purpose-built for highest efficiency and speed in large-scale deployments. Trends: Real-time, Energy-efficient Processing: Essential for autonomous systems, mobile devices, and IoT. Versatile Deployment: Hardware accelerators now span cloud servers to edge devices. Reduced Cost and Energy: Emerging accelerator architectures slash operational costs and carbon footprints. Here are the top 9 AI inference providers in 2025: Together AI Specializes in scalable LLM deployments, offering fast inference APIs and unique multi-model routing for hybrid cloud setups. Fireworks AI Renowned for ultra-fast multi-modal inference and privacy-oriented deployments, leveraging optimized hardware and proprietary engines for low latency. Hyperbolic Delivers serverless inference for generative AI, integrating automated scaling and cost optimization for high-volume workloads. Replicate Focuses on model hosting and deployment, allowing developers to run and share AI models rapidly in production with easy integrations. Hugging Face The go-to platform for transformer and LLM inference, providing robust APIs, customization options, and community-backed open-source models. Groq Known for custom Language Processing Unit (LPU) hardware that achieves unprecedented low-latency and high-throughput inference speeds for large models. DeepInfra Offers a dedicated cloud for high-performance inference, catering especially to startups and enterprise teams with customizable infrastructure. OpenRouter Aggregates multiple LLM engines, providing dynamic model routing and cost transparency for enterprise-grade inference orchestration. Lepton (Acquired by NVIDIA) Specializes in compliance-focused, secure AI inference with real-time monitoring and scalable edge/cloud deployment options. Conclusion Inference is where AI meets the real world, turning data-driven learning into actionable predictions. Its technical challenges—latency, resource constraints—are being met by innovations in quantization, pruning, and hardware acceleration. As AI models scale and diversify, mastering inference efficiency is the frontier for competitive, impactful deployment in 2025. Whether deploying conversational LLMs, real-time computer vision systems, or on-device diagnostics, understanding and optimizing inference will be central for technologists and enterprises aiming to lead in the AI era. The post What is AI Inference? A Technical Deep Dive and Top 9 AI Inference Providers (2025 Edition) appeared first on MarkTechPost.