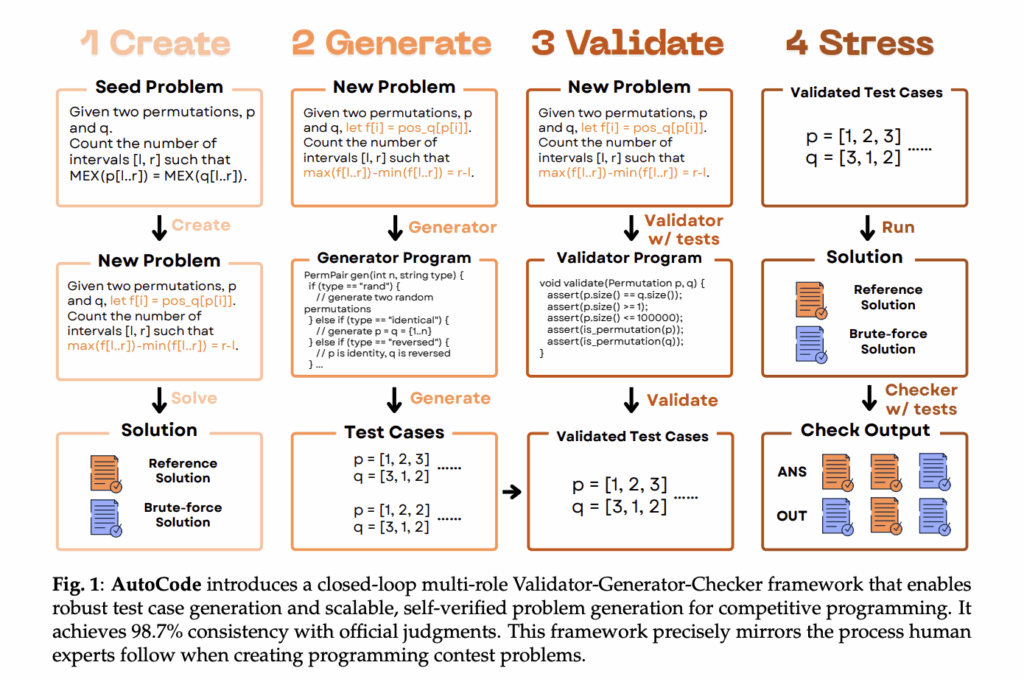
Are your LLM code benchmarks actually rejecting wrong-complexity solutions and interactive-protocol violations, or are they passing under-specified unit tests? A team of researchers from UCSD, NYU, University of Washington, Princeton University, Canyon Crest Academy, OpenAI, UC Berkeley, MIT, University of Waterloo, and Sentient Labs introduce AutoCode, a new AI framework that lets LLMs create and verify competitive programming problems, mirroring the workflow of human problem setters. AutoCode reframes evaluation for code-reasoning models by treating problem setting (not only problem solving) as the target task. The system trains LLMs to produce competition-grade statements, test data, and verdict logic that match official online judges at high rates. On a 7,538-problem benchmark built from prior datasets, AutoCode achieves 91.1% consistency with official judgments (FPR 3.7%, FNR 14.1%). On a separate, more difficult 720 recent Codeforces problems (including interactive tasks), the full framework reports 98.7% consistency, 1.3% FPR, 1.2% FNR. https://arxiv.org/pdf/2510.12803 Why problem setting matters for evaluation? Public code benchmarks often rely on under-specified tests that let wrong-complexity or shortcut solutions pass. That inflates scores and pollutes reinforcement signals (rewarding fragile tactics). AutoCode’s validator-first approach and adversarial test generation aim to reduce false positives (FPR)—incorrect programs that pass—and false negatives (FNR)—correct programs rejected due to malformed inputs. https://arxiv.org/pdf/2510.12803 The core loop: Validator → Generator → Checker AutoCode runs a closed loop that mirrors human contest workflows, but each step is selected from LLM-generated candidates using targeted in-framework tests. 1) Validator (minimize FNR by enforcing input legality) The system first asks an LLM to synthesize 40 evaluation inputs—10 valid and 30 near-valid illegal (e.g., off-by-one boundary violations). It then prompts the LLM for three candidate validator programs and selects the one that best classifies these cases. This prevents “correct” solutions from crashing on malformed data. https://arxiv.org/pdf/2510.12803 2) Generator (reduce FPR by adversarial coverage) Three complementary strategies produce test cases:• Small-data exhaustion for boundary coverage,• Randomized + extreme cases (overflows, precision, hash-collisions),• TLE-inducing structures to break wrong-complexity solutions. Invalid cases are filtered by the selected validator; then cases are deduplicated and bucket-balanced before sampling. https://arxiv.org/pdf/2510.12803 3) Checker (verdict logic) The checker compares contestant outputs with the reference solution under complex rules. AutoCode again generates 40 checker scenarios and three candidate checker programs, keeps only scenarios with validator-approved inputs, and selects the best checker by accuracy against the 40 labeled scenarios. https://arxiv.org/pdf/2510.12803 4) Interactor (for interactive problems) For tasks that require dialogue with the judge, AutoCode introduces a mutant-based interactor: it makes small logical edits (“mutants”) to the reference solution, selects interactors that accept the true solution but reject the mutants, maximizing discrimination. This addresses a gap in earlier public datasets that avoided interactives. https://arxiv.org/pdf/2510.12803 Dual verification enables new problems (not just tests for existing ones) AutoCode can generate novel problem variants starting from a random “seed” Codeforces problem (<2200 Elo). The LLM drafts a new statement and two solutions: an efficient reference and a simpler brute-force baseline. A problem is accepted only if the reference output matches brute force across the generated test suite (the brute force may TLE on large cases but serves as ground truth on small/exhaustive cases). This dual-verification protocol filters ~27% of error-prone items, lifting reference-solution correctness from 86% → 94% before human review. Human experts then grade the survivors on solvability, solution correctness, quality, novelty, difficulty. After filtering, 61.6% are usable for model training, 76.3% for human training, and 3.2% are ICPC/IOI-level problems. Difficulty typically increases relative to the seed, and difficulty gain correlates with perceived quality. https://arxiv.org/pdf/2510.12803 Understanding the results Existing problems (7,538 total; 195,988 human submissions). AutoCode: 91.1% consistency, 3.7% FPR, 14.1% FNR, vs 72.9–81.0% consistency for prior generators (CodeContests, CodeContests+, TACO, HardTests). Recent Codeforces problems (720, unfiltered; includes interactives). AutoCode: 98.7% consistency, 1.3% FPR, 1.2% FNR. Ablations show all three generator strategies and prompt optimization contribute: removing prompt optimization drops consistency to 98.0% and more than doubles FNR to 2.9%. https://arxiv.org/pdf/2510.12803 Key Takeaways AutoCode couples a Validator–Generator–Checker (+Interactor) loop with dual verification (reference vs. brute-force) to build contest-grade test suites and new problems. On held-out problems, AutoCode’s test suites reach ~99% consistency with official judges, surpassing prior generators like HardTests (<81%). For recent Codeforces tasks (including interactives), the full framework reports ~98.7% consistency with ~1.3% FPR and ~1.2% FNR. The mutant-based interactor reliably accepts the true solution while rejecting mutated variants, improving evaluation for interactive problems. Human experts rate a sizable fraction of AutoCode-generated items as training-usable and a non-trivial share as contest-quality, aligning with the LiveCodeBench Pro program’s aims. Editorial Comments AutoCode is a practical fix for current code benchmarks. It centers problem setting and uses a closed-loop Validator–Generator–Checker (+Interactor) pipeline with dual verification (reference vs. brute-force). This structure reduces false positives/negatives and yields judge-aligned consistency (≈99% on held-out problems; 98.7% on recent Codeforces, including interactives). The approach standardizes constraint legality, adversarial coverage, and protocol-aware judging, which makes downstream RL reward signals cleaner. Its placement under LiveCodeBench Pro fits a hallucination-resistant evaluation program that emphasizes expert-checked rigor. Check out the Paper and Project. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post AutoCode: A New AI Framework that Lets LLMs Create and Verify Competitive Programming Problems, Mirroring the Workflow of Human Problem Setters appeared first on MarkTechPost.