

RaDialog: A Large Vision-Language Model for Radiology Report Generation and Conversational Assistance
arXiv:2311.18681v3 Announce Type: replace-cross Abstract: Conversational AI tools that can generate and discuss clinically correct...

RA3: Mid-Training with Temporal Action Abstractions for Faster Reinforcement Learning (RL) Post-Training in Code LLMs
TL;DR: A new research from Apple, formalizes what “mid-training” should do before reinforcement learning RL...
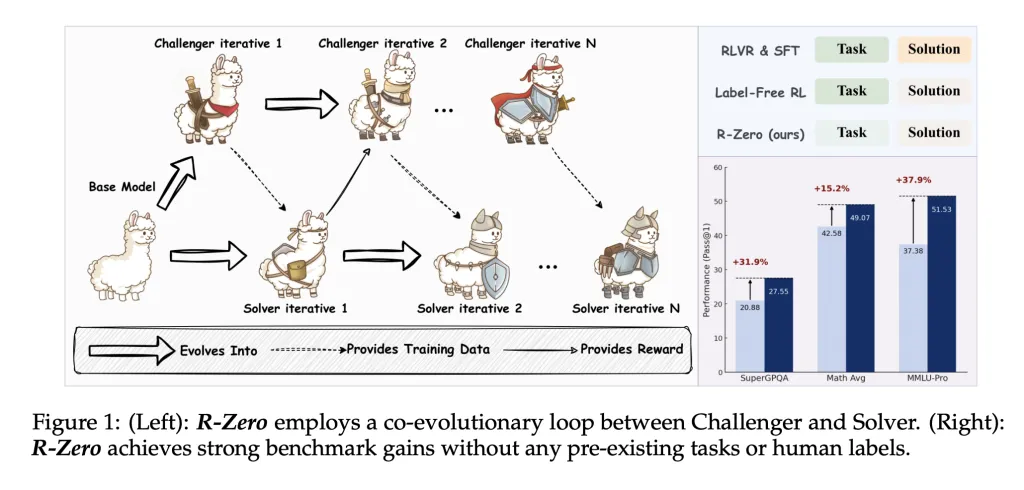
R-Zero: A Fully Autonomous AI Framework that Generates Its Own Training Data from Scratch
Large Language Models (LLMs) have revolutionized fields from natural language understanding to reasoning and code...

QwenLong-L1 solves long-context reasoning challenge that stumps current LLMs
Alibaba’s QwenLong-L1 helps LLMs deeply understand long documents, unlocking advanced reasoning for practical enterprise applications.Read...
Qwen3-ASR-Toolkit: An Advanced Open Source Python Command-Line Toolkit for Using the Qwen-ASR API Beyond the 3 Minutes/10 MB Limit
Qwen has released Qwen3-ASR-Toolkit, an MIT-licensed Python CLI that programmatically bypasses the Qwen3-ASR-Flash API’s 3-minute/10...
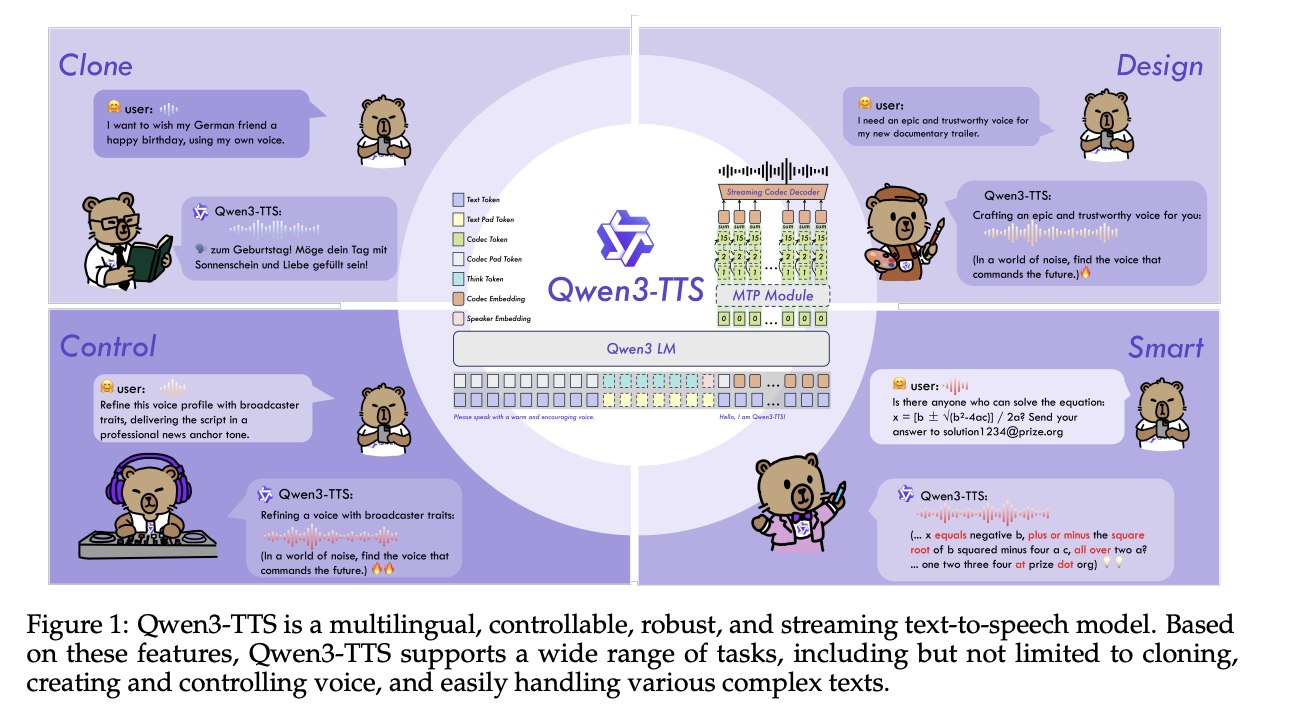
Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target...
Quiet Feature Learning in Algorithmic Tasks
arXiv:2505.03997v1 Announce Type: cross Abstract: We train Transformer-based language models on ten foundational algorithmic tasks...
Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models
arXiv:2503.22879v3 Announce Type: replace-cross Abstract: State Space Models (SSMs) are emerging as a compelling alternative...
QFFT, Question-Free Fine-Tuning for Adaptive Reasoning
arXiv:2506.12860v1 Announce Type: new Abstract: Recent advancements in Long Chain-of-Thought (CoT) reasoning models have improved...

QeRL: NVFP4-Quantized Reinforcement Learning (RL) Brings 32B LLM Training to a Single H100—While Improving Exploration
What would you build if you could run Reinforcement Learning (RL) post-training on a 32B...
QE4PE: Word-level Quality Estimation for Human Post-Editing
arXiv:2503.03044v2 Announce Type: replace Abstract: Word-level quality estimation (QE) methods aim to detect erroneous spans...
PyLate: Flexible Training and Retrieval for Late Interaction Models
arXiv:2508.03555v1 Announce Type: cross Abstract: Neural ranking has become a cornerstone of modern information retrieval...