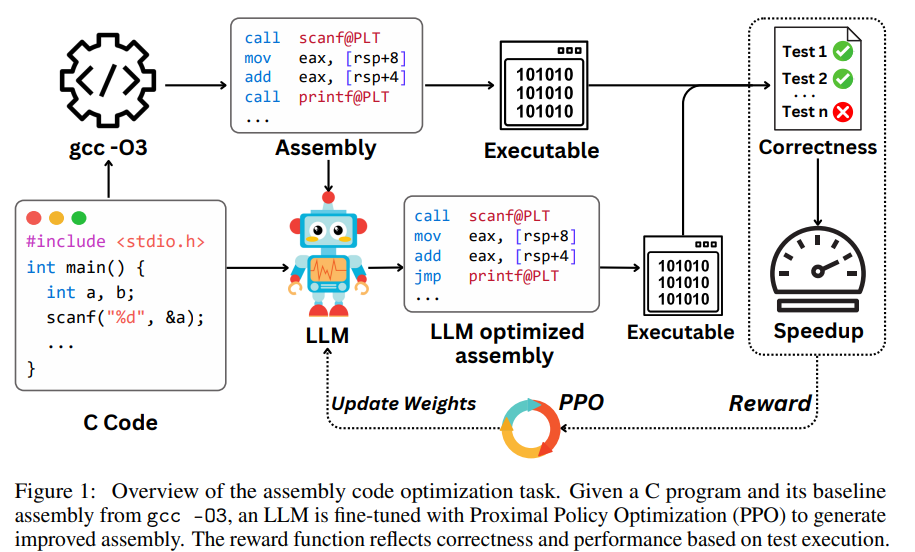
LLMs have shown impressive capabilities across various programming tasks, yet their potential for program optimization has not been fully explored. While some recent efforts have used LLMs to enhance performance in languages like C++ and Python, the broader application of LLMs to optimize code, especially in low-level programming contexts, remains limited. Existing LLM benchmarks largely focus on code generation from natural language or solving GitHub issues, as seen in HumanEval, MBPP, APPS, SWE-bench, and SWE-agent. Moreover, models such as Codex, AlphaCode, and Code Llama primarily aim to improve code generation quality rather than performance. However, select research has begun addressing optimization, including parallelization and code efficiency improvements, though many of these approaches are constrained by the need for formal verification, limiting scalability. In contrast, some newer methods embrace test-based validation, allowing optimization of more complex programs with loops. Learning-based strategies in compiler optimization—like AutoPhase, which uses reinforcement learning for pass sequencing, and Coreset, which applies graph neural networks—have shown promise in improving performance. Superoptimization techniques aim to find the most efficient version of a program but are typically restricted to small-scale problems. Additionally, frameworks like AutoTVM and Ansor have focused on optimizing GPU kernel code through statistical modeling and search. Recently, LLM-driven optimization has gained attention, with reinforcement learning approaches guiding LLMs using feedback from test cases. Techniques like CodeRL and PPOCoder leverage policy optimization methods to fine-tune models for better performance, even across resource-constrained programming languages like Verilog. Stanford, UIUC, CMU, and Visa Research researchers explore using LLMs to optimize assembly code performance—an area traditionally handled by compilers like GCC. They introduce a reinforcement learning framework using Proximal Policy Optimization (PPO), guided by a reward balancing correctness and speedup over the gcc -O3 baseline. Using a dataset of 8,072 real-world programs, their model, Qwen2.5-Coder-7B-PPO, achieves a 96.0% test pass rate and a 1.47× average speedup, outperforming 20 other models, including Claude-3.7-sonnet. Their results show that with RL training, LLMs can effectively outperform conventional compiler optimizations. The methodology involves optimizing compiled C programs for performance using an RL approach. Given a C program C, it is compiled to assembly P using gcc -O3. The goal is to generate a new assembly program P’ that is functionally equivalent but faster. Correctness is verified using a test set, and speedup is measured by execution time improvement. Using CodeNet as the dataset, the authors apply PPO to train a language model that generates improved code. Two reward functions—Correctness-Guided Speedup and Speedup-Only—are used to guide training based on program validity, correctness, and performance gains. The study evaluates various language models on optimizing assembly code, revealing that most models struggle with low test pass rates and minimal speedups. However, Qwen2.5-Coder-7B-PPO, trained with reinforcement learning, significantly outperforms others, achieving 96% accuracy and a 1.47× average speedup. Ablation studies show that using gcc -O3 as a reference aids performance, while removing it leads to sharp declines. Notably, models like Claude-3.7-sonnet can surpass compilers by identifying hardware-specific optimizations, such as replacing loops with a single popcnt instruction, demonstrating their ability to perform semantic-level code transformations beyond traditional compiler capabilities. In conclusion, the study explores using LLMs to optimize assembly code, a domain where traditional compilers struggle due to the complexity of low-level performance tuning. The authors fine-tune Qwen2.5-Coder-7B using PPO, rewarding both correctness (via test cases) and speedup over gcc -O3. They introduce a benchmark of 8,072 real-world C programs to evaluate performance. The model achieves a 96.0% test pass rate and a 1.47× average speedup, outperforming 20 other models, including Claude-3.7-sonnet. While effective, limitations include a lack of formal correctness guarantees and variability in hardware performance across systems. Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter. The post Optimizing Assembly Code with LLMs: Reinforcement Learning Outperforms Traditional Compilers appeared first on MarkTechPost.