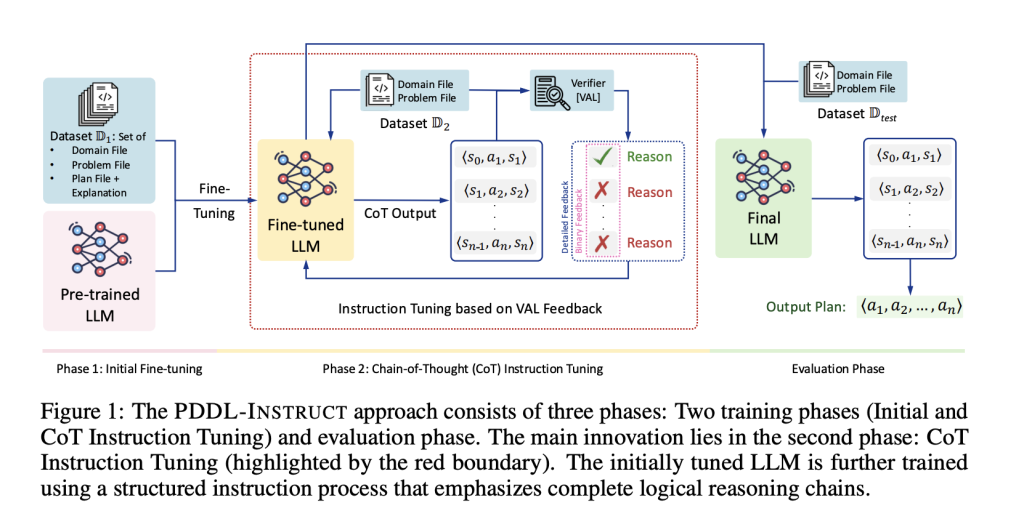
What exactly is being measured when a judge LLM assigns a 1–5 (or pairwise) score? Most “correctness/faithfulness/completeness” rubrics are project-specific. Without task-grounded definitions, a scalar score can drift from business outcomes (e.g., “useful marketing post” vs. “high completeness”). Surveys of LLM-as-a-judge (LAJ) note that rubric ambiguity and prompt template choices materially shift scores and human correlations. How stable are judge decisions to prompt position and formatting? Large controlled studies find position bias: identical candidates receive different preferences depending on order; list-wise and pairwise setups both show measurable drift (e.g., repetition stability, position consistency, preference fairness). Work cataloging verbosity bias shows longer responses are often favored independent of quality; several reports also describe self-preference (judges prefer text closer to their own style/policy). Do judge scores consistently match human judgments of factuality? Empirical results are mixed. For summary factuality, one study reported low or inconsistent correlations with humans for strong models (GPT-4, PaLM-2), with only partial signal from GPT-3.5 on certain error types. Conversely, domain-bounded setups (e.g., explanation quality for recommenders) have reported usable agreement with careful prompt design and ensembling across heterogeneous judges. Taken together, correlation seems task- and setup-dependent, not a general guarantee. How robust are judge LLMs to strategic manipulation? LLM-as-a-Judge (LAJ) pipelines are attackable. Studies show universal and transferable prompt attacks can inflate assessment scores; defenses (template hardening, sanitization, re-tokenization filters) mitigate but do not eliminate susceptibility. Newer evaluations differentiate content-author vs. system-prompt attacks and document degradation across several families (Gemma, Llama, GPT-4, Claude) under controlled perturbations. Is pairwise preference safer than absolute scoring? Preference learning often favors pairwise ranking, yet recent research finds protocol choice itself introduces artifacts: pairwise judges can be more vulnerable to distractors that generator models learn to exploit; absolute (pointwise) scores avoid order bias but suffer scale drift. Reliability therefore hinges on protocol, randomization, and controls rather than a single universally superior scheme. Could “judging” encourage overconfident model behavior? Recent reporting on evaluation incentives argues that test-centric scoring can reward guessing and penalize abstention, shaping models toward confident hallucinations; proposals suggest scoring schemes that explicitly value calibrated uncertainty. While this is a training-time concern, it feeds back into how evaluations are designed and interpreted. Where do generic “judge” scores fall short for production systems? When an application has deterministic sub-steps (retrieval, routing, ranking), component metrics offer crisp targets and regression tests. Common retrieval metrics include Precision@k, Recall@k, MRR, and nDCG; these are well-defined, auditable, and comparable across runs. Industry guides emphasize separating retrieval and generation and aligning subsystem metrics with end goals, independent of any judge LLM. If judge LLMs are fragile, what does “evaluation” look like in the wild? Public engineering playbooks increasingly describe trace-first, outcome-linked evaluation: capture end-to-end traces (inputs, retrieved chunks, tool calls, prompts, responses) using OpenTelemetry GenAI semantic conventions and attach explicit outcome labels (resolved/unresolved, complaint/no-complaint). This supports longitudinal analysis, controlled experiments, and error clustering—regardless of whether any judge model is used for triage. Tooling ecosystems (e.g., LangSmith and others) document trace/eval wiring and OTel interoperability; these are descriptions of current practice rather than endorsements of a particular vendor. Are there domains where LLM-as-a-Judge (LAJ) seems comparatively reliable? Some constrained tasks with tight rubrics and short outputs report better reproducibility, especially when ensembles of judges and human-anchored calibration sets are used. But cross-domain generalization remains limited, and bias/attack vectors persist. Does LLM-as-a-Judge (LAJ) performance drift with content style, domain, or “polish”? Beyond length and order, studies and news coverage indicate LLMs sometimes over-simplify or over-generalize scientific claims compared to domain experts—useful context when using LAJ to score technical material or safety-critical text. Key Technical Observations Biases are measurable (position, verbosity, self-preference) and can materially change rankings without content changes. Controls (randomization, de-biasing templates) reduce but do not eliminate effects. Adversarial pressure matters: prompt-level attacks can systematically inflate scores; current defenses are partial. Human agreement varies by task: factuality and long-form quality show mixed correlations; narrow domains with careful design and ensembling fare better. Component metrics remain well-posed for deterministic steps (retrieval/routing), enabling precise regression tracking independent of judge LLMs. Trace-based online evaluation described in industry literature (OTel GenAI) supports outcome-linked monitoring and experimentation. Summary In conclusion, this article does not argue against the existence of LLM-as-a-Judge but highlights the nuances, limitations, and ongoing debates around its reliability and robustness. The intention is not to dismiss its use but to frame open questions that need further exploration. Companies and research groups actively developing or deploying LLM-as-a-Judge (LAJ) pipelines are invited to share their perspectives, empirical findings, and mitigation strategies—adding valuable depth and balance to the broader conversation on evaluation in the GenAI era. The post LLM-as-a-Judge: Where Do Its Signals Break, When Do They Hold, and What Should “Evaluation” Mean? appeared first on MarkTechPost.