

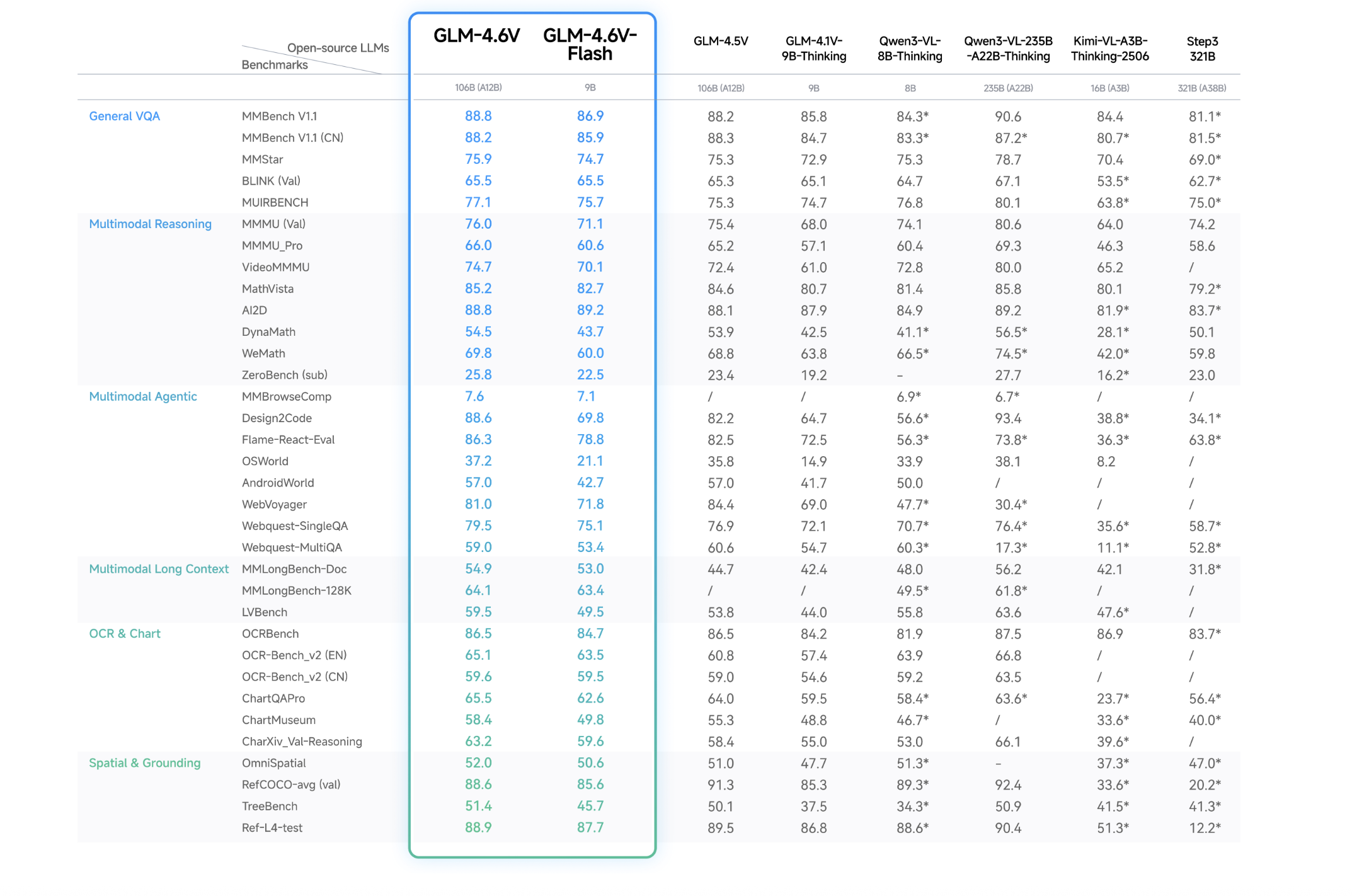
Zhipu AI Releases GLM-4.6V: A 128K Context Vision Language Model with Native Tool Calling
Zhipu AI has open sourced the GLM-4.6V series as a pair of vision language models...
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
arXiv:2505.04588v1 Announce Type: new Abstract: Effective information searching is essential for enhancing the reasoning and...
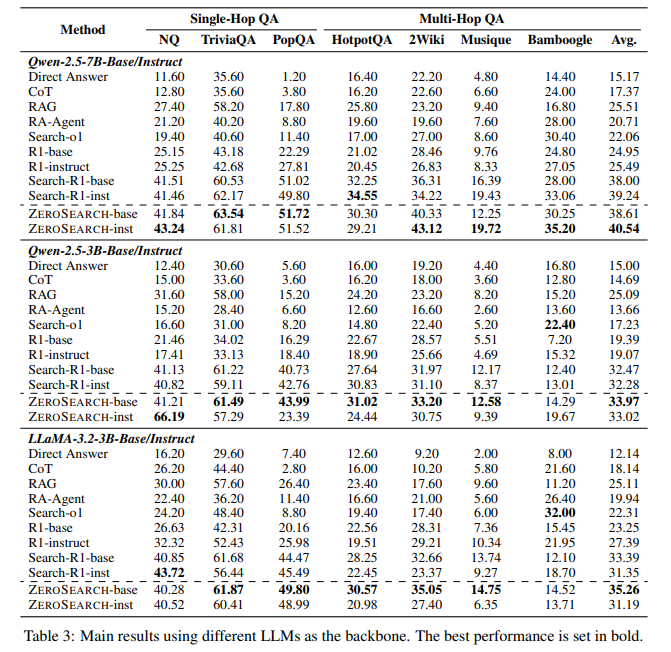
ZeroSearch from Alibaba Uses Reinforcement Learning and Simulated Documents to Teach LLMs Retrieval Without Real-Time Search
Large language models are now central to various applications, from coding to academic tutoring and...
Zero-Shot Tokenizer Transfer
arXiv:2405.07883v2 Announce Type: replace Abstract: Language models (LMs) are bound to their tokenizer, which maps...
Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning
arXiv:2507.16746v2 Announce Type: replace-cross Abstract: Humans often use visual aids, for example diagrams or sketches...

Your AI models are failing in production—Here’s how to fix model selection
The Allen Institute of AI updated its reward model evaluation RewardBench to better reflect real-life...
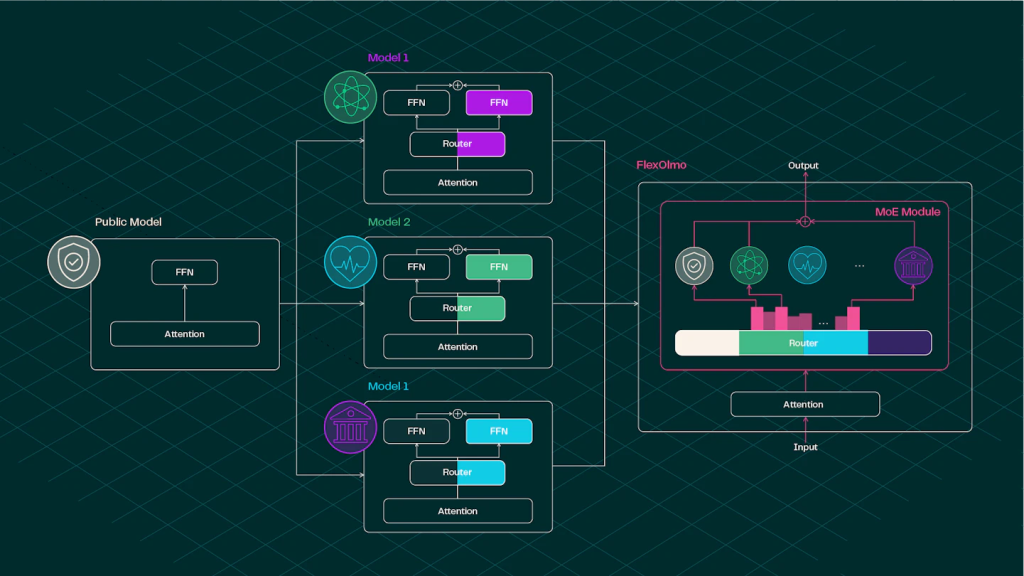
You Don’t Need to Share Data to Train a Language Model Anymore—FlexOlmo Demonstrates How
The development of large-scale language models (LLMs) has historically required centralized access to extensive datasets...

You can now fine-tune your enterprise’s own version of OpenAI’s o4-mini reasoning model with reinforcement learning
For organizations with clearly defined problems and verifiable answers, RFT offers a compelling way to...
Yann LeCun’s new venture is a contrarian bet against large language models
Yann LeCun is a Turing Award recipient and a top AI researcher, but he has...
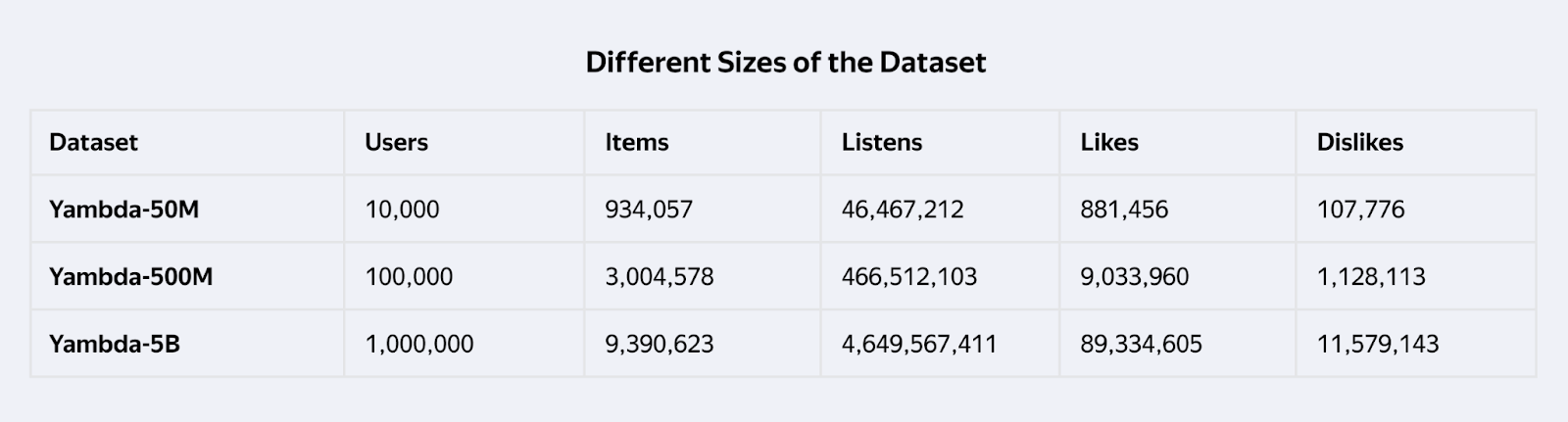
Yandex Releases Yambda: The World’s Largest Event Dataset to Accelerate Recommender Systems
Yandex has recently made a significant contribution to the recommender systems community by releasing Yambda...
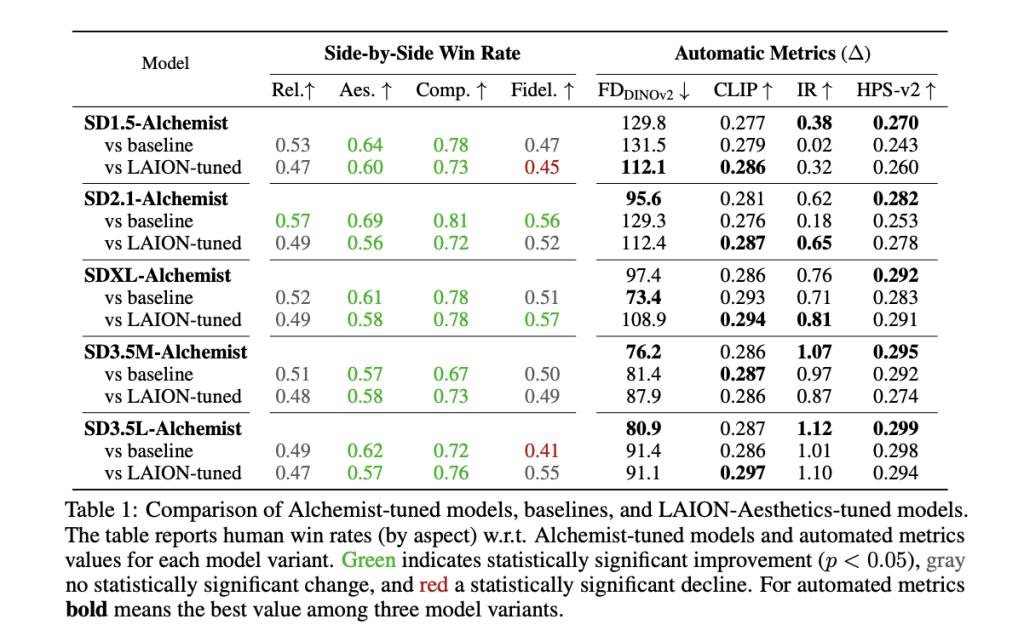
Yandex Releases Alchemist: A Compact Supervised Fine-Tuning Dataset for Enhancing Text-to-Image T2I Model Quality
Despite the substantial progress in text-to-image (T2I) generation brought about by models such as DALL-E...
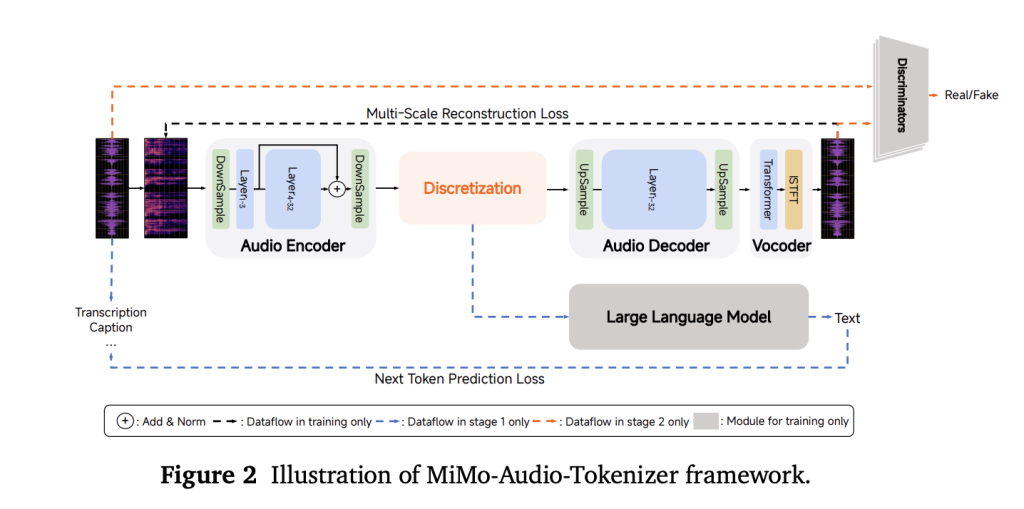
Xiaomi Released MiMo-Audio, a 7B Speech Language Model Trained on 100M+ Hours with High-Fidelity Discrete Tokens
Xiaomi’s MiMo team released MiMo-Audio, a 7-billion-parameter audio-language model that runs a single next-token objective...