

Xiaomi MiMo and TileRT Push a 1-Trillion-Parameter Model Past 1000 Tokens Per Second on Commodity GPUs
Inference speed is becoming a competitive metric for large language models. Xiaomi’s MiMo team just...
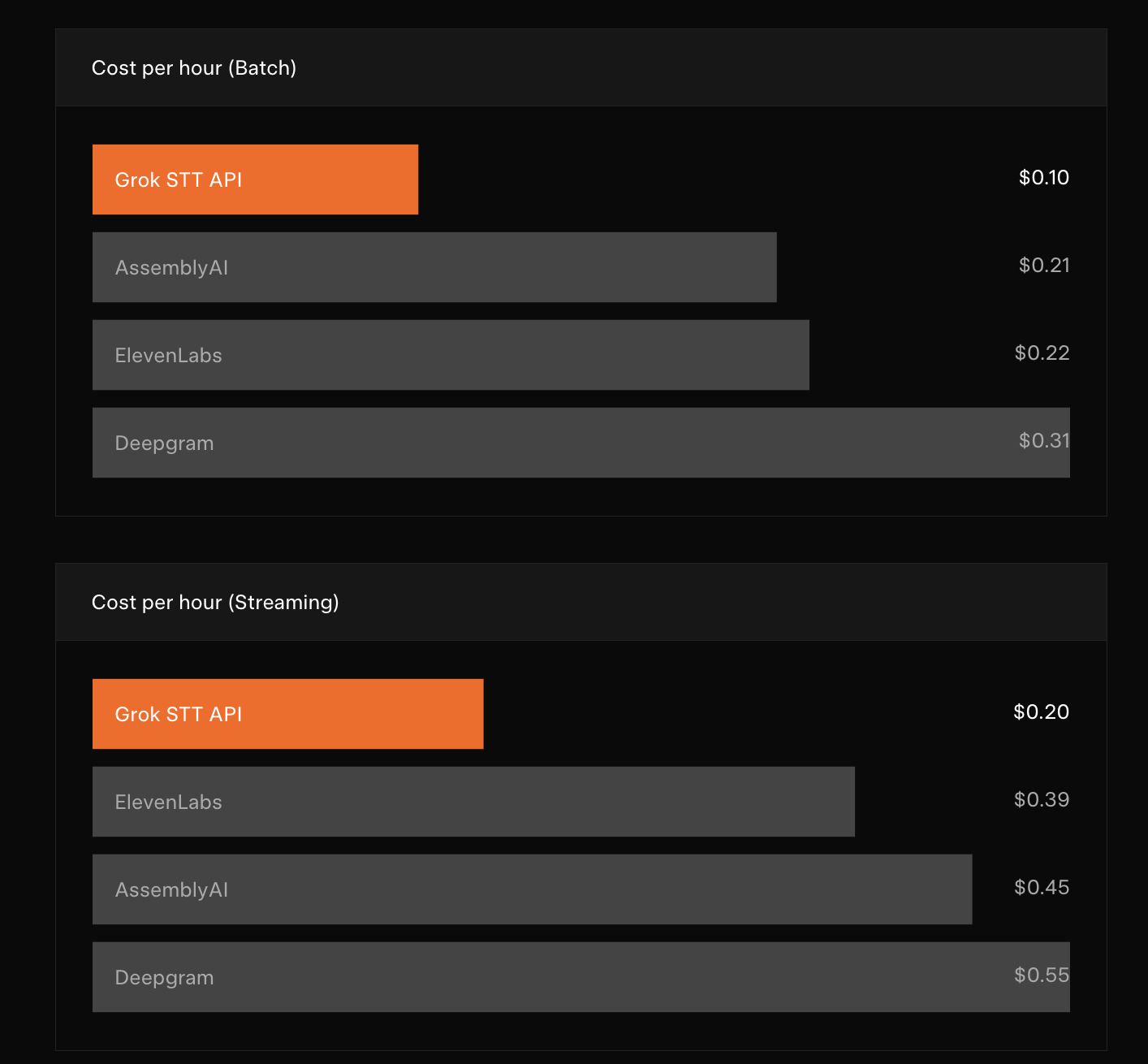
xAI Launches Standalone Grok Speech-to-Text and Text-to-Speech APIs, Targeting Enterprise Voice Developers
Elon Musk’s AI company xAI has launched two standalone audio APIs — a Speech-to-Text (STT)...
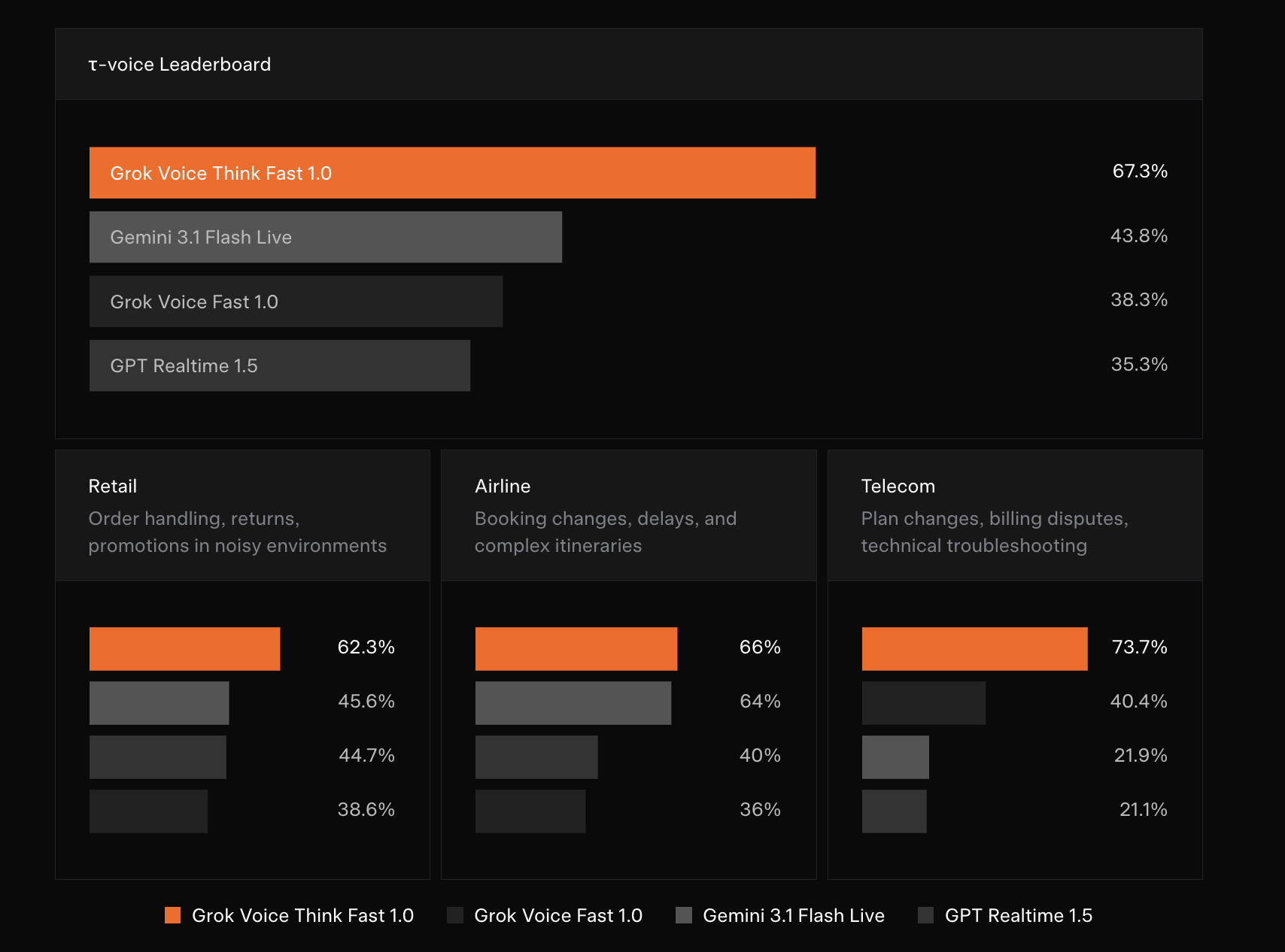
xAI Launches grok-voice-think-fast-1.0: Topping τ-voice Bench at 67.3%, Outperforming Gemini, GPT Realtime, and More
Building a production-grade voice AI agent is one of the hardest engineering challenges in applied...
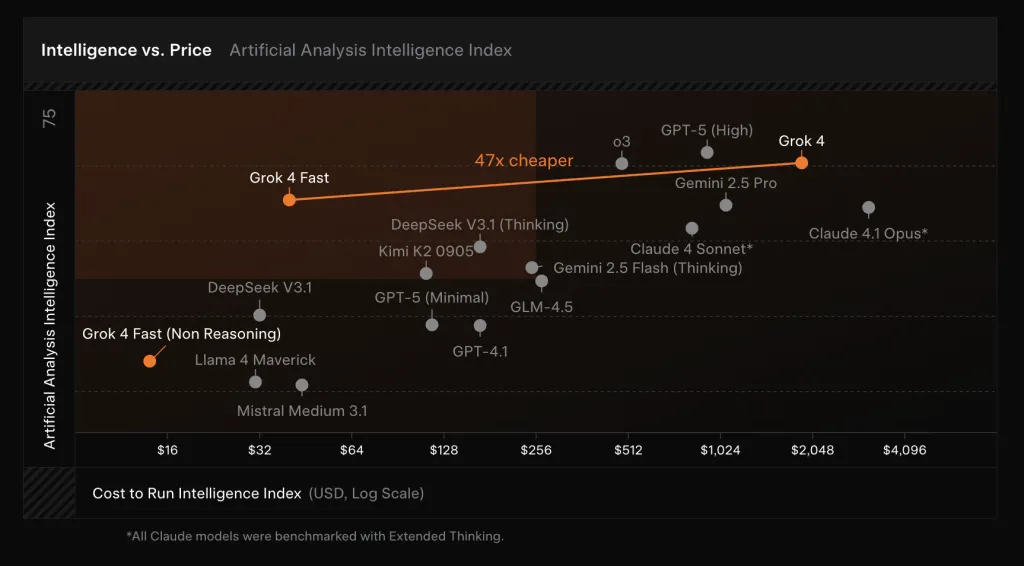
xAI launches Grok-4-Fast: Unified Reasoning and Non-Reasoning Model with 2M-Token Context and Trained End-to-End with Tool-Use Reinforcement Learning (RL)
xAI introduced Grok-4-Fast, a cost-optimized successor to Grok-4 that merges “reasoning” and “non-reasoning” behaviors into...
Wrist Photoplethysmography Predicts Dietary Information
arXiv:2511.19260v2 Announce Type: replace-cross Abstract: Whether wearable photoplethysmography (PPG) contains dietary information remains unknown. We...
WorkOS Releases auth.md: An Open Agent Registration Protocol Built on OAuth Standards
For years, authentication on the web followed one design assumption: a human sits behind a...
Wisdom and Delusion of LLM Ensembles for Code Generation and Repair
arXiv:2510.21513v1 Announce Type: cross Abstract: Today’s pursuit of a single Large Language Model (LMM) for...
Will fusion power get cheap? Don’t count on it.
Fusion power could provide a steady, zero-emissions source of electricity in the future—if companies can...

Why worms (and microbes) are catching on as a manure pollution solution
Anthony Agueda, a third-generation California dairy farmer, pulls a rake through a bed of dark...

Why this year’s World Cup ball may not fly as far
Much is new about this month’s upcoming FIFA World Cup tournament, which will be held...
Why They Disagree: Decoding Differences in Opinions about AI Risk on the Lex Fridman Podcast
arXiv:2512.06350v1 Announce Type: cross Abstract: The emergence of transformative technologies often surfaces deep societal divisions...
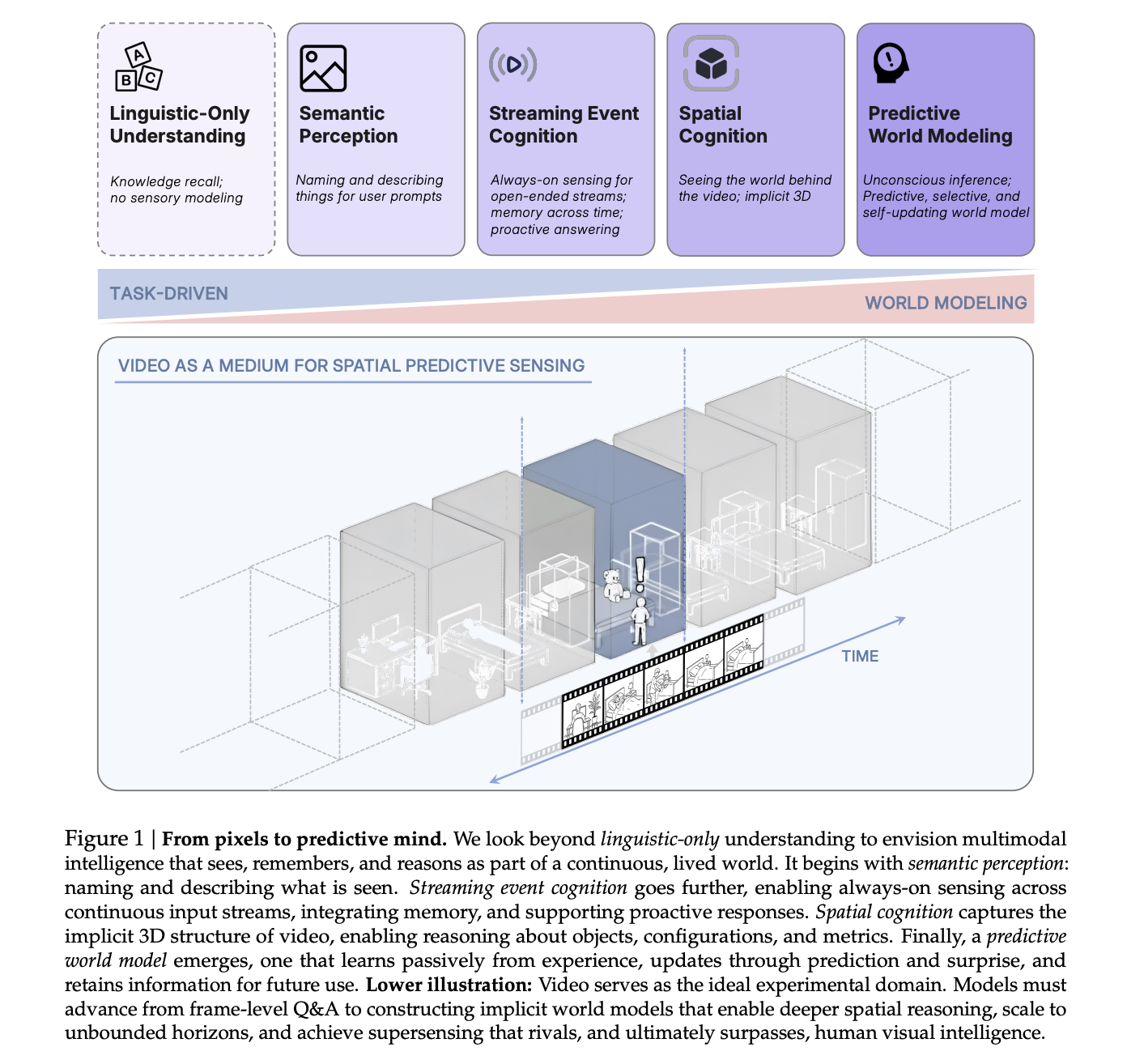
Why Spatial Supersensing is Emerging as the Core Capability for Multimodal AI Systems?
Even strong ‘long-context’ AI models fail badly when they must track objects and counts over...