Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency
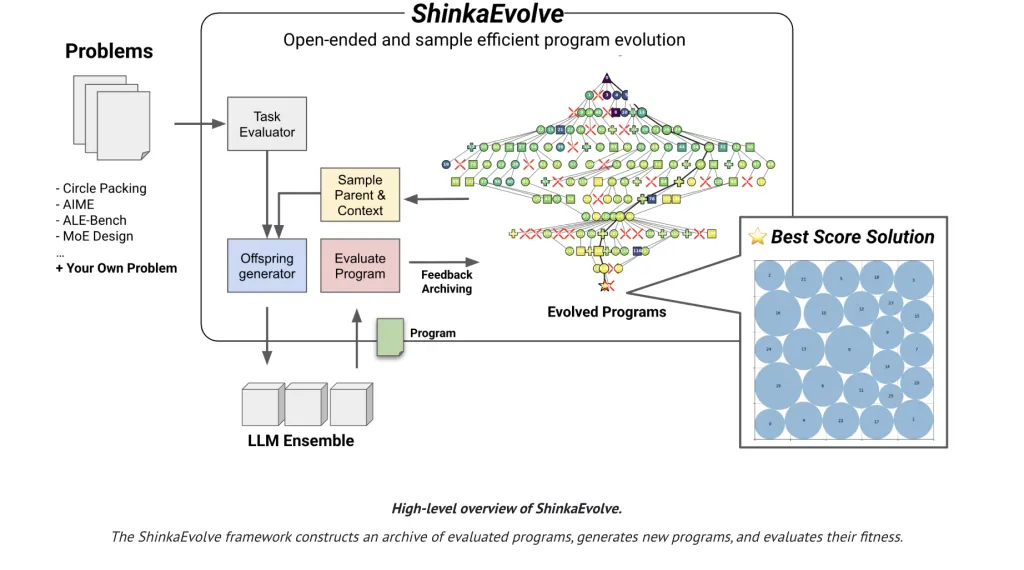
Table of contents What problem is it actually solving? Does the sample-efficiency claim hold beyond toy problems? How does the evolutionary loop look in practice? What are the concrete results? How does this compare to AlphaEvolve and related systems? Summary FAQs — ShinkaEvolve Sakana AI has released ShinkaEvolve, an open-sourced framework that uses large language models (LLMs) as mutation operators in an evolutionary loop to evolve programs for scientific and engineering problems—while drastically cutting the number of evaluations needed to reach strong solutions. On the canonical circle-packing benchmark (n=26 in a unit square), ShinkaEvolve reports a new SOTA configuration using ~150 program evaluations, where prior systems typically burned thousands. The project ships under Apache-2.0, with a research report and public code. https://sakana.ai/shinka-evolve/ What problem is it actually solving? Most “agentic” code-evolution systems explore by brute force: they mutate code, run it, score it, and repeat—consuming enormous sampling budgets. ShinkaEvolve targets that waste explicitly with three interacting components: Adaptive parent sampling to balance exploration/exploitation. Parents are drawn from “islands” via fitness- and novelty-aware policies (power-law or weighted by performance and offspring counts) rather than always climbing the current best. Novelty-based rejection filtering to avoid re-evaluating near-duplicates. Mutable code segments are embedded; if cosine similarity exceeds a threshold, a secondary LLM acts as a “novelty judge” before execution. Bandit-based LLM ensembling so the system learns which model (e.g., GPT/Gemini/Claude/DeepSeek families) is yielding the biggest relative fitness jumps and routes future mutations accordingly (UCB1-style update on improvement over parent/baseline). Does the sample-efficiency claim hold beyond toy problems? The research team evaluates four distinct domains and shows consistent gains with small budgets: Circle packing (n=26): reaches an improved configuration in roughly 150 evaluations; the research team also validate with stricter exact-constraint checking. AIME math reasoning (2024 set): evolves agentic scaffolds that trace out a Pareto frontier (accuracy vs. LLM-call budget), outperforming hand-built baselines under limited query budgets / Pareto frontier of accuracy vs. calls and transferring to other AIME years and LLMs. Competitive programming (ALE-Bench LITE): starting from ALE-Agent solutions, ShinkaEvolve delivers ~2.3% mean improvement across 10 tasks and pushes one task’s solution from 5th → 2nd in an AtCoder leaderboard counterfactual. LLM training (Mixture-of-Experts): evolves a new load-balancing loss that improves perplexity and downstream accuracy at multiple regularization strengths vs. the widely-used global-batch LBL. https://sakana.ai/shinka-evolve/ How does the evolutionary loop look in practice? ShinkaEvolve maintains an archive of evaluated programs with fitness, public metrics, and textual feedback. For each generation: sample an island and parent(s); construct a mutation context with top-K and random “inspiration” programs; then propose edits via three operators—diff edits, full rewrites, and LLM-guided crossovers—while protecting immutable code regions with explicit markers. Executed candidates update both the archive and the bandit statistics that steer subsequent LLM/model selection. The system periodically produces a meta-scratchpad that summarizes recently successful strategies; those summaries are fed back into prompts to accelerate later generations. What are the concrete results? Circle packing: combined structured initialization (e.g., golden-angle patterns), hybrid global–local search (simulated annealing + SLSQP), and escape mechanisms (temperature reheating, ring rotations) discovered by the system—not hand-coded a priori. AIME scaffolds: three-stage expert ensemble (generation → critical peer review → synthesis) that hits the accuracy/cost sweet spot at ~7 calls while retaining robustness when swapped to different LLM backends. ALE-Bench: targeted engineering wins (e.g., caching kd-tree subtree stats; “targeted edge moves” toward misclassified items) that push scores without wholesale rewrites. MoE loss: adds an entropy-modulated under-use penalty to the global-batch objective; empirically reduces miss-routing and improves perplexity/benchmarks as layer routing concentrates. How does this compare to AlphaEvolve and related systems? AlphaEvolve demonstrated strong closed-source results but at higher evaluation counts. ShinkaEvolve reproduces and surpasses the circle-packing result with orders-of-magnitude fewer samples and releases all components open-source. The research team also contrast variants (single-model vs. fixed ensemble vs. bandit ensemble) and ablate parent selection and novelty filtering, showing each contributes to the observed efficiency. Summary ShinkaEvolve is an Apache-2.0 framework for LLM-driven program evolution that cuts evaluations from thousands to hundreds by combining fitness/novelty-aware parent sampling, embedding-plus-LLM novelty rejection, and a UCB1-style adaptive LLM ensemble. It sets a new SOTA on circle packing (~150 evals), finds stronger AIME scaffolds under strict query budgets, improves ALE-Bench solutions (~2.3% mean gain, 5th→2nd on one task), and discovers a new MoE load-balancing loss that improves perplexity and downstream accuracy. Code and report are public. FAQs — ShinkaEvolve 1) What is ShinkaEvolve?An open-source framework that couples LLM-driven program mutations with evolutionary search to automate algorithm discovery and optimization. Code and report are public. 2) How does it achieve higher sample-efficiency than prior evolutionary systems?Three mechanisms: adaptive parent sampling (explore/exploit balance), novelty-based rejection to avoid duplicate evaluations, and a bandit-based selector that routes mutations to the most promising LLMs. 3) What supports the results?It reaches state-of-the-art circle packing with ~150 evaluations; on AIME-2024 it evolves scaffolds under a 10-query cap per problem; it improves ALE-Bench solutions over strong baselines. 4) Where can I run it and what’s the license?The GitHub repo provides a WebUI and examples; ShinkaEvolve is released under Apache-2.0. Check out the Technical details, Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. The post Sakana AI Released ShinkaEvolve: An Open-Source Framework that Evolves Programs for Scientific Discovery with Unprecedented Sample-Efficiency appeared first on MarkTechPost.