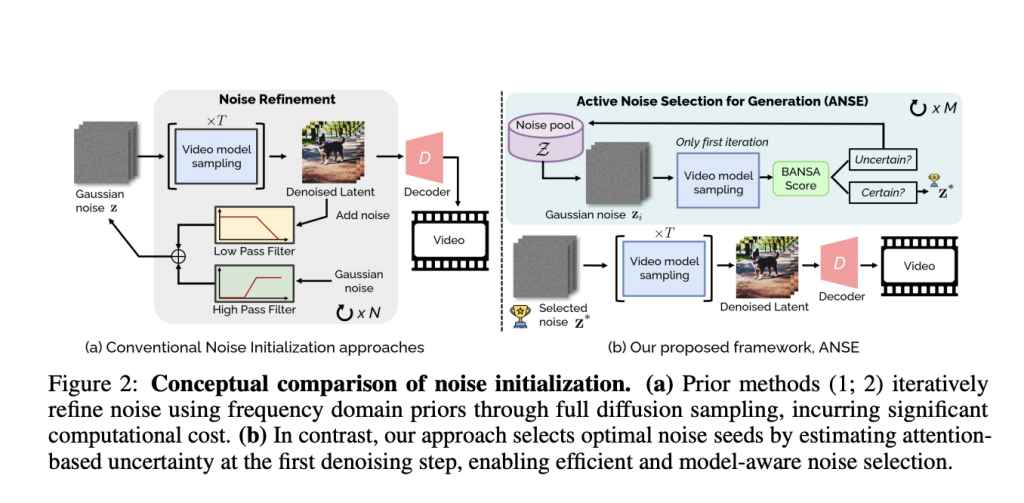
Video generation models have become a core technology for creating dynamic content by transforming text prompts into high-quality video sequences. Diffusion models, in particular, have established themselves as a leading approach for this task. These models work by starting from random noise and iteratively refining it into realistic video frames. Text-to-video (T2V) models extend this capability by incorporating temporal elements and aligning generated content with textual prompts, producing videos that are both visually compelling and semantically accurate. Despite advancements in architecture design, such as latent diffusion models and motion-aware attention modules, a significant challenge remains: ensuring consistent, high-quality video generation across different runs, particularly when the only change is the initial random noise seed. This challenge has highlighted the need for smarter, model-aware noise selection strategies to avoid unpredictable outputs and wasted computational resources. The core problem lies in how diffusion models initialize their generation process from Gaussian noise. The specific noise seed used can drastically impact the final video quality, temporal coherence, and prompt fidelity. For example, the same text prompt might generate entirely different videos depending on the random noise seed. Current approaches often attempt to address this problem by using handcrafted noise priors or frequency-based adjustments. Methods like FreeInit and FreqPrior apply external filtering techniques, while others like PYoCo introduce structured noise patterns. However, these methods rely on assumptions that may not hold across different datasets or models, require multiple full sampling passes (resulting in high computational costs), and fail to leverage the model’s internal attention signals, which could indicate which seeds are most promising for generation. As a result, there is a need for a more principled, model-aware method that can guide noise selection without incurring heavy computational penalties or relying on handcrafted priors. The research team from Samsung Research introduced ANSE (Active Noise Selection for Generation), an Active Noise Selection framework for video diffusion models. ANSE addresses the noise selection problem by using internal model signals, specifically attention-based uncertainty estimates, to guide noise seed selection. At the core of ANSE is BANSA (Bayesian Active Noise Selection via Attention), a novel acquisition function that quantifies the consistency and confidence of the model’s attention maps under stochastic perturbations. The research team designed BANSA to operate efficiently during inference by approximating its calculations through Bernoulli-masked attention sampling, which introduces randomness directly into the attention computation without requiring multiple full forward passes. This stochastic method enables the model to estimate the stability of its attention behavior across different noise seeds and select those that promote more confident and coherent attention patterns, which are empirically linked to improved video quality. BANSA works by evaluating entropy in the attention maps, which are generated at specific layers during the early denoising steps. The researchers identified that layers 14 for the CogVideoX-2B model and layer 19 for the CogVideoX-5B model provided sufficient correlation (above a 0.7 threshold) with the full-layer uncertainty estimate, significantly reducing computational overhead. The BANSA score is computed by comparing the average entropy of individual attention maps to the entropy of their mean, where a lower BANSA score indicates higher confidence and consistency in attention patterns. This score is used to rank candidate noise seeds from a pool of 10 (M = 10), each evaluated using 10 stochastic forward passes (K = 10). The noise seed with the lowest BANSA score is then used to generate the final video, achieving improved quality without requiring model retraining or external priors. On the CogVideoX-2B model, the total VBench score improved from 81.03 to 81.66 (+0.63), with a +0.48 gain in quality score and +1.23 gain in semantic alignment. On the larger CogVideoX-5B model, ANSE increased the total VBench score from 81.52 to 81.71 (+0.25), with a +0.17 gain in quality and +0.60 gain in semantic alignment. Notably, these improvements came with only an 8.68% increase in inference time for CogVideoX-2B and 13.78% for CogVideoX-5B. In contrast, prior methods, such as FreeInit and FreqPrior, required a 200% increase in inference time, making ANSE significantly more efficient. Qualitative evaluations further highlighted the benefits, showing that ANSE improved visual clarity, semantic consistency, and motion portrayal. For example, videos of “a koala playing the piano” and “a zebra running” showed more natural, anatomically correct motion under ANSE, while in prompts like “exploding,” ANSE-generated videos captured dynamic transitions more effectively. The research also explored different acquisition functions, comparing BANSA against random noise selection and entropy-based methods. BANSA using Bernoulli-masked attention achieved the highest total scores (81.66 for CogVideoX-2B), outperforming both random (81.03) and entropy-based methods (81.13). The study also found that increasing the number of stochastic forward passes (K) improved performance up to K = 10, beyond which the gains plateaued. Similarly, performance saturated at a noise pool size (M) of 10. A control experiment where the model intentionally selected seeds with the highest BANSA scores resulted in degraded video quality, confirming that lower BANSA scores correlate with better generation outcomes. While ANSE improves noise selection, it does not modify the generation process itself, meaning that some low-BANSA seeds can still result in suboptimal videos. The team acknowledged this limitation and suggested that BANSA is best viewed as a practical surrogate for more computationally intensive methods, such as per-seed sampling with post-hoc filtering. They also proposed that future work could integrate information-theoretic refinements or active learning strategies to enhance the quality of generation further. Several key takeaways from the research include: ANSE improves total VBench scores for video generation: from 81.03 to 81.66 on CogVideoX-2B and from 81.52 to 81.71 on CogVideoX-5B. Quality and semantic alignment gains are +0.48 and +1.23 for CogVideoX-2B, and +0.17 and +0.60 for CogVideoX-5B, respectively. Inference time increases are modest: +8.68% for CogVideoX-2B and +13.78% for CogVideoX-5B. BANSA scores derived from Bernoulli-masked attention outperform random and entropy-based methods for noise selection. The layer selection strategy reduces computational load by computing uncertainty at layers 14 and 19 for CogVideoX-2B and CogVideoX-5B, respectively. ANSE achieves efficiency by avoiding multiple full sampling passes, in contrast to methods like FreeInit, which require 200% more inference