

NAS-LoRA: Empowering Parameter-Efficient Fine-Tuning for Visual Foundation Models with Searchable Adaptation
arXiv:2512.03499v1 Announce Type: cross Abstract: The Segment Anything Model (SAM) has emerged as a powerful...
Narrowing the Gap: Supervised Fine-Tuning of Open-Source LLMs as a Viable Alternative to Proprietary Models for Pedagogical Tools
arXiv:2507.05305v1 Announce Type: cross Abstract: Frontier Large language models (LLMs) like ChatGPT and Gemini can...
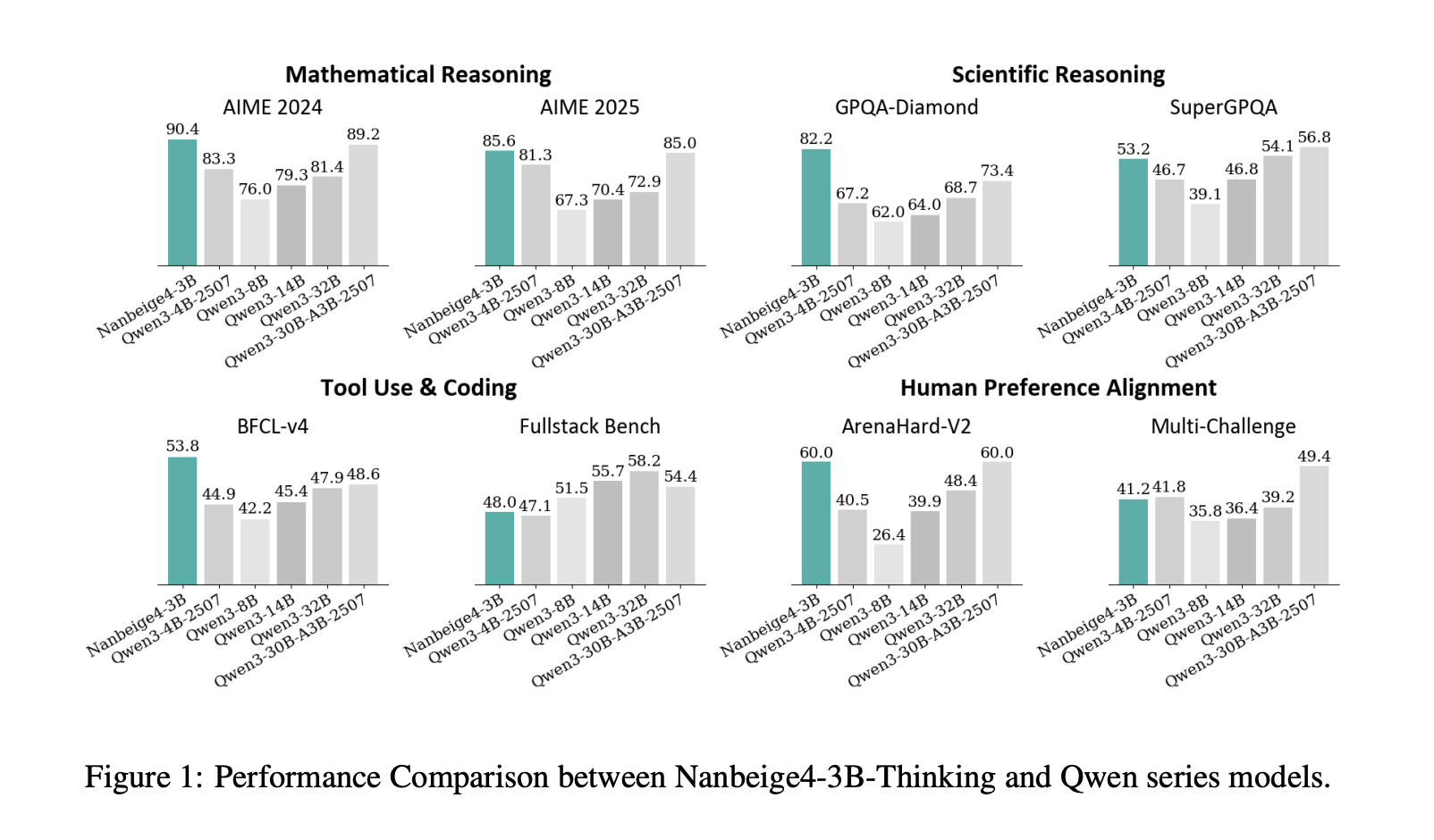
Nanbeige4-3B-Thinking: How a 23T Token Pipeline Pushes 3B Models Past 30B Class Reasoning
Can a 3B model deliver 30B class reasoning by fixing the training recipe instead of...
MultiVis-Agent: A Multi-Agent Framework with Logic Rules for Reliable and Comprehensive Cross-Modal Data Visualization
arXiv:2601.18320v1 Announce Type: new Abstract: Real-world visualization tasks involve complex, multi-modal requirements that extend beyond...
Multimodal RewardBench 2: Evaluating Omni Reward Models for Interleaved Text and Image
arXiv:2512.16899v1 Announce Type: new Abstract: Reward models (RMs) are essential for training large language models...

Multimodal LLMs Without Compromise: Researchers from UCLA, UW–Madison, and Adobe Introduce X-Fusion to Add Vision to Frozen Language Models Without Losing Language Capabilities
LLMs have made significant strides in language-related tasks such as conversational AI, reasoning, and code...
Multimodal LLMs Do Not Compose Skills Optimally Across Modalities
arXiv:2511.08113v1 Announce Type: new Abstract: Skill composition is the ability to combine previously learned skills...
Multimodal Large Language Models Meet Multimodal Emotion Recognition and Reasoning: A Survey
arXiv:2509.24322v1 Announce Type: new Abstract: In recent years, large language models (LLMs) have driven major...
Multimodal In-context Learning for ASR of Low-resource Languages
arXiv:2601.05707v1 Announce Type: new Abstract: Automatic speech recognition (ASR) still covers only a small fraction...

Multimodal Foundation Models Fall Short on Physical Reasoning: PHYX Benchmark Highlights Key Limitations in Visual and Symbolic Integration
State-of-the-art models show human-competitive accuracy on AIME, GPQA, MATH-500, and OlympiadBench, solving Olympiad-level problems. Recent...
Multimodal Detection of Fake Reviews using BERT and ResNet-50
arXiv:2511.00020v1 Announce Type: cross Abstract: In the current digital commerce landscape, user-generated reviews play a...
Multimodal Assessment of Classroom Discourse Quality: A Text-Centered Attention-Based Multi-Task Learning Approach
arXiv:2505.07902v1 Announce Type: cross Abstract: Classroom discourse is an essential vehicle through which teaching and...