

Bias Beware: The Impact of Cognitive Biases on LLM-Driven Product Recommendations
arXiv:2502.01349v2 Announce Type: replace Abstract: The advent of Large Language Models (LLMs) has revolutionized product...
Beyond Weaponization: NLP Security for Medium and Lower-Resourced Languages in Their Own Right
arXiv:2507.03473v1 Announce Type: new Abstract: Despite mounting evidence that multilinguality can be easily weaponized against...
Beyond Token Limits: Assessing Language Model Performance on Long Text Classification
arXiv:2509.10199v1 Announce Type: new Abstract: The most widely used large language models in the social...
Beyond the Exploration-Exploitation Trade-off: A Hidden State Approach for LLM Reasoning in RLVR
arXiv:2509.23808v3 Announce Type: replace-cross Abstract: A prevailing view in Reinforcement Learning with Verifiable Rewards (RLVR)...
Beyond Superficial Unlearning: Sharpness-Aware Robust Erasure of Hallucinations in Multimodal LLMs
arXiv:2601.16527v1 Announce Type: cross Abstract: Multimodal LLMs are powerful but prone to object hallucinations, which...
Beyond single-model AI: How architectural design drives reliable multi-agent orchestration
Successful AI agents require enterprises to orchestrate interactions, manage shared knowledge and plan for failure.Read...
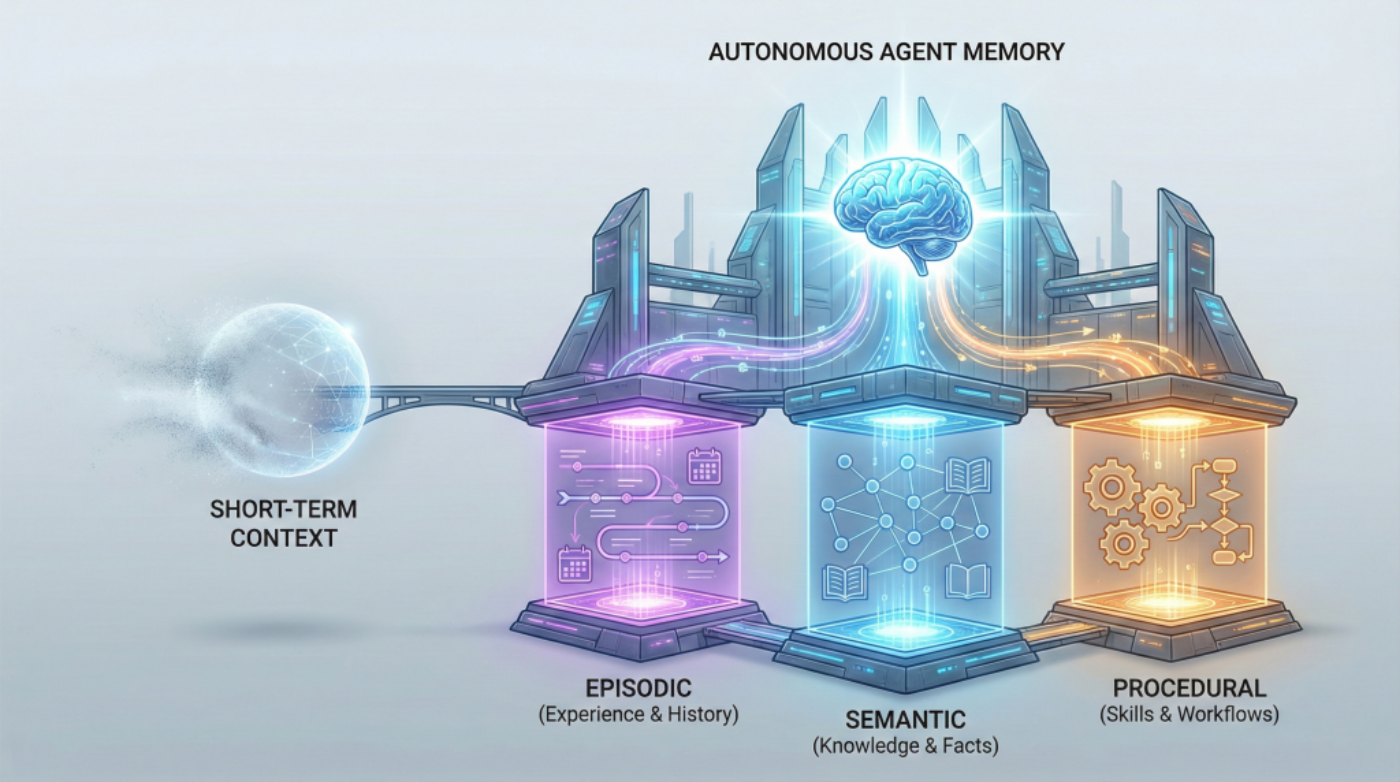
Beyond Short-term Memory: The 3 Types of Long-term Memory AI Agents Need
If you’ve built chatbots or worked with language models, you’re already familiar with how AI...
Beyond Profile: From Surface-Level Facts to Deep Persona Simulation in LLMs
arXiv:2502.12988v2 Announce Type: replace Abstract: Previous approaches to persona simulation large language models (LLMs) have...
Beyond Modality Limitations: A Unified MLLM Approach to Automated Speaking Assessment with Effective Curriculum Learning
arXiv:2508.12591v1 Announce Type: new Abstract: Traditional Automated Speaking Assessment (ASA) systems exhibit inherent modality limitations:...
Beyond instruction-conditioning, MoTE: Mixture of Task Experts for Multi-task Embedding Models
arXiv:2506.17781v1 Announce Type: cross Abstract: Dense embeddings are fundamental to modern machine learning systems, powering...
Beyond Imitation: Recovering Dense Rewards from Demonstrations
arXiv:2510.02493v1 Announce Type: cross Abstract: Conventionally, supervised fine-tuning (SFT) is treated as a simple imitation...

Beyond Homogeneous Attention: Memory-Efficient LLMs via Fourier-Approximated KV Cache
arXiv:2506.11886v1 Announce Type: new Abstract: Large Language Models struggle with memory demands from the growing...