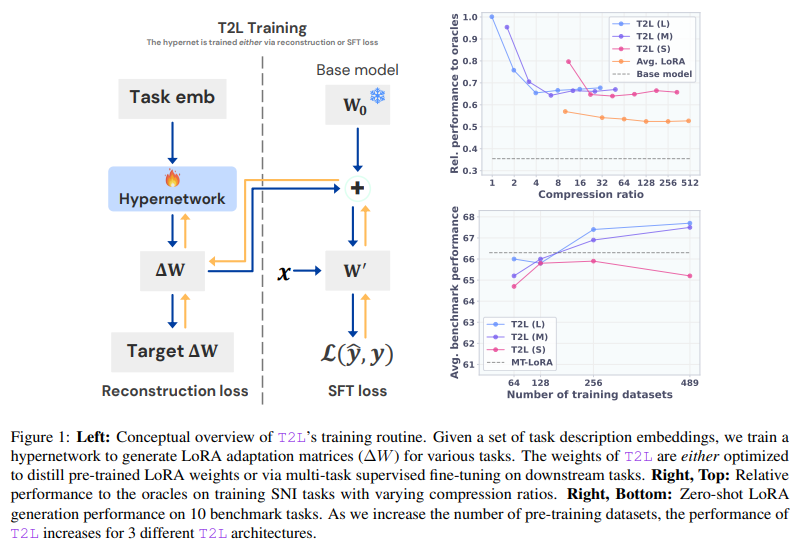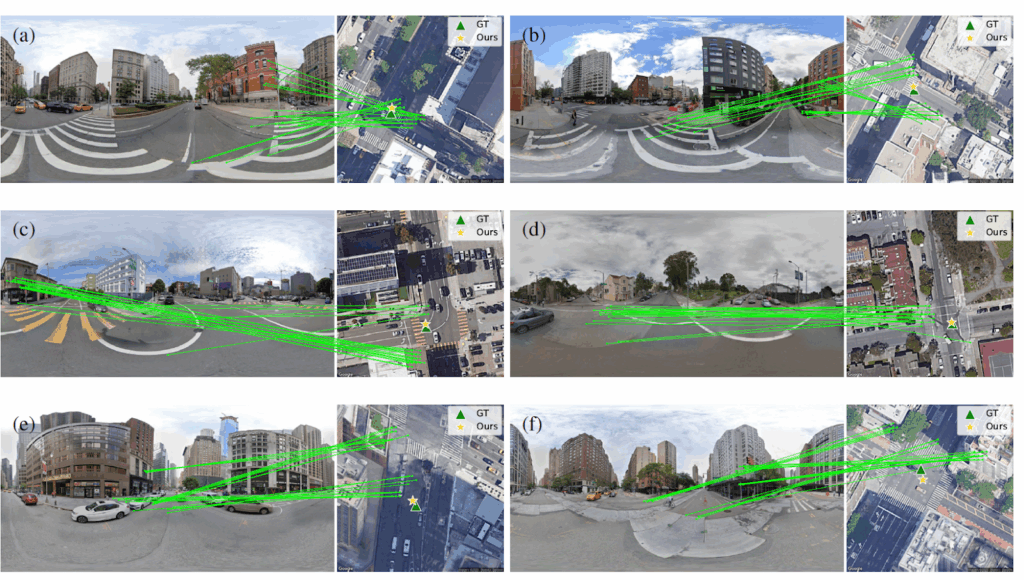
EPFL Researchers Unveil FG2 at CVPR: A New AI Model That Slashes Localization Errors by 28% for Autonomous Vehicles in GPS-Denied Environments
Navigating the dense urban canyons of cities like San Francisco or New York can be a nightmare for GPS systems. The towering skyscrapers block and reflect satellite signals, leading to location errors of tens of meters. For you and me, that might mean a missed turn. But for an autonomous vehicle or a delivery robot, that level of imprecision is the difference between a successful mission and a costly failure. These machines require pinpoint accuracy to operate safely and efficiently. Addressing this critical challenge, researchers from the École Polytechnique Fédérale de Lausanne (EPFL) in Switzerland have introduced a groundbreaking new method for visual localization during CVPR 2025 Their new paper, “FG2: Fine-Grained Cross-View Localization by Fine-Grained Feature Matching,” presents a novel AI model that significantly enhances the ability of a ground-level system, like an autonomous car, to determine its exact position and orientation using only a camera and a corresponding aerial (or satellite) image. The new approach has demonstrated a remarkable 28% reduction in mean localization error compared to the previous state-of-the-art on a challenging public dataset. Key Takeaways: Superior Accuracy: The FG2 model reduces the average localization error by a significant 28% on the VIGOR cross-area test set, a challenging benchmark for this task. Human-like Intuition: Instead of relying on abstract descriptors, the model mimics human reasoning by matching fine-grained, semantically consistent features—like curbs, crosswalks, and buildings—between a ground-level photo and an aerial map. Enhanced Interpretability: The method allows researchers to “see” what the AI is “thinking” by visualizing exactly which features in the ground and aerial images are being matched, a major step forward from previous “black box” models. Weakly Supervised Learning: Remarkably, the model learns these complex and consistent feature matches without any direct labels for correspondences. It achieves this using only the final camera pose as a supervisory signal. Challenge: Seeing the World from Two Different Angles The core problem of cross-view localization is the dramatic difference in perspective between a street-level camera and an overhead satellite view. A building facade seen from the ground looks completely different from its rooftop signature in an aerial image. Existing methods have struggled with this. Some create a general “descriptor” for the entire scene, but this is an abstract approach that doesn’t mirror how humans naturally localize themselves by spotting specific landmarks. Other methods transform the ground image into a Bird’s-Eye-View (BEV) but are often limited to the ground plane, ignoring crucial vertical structures like buildings. FG2: Matching Fine-Grained Features The EPFL team’s FG2 method introduces a more intuitive and effective process. It aligns two sets of points: one generated from the ground-level image and another sampled from the aerial map. Here’s a breakdown of their innovative pipeline: Mapping to 3D: The process begins by taking the features from the ground-level image and lifting them into a 3D point cloud centered around the camera. This creates a 3D representation of the immediate environment. Smart Pooling to BEV: This is where the magic happens. Instead of simply flattening the 3D data, the model learns to intelligently select the most important features along the vertical (height) dimension for each point. It essentially asks, “For this spot on the map, is the ground-level road marking more important, or is the edge of that building’s roof the better landmark?” This selection process is crucial, as it allows the model to correctly associate features like building facades with their corresponding rooftops in the aerial view. Feature Matching and Pose Estimation: Once both the ground and aerial views are represented as 2D point planes with rich feature descriptors, the model computes the similarity between them. It then samples a sparse set of the most confident matches and uses a classic geometric algorithm called Procrustes alignment to calculate the precise 3-DoF (x, y, and yaw) pose. Unprecedented Performance and Interpretability The results speak for themselves. On the challenging VIGOR dataset, which includes images from different cities in its cross-area test, FG2 reduced the mean localization error by 28% compared to the previous best method. It also demonstrated superior generalization capabilities on the KITTI dataset, a staple in autonomous driving research. Perhaps more importantly, the FG2 model offers a new level of transparency. By visualizing the matched points, the researchers showed that the model learns semantically consistent correspondences without being explicitly told to. For example, the system correctly matches zebra crossings, road markings, and even building facades in the ground view to their corresponding locations on the aerial map. This interpretability is extremenly valuable for building trust in safety-critical autonomous systems. “A Clearer Path” for Autonomous Navigation The FG2 method represents a significant leap forward in fine-grained visual localization. By developing a model that intelligently selects and matches features in a way that mirrors human intuition, the EPFL researchers have not only shattered previous accuracy records but also made the decision-making process of the AI more interpretable. This work paves the way for more robust and reliable navigation systems for autonomous vehicles, drones, and robots, bringing us one step closer to a future where machines can confidently navigate our world, even when GPS fails them. Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. The post EPFL Researchers Unveil FG2 at CVPR: A New AI Model That Slashes Localization Errors by 28% for Autonomous Vehicles in GPS-Denied Environments appeared first on MarkTechPost.