
Algorithm Showdown: Logistic Regression vs. Random Forest vs. XGBoost on Imbalanced Data
Imbalanced datasets are a common challenge in machine learning.


Imbalanced datasets are a common challenge in machine learning.
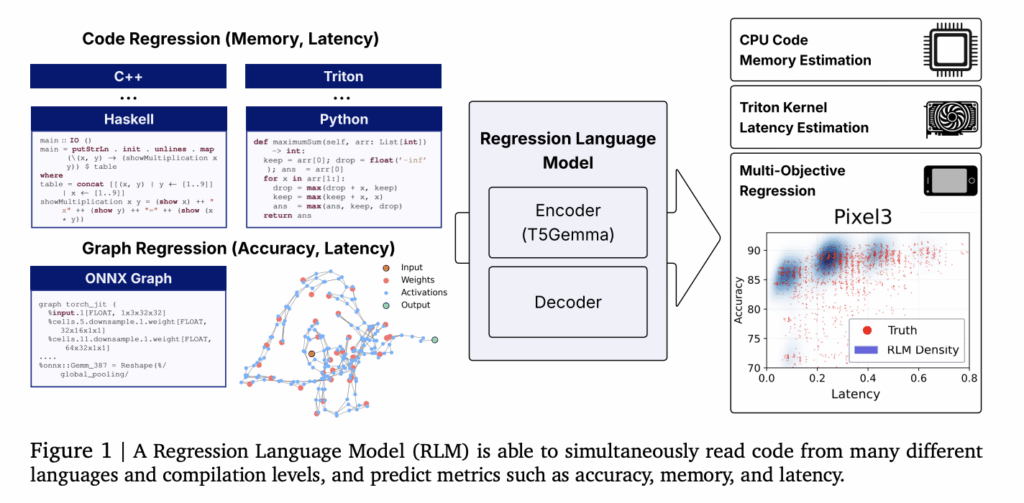
Researchers from Cornell and Google introduce a unified Regression Language Model (RLM) that predicts numeric outcomes directly from code strings—covering GPU kernel latency, program memory usage, and even neural network accuracy and latency—without hand-engineered features. A 300M-parameter encoder–decoder initialized from T5-Gemma achieves strong rank correlations across heterogeneous tasks and languages, using a single text-to-number decoder that emits digits with constrained decoding. What exactly is new? Unified code-to-metric regression: One RLM predicts (i) peak memory from high-level code (Python/C/C++ and more), (ii) latency for Triton GPU kernels, and (iii) accuracy and hardware-specific latency from ONNX graphs—by reading raw text representations and decoding numeric outputs. No feature engineering, graph encoders, or zero-cost proxies are required. Concrete results: Reported correlations include Spearman ρ ≈ 0.93 on APPS LeetCode memory, ρ ≈ 0.52 for Triton kernel latency, ρ > 0.5 average across 17 CodeNet languages, and Kendall τ ≈ 0.46 across five classic NAS spaces—competitive with and in some cases surpassing graph-based predictors. Multi-objective decoding: Because the decoder is autoregressive, the model conditions later metrics on earlier ones (e.g., accuracy → per-device latencies), capturing realistic trade-offs along Pareto fronts. https://arxiv.org/abs/2509.26476 Why is this important? Performance prediction pipelines in compilers, GPU kernel selection, and NAS typically rely on bespoke features, syntax trees, or GNN encoders that are brittle to new ops/languages. Treating regression as next-token prediction over numbers standardizes the stack: tokenize inputs as plain text (source code, Triton IR, ONNX), then decode calibrated numeric strings digit-by-digit with constrained sampling. This reduces maintenance cost and improves transfer to new tasks via fine-tuning. Data and benchmarks Code-Regression dataset (HF): Curated to support code-to-metric tasks spanning APPS/LeetCode runs, Triton kernel latencies (KernelBook-derived), and CodeNet memory footprints. NAS/ONNX suite: Architectures from NASBench-101/201, FBNet, Once-for-All (MB/PN/RN), Twopath, Hiaml, Inception, and NDS are exported to ONNX text to predict accuracy and device-specific latency. How does it work? Backbone: Encoder–decoder with a T5-Gemma encoder initialization (~300M params). Inputs are raw strings (code or ONNX). Outputs are numbers emitted as sign/exponent/mantissa digit tokens; constrained decoding enforces valid numerals and supports uncertainty via sampling. Ablations: (i) Language pretraining accelerates convergence and improves Triton latency prediction; (ii) decoder-only numeric emission outperforms MSE regression heads even with y-normalization; (iii) learned tokenizers specialized for ONNX operators increase effective context; (iv) longer contexts help; (v) scaling to a larger Gemma encoder further improves correlation with adequate tuning. Training code. The regress-lm library provides text-to-text regression utilities, constrained decoding, and multi-task pretraining/fine-tuning recipes. Stats that matters APPS (Python) memory: Spearman ρ > 0.9. CodeNet (17 languages) memory: average ρ > 0.5; strongest languages include C/C++ (~0.74–0.75). Triton kernels (A6000) latency: ρ ≈ 0.52. NAS ranking: average Kendall τ ≈ 0.46 across NASNet, Amoeba, PNAS, ENAS, DARTS; competitive with FLAN and GNN baselines. Key Takeaways Unified code-to-metric regression works. A single ~300M-parameter T5Gemma-initialized model (“RLM”) predicts: (a) memory from high-level code, (b) Triton GPU kernel latency, and (c) model accuracy + device latency from ONNX—directly from text, no hand-engineered features. The research shows Spearman ρ > 0.9 on APPS memory, ≈0.52 on Triton latency, >0.5 average across 17 CodeNet languages, and Kendall-τ ≈ 0.46 on five NAS spaces. Numbers are decoded as text with constraints. Instead of a regression head, RLM emits numeric tokens with constrained decoding, enabling multi-metric, autoregressive outputs (e.g., accuracy followed by multi-device latencies) and uncertainty via sampling. The Code-Regression dataset unifies APPS/LeetCode memory, Triton kernel latency, and CodeNet memory; the regress-lm library provides the training/decoding stack. Our Comments It is very interesting how this work reframes performance prediction as text-to-number generation: a compact T5Gemma-initialized RLM reads source (Python/C++), Triton kernels, or ONNX graphs and emits calibrated numerics via constrained decoding. The reported correlations—APPS memory (ρ>0.9), Triton latency on RTX A6000 (~0.52), and NAS Kendall-τ ≈0.46—are strong enough to matter for compiler heuristics, kernel pruning, and multi-objective NAS triage without bespoke features or GNNs. The open dataset and library make replication straightforward and lower the barrier to fine-tuning on new hardware or languages. Check out the Paper, GitHub Page and Dataset Card. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Can a Small Language Model Predict Kernel Latency, Memory, and Model Accuracy from Code? A New Regression Language Model (RLM) Says Yes appeared first on MarkTechPost.
In this tutorial, we walk through an advanced implementation of WhisperX, where we explore transcription, alignment, and word-level timestamps in detail. We set up the environment, load and preprocess the audio, and then run the full pipeline, from transcription to alignment and analysis, while ensuring memory efficiency and supporting batch processing. Along the way, we also visualize results, export them in multiple formats, and even extract keywords to gain deeper insights from the audio content. Check out the FULL CODES here. Copy CodeCopiedUse a different Browser !pip install -q git+https://github.com/m-bain/whisperX.git !pip install -q pandas matplotlib seaborn import whisperx import torch import gc import os import json import pandas as pd from pathlib import Path from IPython.display import Audio, display, HTML import warnings warnings.filterwarnings(‘ignore’) CONFIG = { “device”: “cuda” if torch.cuda.is_available() else “cpu”, “compute_type”: “float16” if torch.cuda.is_available() else “int8”, “batch_size”: 16, “model_size”: “base”, “language”: None, } print(f” Running on: {CONFIG[‘device’]}”) print(f” Compute type: {CONFIG[‘compute_type’]}”) print(f” Model: {CONFIG[‘model_size’]}”) We begin by installing WhisperX along with essential libraries and then configure our setup. We detect whether CUDA is available, select the compute type, and set parameters such as batch size, model size, and language to prepare for transcription. Check out the FULL CODES here. Copy CodeCopiedUse a different Browser def download_sample_audio(): “””Download a sample audio file for testing””” !wget -q -O sample.mp3 https://github.com/mozilla-extensions/speaktome/raw/master/content/cv-valid-dev/sample-000000.mp3 print(” Sample audio downloaded”) return “sample.mp3” def load_and_analyze_audio(audio_path): “””Load audio and display basic info””” audio = whisperx.load_audio(audio_path) duration = len(audio) / 16000 print(f” Audio: {Path(audio_path).name}”) print(f” Duration: {duration:.2f} seconds”) print(f” Sample rate: 16000 Hz”) display(Audio(audio_path)) return audio, duration def transcribe_audio(audio, model_size=CONFIG[“model_size”], language=None): “””Transcribe audio using WhisperX (batched inference)””” print(“n STEP 1: Transcribing audio…”) model = whisperx.load_model( model_size, CONFIG[“device”], compute_type=CONFIG[“compute_type”] ) transcribe_kwargs = { “batch_size”: CONFIG[“batch_size”] } if language: transcribe_kwargs[“language”] = language result = model.transcribe(audio, **transcribe_kwargs) total_segments = len(result[“segments”]) total_words = sum(len(seg.get(“words”, [])) for seg in result[“segments”]) del model gc.collect() if CONFIG[“device”] == “cuda”: torch.cuda.empty_cache() print(f” Transcription complete!”) print(f” Language: {result[‘language’]}”) print(f” Segments: {total_segments}”) print(f” Total text length: {sum(len(seg[‘text’]) for seg in result[‘segments’])} characters”) return result We download a sample audio file, load it for analysis, and then transcribe it using WhisperX. We set up batched inference with our chosen model size and configuration, and we output key details such as language, number of segments, and total text length. Check out the FULL CODES here. Copy CodeCopiedUse a different Browser def align_transcription(segments, audio, language_code): “””Align transcription for accurate word-level timestamps””” print(“n STEP 2: Aligning for word-level timestamps…”) try: model_a, metadata = whisperx.load_align_model( language_code=language_code, device=CONFIG[“device”] ) result = whisperx.align( segments, model_a, metadata, audio, CONFIG[“device”], return_char_alignments=False ) total_words = sum(len(seg.get(“words”, [])) for seg in result[“segments”]) del model_a gc.collect() if CONFIG[“device”] == “cuda”: torch.cuda.empty_cache() print(f” Alignment complete!”) print(f” Aligned words: {total_words}”) return result except Exception as e: print(f” Alignment failed: {str(e)}”) print(” Continuing with segment-level timestamps only…”) return {“segments”: segments, “word_segments”: []} We align the transcription to generate precise word-level timestamps. By loading the alignment model and applying it to the audio, we refine timing accuracy, and then report the total aligned words while ensuring memory is cleared for efficient processing. Check out the FULL CODES here. Copy CodeCopiedUse a different Browser def analyze_transcription(result): “””Generate statistics about the transcription””” print(“n TRANSCRIPTION STATISTICS”) print(“=”*70) segments = result[“segments”] total_duration = max(seg[“end”] for seg in segments) if segments else 0 total_words = sum(len(seg.get(“words”, [])) for seg in segments) total_chars = sum(len(seg[“text”].strip()) for seg in segments) print(f”Total duration: {total_duration:.2f} seconds”) print(f”Total segments: {len(segments)}”) print(f”Total words: {total_words}”) print(f”Total characters: {total_chars}”) if total_duration > 0: print(f”Words per minute: {(total_words / total_duration * 60):.1f}”) pauses = [] for i in range(len(segments) – 1): pause = segments[i+1][“start”] – segments[i][“end”] if pause > 0: pauses.append(pause) if pauses: print(f”Average pause between segments: {sum(pauses)/len(pauses):.2f}s”) print(f”Longest pause: {max(pauses):.2f}s”) word_durations = [] for seg in segments: if “words” in seg: for word in seg[“words”]: duration = word[“end”] – word[“start”] word_durations.append(duration) if word_durations: print(f”Average word duration: {sum(word_durations)/len(word_durations):.3f}s”) print(“=”*70) We analyze the transcription by generating detailed statistics such as total duration, segment count, word count, and character count. We also calculate words per minute, pauses between segments, and average word duration to better understand the pacing and flow of the audio. Check out the FULL CODES here. Copy CodeCopiedUse a different Browser def display_results(result, show_words=False, max_rows=50): “””Display transcription results in formatted table””” data = [] for seg in result[“segments”]: text = seg[“text”].strip() start = f”{seg[‘start’]:.2f}s” end = f”{seg[‘end’]:.2f}s” duration = f”{seg[‘end’] – seg[‘start’]:.2f}s” if show_words and “words” in seg: for word in seg[“words”]: data.append({ “Start”: f”{word[‘start’]:.2f}s”, “End”: f”{word[‘end’]:.2f}s”, “Duration”: f”{word[‘end’] – word[‘start’]:.3f}s”, “Text”: word[“word”], “Score”: f”{word.get(‘score’, 0):.2f}” }) else: data.append({ “Start”: start, “End”: end, “Duration”: duration, “Text”: text }) df = pd.DataFrame(data) if len(df) > max_rows: print(f”Showing first {max_rows} rows of {len(df)} total…”) display(HTML(df.head(max_rows).to_html(index=False))) else: display(HTML(df.to_html(index=False))) return df def export_results(result, output_dir=”output”, filename=”transcript”): “””Export results in multiple formats””” os.makedirs(output_dir, exist_ok=True) json_path = f”{output_dir}/{filename}.json” with open(json_path, “w”, encoding=”utf-8″) as f: json.dump(result, f, indent=2, ensure_ascii=False) srt_path = f”{output_dir}/{filename}.srt” with open(srt_path, “w”, encoding=”utf-8″) as f: for i, seg in enumerate(result[“segments”], 1): start = format_timestamp(seg[“start”]) end = format_timestamp(seg[“end”]) f.write(f”{i}n{start} –> {end}n{seg[‘text’].strip()}nn”) vtt_path = f”{output_dir}/{filename}.vtt” with open(vtt_path, “w”, encoding=”utf-8″) as f: f.write(“WEBVTTnn”) for i, seg in enumerate(result[“segments”], 1): start = format_timestamp_vtt(seg[“start”]) end = format_timestamp_vtt(seg[“end”]) f.write(f”{start} –> {end}n{seg[‘text’].strip()}nn”) txt_path = f”{output_dir}/{filename}.txt” with open(txt_path, “w”, encoding=”utf-8″) as f: for seg in result[“segments”]: f.write(f”{seg[‘text’].strip()}n”) csv_path = f”{output_dir}/{filename}.csv” df_data = [] for seg in result[“segments”]: df_data.append({ “start”: seg[“start”], “end”: seg[“end”], “text”: seg[“text”].strip() }) pd.DataFrame(df_data).to_csv(csv_path, index=False) print(f”n Results exported to ‘{output_dir}/’ directory:”) print(f” ✓ {filename}.json (full structured data)”) print(f” ✓ {filename}.srt (subtitles)”) print(f” ✓ {filename}.vtt (web video subtitles)”) print(f” ✓ {filename}.txt (plain text)”) print(f” ✓ {filename}.csv (timestamps + text)”) def format_timestamp(seconds): “””Convert seconds to SRT timestamp format””” hours = int(seconds // 3600) minutes = int((seconds % 3600) // 60) secs = int(seconds % 60) millis = int((seconds % 1) * 1000) return f”{hours:02d}:{minutes:02d}:{secs:02d},{millis:03d}” def format_timestamp_vtt(seconds): “””Convert seconds to VTT timestamp format””” hours = int(seconds // 3600) minutes = int((seconds % 3600) // 60) secs = int(seconds % 60) millis = int((seconds % 1) * 1000) return f”{hours:02d}:{minutes:02d}:{secs:02d}.{millis:03d}” def batch_process_files(audio_files, output_dir=”batch_output”): “””Process multiple audio files in batch””” print(f”n Batch processing {len(audio_files)} files…”) results = {}
arXiv:2510.01391v1 Announce Type: new Abstract: Large language models (LLMs) excel at general language tasks but often struggle with event-based questions-especially those requiring causal or temporal reasoning. We introduce TAG-EQA (Text-And-Graph for Event Question Answering), a prompting framework that injects causal event graphs into LLM inputs by converting structured relations into natural-language statements. TAG-EQA spans nine prompting configurations, combining three strategies (zero-shot, few-shot, chain-of-thought) with three input modalities (text-only, graph-only, text+graph), enabling a systematic analysis of when and how structured knowledge aids inference. On the TORQUESTRA benchmark, TAG-EQA improves accuracy by 5% on average over text-only baselines, with gains up to 12% in zero-shot settings and 18% when graph-augmented CoT prompting is effective. While performance varies by model and configuration, our findings show that causal graphs can enhance event reasoning in LLMs without fine-tuning, offering a flexible way to encode structure in prompt-based QA.
arXiv:2510.01304v1 Announce Type: cross Abstract: Although current large Vision-Language Models (VLMs) have advanced in multimodal understanding and reasoning, their fundamental perceptual and reasoning abilities remain limited. Specifically, even on simple jigsaw tasks, existing VLMs perform near randomly, revealing deficiencies in core perception and reasoning capabilities. While high-quality vision-language data can enhance these capabilities, its scarcity and limited scalability impose significant constraints. To address this, we propose AGILE, an Agentic jiGsaw Interaction Learning for Enhancing visual perception and reasoning in VLMs. AGILE formulates jigsaw solving as an interactive process, enabling the model to progressively engage with the environment. At each step, the model generates executable code to perform an action based on the current state, while the environment provides fine-grained visual feedback to guide task completion. Through this iterative cycle of observation and interaction, the model incrementally improves its perceptual and reasoning capabilities via exploration and feedback. Experimental results show that AGILE not only substantially boosts performance on jigsaw tasks of varying complexity (e.g., increasing accuracy from 9.5% to 82.8% under the 2 $times$ 2 setting) but also demonstrates strong generalization across 9 general vision tasks, achieving an average improvement of 3.1%. These results indicate notable enhancements in both perceptual and reasoning abilities. This work opens a new avenue for advancing reasoning and generalization in multimodal models and provides an efficient, scalable solution to the scarcity of multimodal reinforcement learning data. The code and datasets is available at https://github.com/yuzeng0-0/AGILE .
Neuphonic has released NeuTTS Air, an open-source text-to-speech (TTS) speech language model designed to run locally in real time on CPUs. The Hugging Face model card lists 748M parameters (Qwen2 architecture) and ships in GGUF quantizations (Q4/Q8), enabling inference through llama.cpp/llama-cpp-python without cloud dependencies. It is licensed under Apache-2.0 and includes a runnable demo and examples. So, what is new? NeuTTS Air couples a 0.5B-class Qwen backbone with Neuphonic’s NeuCodec audio codec. Neuphonic positions the system as a “super-realistic, on-device” TTS LM that clones a voice from ~3 seconds of reference audio and synthesizes speech in that style, targeting voice agents and privacy-sensitive applications. The model card and repository explicitly emphasize real-time CPU generation and small-footprint deployment. Key Features Realism at sub-1B scale: Human-like prosody and timbre preservation for a ~0.7B (Qwen2-class) text-to-speech LM. On-device deployment: Distributed in GGUF (Q4/Q8) with CPU-first paths; suitable for laptops, phones, and Raspberry Pi-class boards. Instant speaker cloning: Style transfer from ~3 seconds of reference audio (reference WAV + transcript). Compact LM+codec stack: Qwen 0.5B backbone paired with NeuCodec (0.8 kbps / 24 kHz) to balance latency, footprint, and output quality. Explain the model architecture and runtime path? Backbone: Qwen 0.5B used as a lightweight LM to condition speech generation; the hosted artifact is reported as 748M params under the qwen2 architecture on Hugging Face. Codec: NeuCodec provides low-bitrate acoustic tokenization/decoding; it targets 0.8 kbps with 24 kHz output, enabling compact representations for efficient on-device use. Quantization & format: Prebuilt GGUF backbones (Q4/Q8) are available; the repo includes instructions for llama-cpp-python and an optional ONNX decoder path. Dependencies: Uses espeak for phonemization; examples and a Jupyter notebook are provided for end-to-end synthesis. On-device performance focus NeuTTS Air showcases ‘real-time generation on mid-range devices‘ and offers CPU-first defaults; GGUF quantization is intended for laptops and single-board computers. While no fps/RTF numbers are published on the card, the distribution targets local inference without a GPU and demonstrates a working flow through the provided examples and Space. Voice cloning workflow NeuTTS Air requires (1) a reference WAV and (2) the transcript text for that reference. It encodes the reference to style tokens and then synthesizes arbitrary text in the reference speaker’s timbre. The Neuphonic team recommends 3–15 s clean, mono audio and provides pre-encoded samples. Privacy, responsibility, and watermarking Neuphonic frames the model for on-device privacy (no audio/text leaves the machine without user’s approval) and notes that all generated audio includes a Perth (Perceptual Threshold) watermarker to support responsible use and provenance. How it compares? Open, local TTS systems exist (e.g., GGUF-based pipelines), but NeuTTS Air is notable for packaging a small LM + neural codec with instant cloning, CPU-first quantizations, and watermarking under a permissive license. The “world’s first super-realistic, on-device speech LM” phrasing is the vendor’s claim; the verifiable facts are the size, formats, cloning procedure, license, and provided runtimes. Our Comments The focus is on system trade-offs: a ~0.7B Qwen-class backbone with GGUF quantization paired with NeuCodec at 0.8 kbps/24 kHz is a pragmatic recipe for real-time, CPU-only TTS that preserves timbre using ~3–15 s style references while keeping latency and memory predictable. The Apache-2.0 licensing and built-in watermarking are deployment-friendly, but publishing RTF/latency on commodity CPUs and cloning-quality vs. reference-length curves would enable rigorous benchmarking against existing local pipelines. Operationally, an offline path with minimal dependencies (eSpeak, llama.cpp/ONNX) lowers privacy/compliance risk for edge agents without sacrificing intelligibility. Check out the Model Card on Hugging Face and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Neuphonic Open-Sources NeuTTS Air: A 748M-Parameter On-Device Speech Language Model with Instant Voice Cloning appeared first on MarkTechPost.
Thinking Machines has released Tinker, a Python API that lets researchers and engineers write training loops locally while the platform executes them on managed distributed GPU clusters. The pitch is narrow and technical: keep full control of data, objectives, and optimization steps; hand off scheduling, fault tolerance, and multi-node orchestration. The service is in private beta with a waitlist and starts free, moving to usage-based pricing “in the coming weeks.” Alright, but tell me what it is? Tinker exposes low-level primitives—not high-level “train()” wrappers. Core calls include forward_backward, optim_step, save_state, and sample, giving users direct control over gradient computation, optimizer stepping, checkpointing, and evaluation/inference inside custom loops. A typical workflow: instantiate a LoRA training client against a base model (e.g., Llama-3.2-1B), iterate forward_backward/optim_step, persist state, then obtain a sampling client to evaluate or export weights. https://thinkingmachines.ai/tinker/ Key Features Open-weights model coverage. Fine-tune families such as Llama and Qwen, including large mixture-of-experts variants (e.g., Qwen3-235B-A22B). LoRA-based post-training. Tinker implements Low-Rank Adaptation (LoRA) rather than full fine-tuning; their technical note (“LoRA Without Regret”) argues LoRA can match full FT for many practical workloads—especially RL—under the right setup. Portable artifacts. Download trained adapter weights for use outside Tinker (e.g., with your preferred inference stack/provider). What runs on it? The Thinking Machines team positions Tinker as a managed post-training platform for open-weights models from small LLMs up to large mixture-of-experts systems, a good example would be Qwen-235B-A22B as a supported model. Switching models is intentionally minimal—change a string identifier and rerun. Under the hood, runs are scheduled on Thinking Machines’ internal clusters; the LoRA approach enables shared compute pools and lower utilization overhead. https://thinkingmachines.ai/tinker/ Tinker Cookbook: Reference Training Loops and Post-Training Recipes To reduce boilerplate while keeping the core API lean, the team published the Tinker Cookbook (Apache-2.0). It contains ready-to-use reference loops for supervised learning and reinforcement learning, plus worked examples for RLHF (three-stage SFT → reward modeling → policy RL), math-reasoning rewards, tool-use / retrieval-augmented tasks, prompt distillation, and multi-agent setups. The repo also ships utilities for LoRA hyperparameter calculation and integrations for evaluation (e.g., InspectAI). Who’s already using it? Early users include groups at Princeton (Gödel prover team), Stanford (Rotskoff Chemistry), UC Berkeley (SkyRL, async off-policy multi-agent/tool-use RL), and Redwood Research (RL on Qwen3-32B for control tasks). Tinker is private beta as of now with waitlist sign-up. The service is free to start, with usage-based pricing planned shortly; organizations are asked to contact the team directly for onboarding. My thoughts/ comments I like that Tinker exposes low-level primitives (forward_backward, optim_step, save_state, sample) instead of a monolithic train()—it keeps objective design, reward shaping, and evaluation in my control while offloading multi-node orchestration to their managed clusters. The LoRA-first posture is pragmatic for cost and turnaround, and their own analysis argues LoRA can match full fine-tuning when configured correctly, but I’d still want transparent logs, deterministic seeds, and per-step telemetry to verify reproducibility and drift. The Cookbook’s RLHF and SL reference loops are useful starting points, yet I’ll judge the platform on throughput stability, checkpoint portability, and guardrails for data governance (PII handling, audit trails) during real workloads. Overall I prefer Tinker’s open, flexible API: it lets me customize open-weight LLMs via explicit training-loop primitives while the service handles distributed execution. Compared with closed systems, this preserves algorithmic control (losses, RLHF workflows, data handling) and lowers the barrier for new practitioners to experiment and iterate. Check out the Technical details and Sign up for our waitlist here. If you’re a university or organization looking for wide scale access, contact tinker@thinkingmachines.ai. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post Thinking Machines Launches Tinker: A Low-Level Training API that Abstracts Distributed LLM Fine-Tuning without Hiding the Knobs appeared first on MarkTechPost.
arXiv:2405.20485v3 Announce Type: replace-cross Abstract: Retrieval Augmented Generation (RAG) expands the capabilities of modern large language models (LLMs), by anchoring, adapting, and personalizing their responses to the most relevant knowledge sources. It is particularly useful in chatbot applications, allowing developers to customize LLM output without expensive retraining. Despite their significant utility in various applications, RAG systems present new security risks. In this work, we propose a novel attack that allows an adversary to inject a single malicious document into a RAG system’s knowledge base, and mount a backdoor poisoning attack. We design Phantom, a general two-stage optimization framework against RAG systems, that crafts a malicious poisoned document leading to an integrity violation in the model’s output. First, the document is constructed to be retrieved only when a specific naturally occurring trigger sequence of tokens appears in the victim’s queries. Second, the document is further optimized with crafted adversarial text that induces various adversarial objectives on the LLM output, including refusal to answer, reputation damage, privacy violations, and harmful behaviors.We demonstrate our attacks on multiple open-source LLM architectures, including Gemma, Vicuna, and Llama, and show that they transfer to closed-source models such as GPT-3.5 Turbo and GPT-4. Finally, we successfully demonstrate our attack on an end-to-end black-box production RAG system: NVIDIA’s “Chat with RTX”.
Phantom: General Backdoor Attacks on Retrieval Augmented Language Generation Leer entrada »
arXiv:2510.01076v1 Announce Type: new Abstract: This article addresses embodied intelligence and reinforcement learning integration in the field of text processing, aiming to enhance text handling with more intelligence on the basis of embodied intelligence’s perception and action superiority and reinforcement learning’s decision optimization capability. Through detailed theoretical explanation and experimental exploration, a novel integration model is introduced. This model has been demonstrated to be very effective in a wide range oftext processing tasks, validating its applicative potential
arXiv:2510.00694v1 Announce Type: new Abstract: We introduce ALARB, a dataset and suite of tasks designed to evaluate the reasoning capabilities of large language models (LLMs) within the Arabic legal domain. While existing Arabic benchmarks cover some knowledge-intensive tasks such as retrieval and understanding, substantial datasets focusing specifically on multistep reasoning for Arabic LLMs, especially in open-ended contexts, are lacking. The dataset comprises over 13K commercial court cases from Saudi Arabia, with each case including the facts presented, the reasoning of the court, the verdict, as well as the cited clauses extracted from the regulatory documents. We define a set of challenging tasks leveraging this dataset and reflecting the complexity of real-world legal reasoning, including verdict prediction, completion of reasoning chains in multistep legal arguments, and identification of relevant regulations based on case facts. We benchmark a representative selection of current open and closed Arabic LLMs on these tasks and demonstrate the dataset’s utility for instruction tuning. Notably, we show that instruction-tuning a modest 12B parameter model using ALARB significantly enhances its performance in verdict prediction and Arabic verdict generation, reaching a level comparable to that of GPT-4o.
ALARB: An Arabic Legal Argument Reasoning Benchmark Leer entrada »
We use cookies to improve your experience and performance on our website. You can learn more at Política de privacidad and manage your privacy settings by clicking Settings.