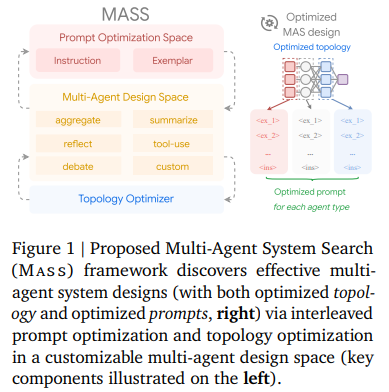
Multi-agent systems are becoming a critical development in artificial intelligence due to their ability to coordinate multiple large language models (LLMs) to solve complex problems. Instead of relying on a single model’s perspective, these systems distribute roles among agents, each contributing a unique function. This division of labor enhances the system’s ability to analyze, respond, and act in more robust ways. Whether applied to code debugging, data analysis, retrieval-augmented generation, or interactive decision-making, LLM-driven agents are achieving results that single models cannot consistently match. The power of these systems lies in their design, particularly the configuration of inter-agent connections, known as topologies, and the specific instructions given to each agent, referred to as prompts. As this model of computation matures, the challenge has shifted from proving feasibility to optimizing architecture and behavior for superior results. One significant problem lies in the difficulty of designing these systems efficiently. When prompts, those structured inputs that guide each agent’s role, are slightly altered, performance can swing dramatically. This sensitivity makes scalability risky, especially when agents are linked together in workflows where one’s output serves as another’s input. Errors can propagate or even amplify. Moreover, topological decisions, such as determining the number of agents involved, their interaction style, and task sequence, are still heavily reliant on manual configuration and trial-and-error. The design space is vast and nonlinear, as it combines numerous options for both prompt engineering and topology construction. Optimizing both simultaneously has been largely out of reach for traditional design methods. Several efforts have been made to improve various aspects of this design problem, but gaps remain. Methods like DSPy automate exemplar generation for prompts, while others focus on increasing the number of agents participating in tasks like voting. Tools like ADAS introduce code-based topological configurations through meta-agents. Some frameworks, such as AFlow, apply techniques like Monte Carlo Tree Search to explore combinations more efficiently. Yet, these solutions generally concentrate on either prompt or topology optimization, rather than both. This lack of integration limits their ability to generate MAS designs that are both intelligent and robust under complex operational conditions. Researchers at Google and the University of Cambridge introduced a new framework named Multi-Agent System Search (Mass). This method automates MAS design by interleaving the optimization of both prompts and topologies in a staged approach. Unlike earlier attempts that treated the two components independently, Mass begins by identifying which elements, both prompts and topological structures, are most likely to influence performance. By narrowing the search to this influential subspace, the framework operates more efficiently while delivering higher-quality outcomes. The method progresses in three phases: localized prompt optimization, selection of effective workflow topologies based on the optimized prompts, and then global optimization of prompts at the system-wide level. The framework not only reduces computational overhead but also removes the burden of manual tuning from researchers. The technical implementation of Mass is structured and methodical. First, each building block of a MAS undergoes prompt refinement. These blocks are agent modules with specific responsibilities, such as aggregation, reflection, or debate. For example, prompt optimizers generate variations that include both instructional guidance (e.g., “think step by step”) and example-based learning (e.g., one-shot or few-shot demos). The optimizer evaluates these using a validation metric to guide improvements. Once each agent’s prompt is optimized locally, the system proceeds to explore valid combinations of agents to form topologies. This topology optimization is informed by earlier results and constrained to a pruned search space identified as most influential. Finally, the best topology undergoes global-level prompt tuning, where instructions are fine-tuned in the context of the entire workflow to maximize collective efficiency. In tasks such as reasoning, multi-hop understanding, and code generation, the optimized MAS consistently surpassed existing benchmarks. In performance testing using Gemini 1.5 Pro on the MATH dataset, prompt-optimized agents showed an average accuracy of around 84% with enhanced prompting techniques, compared to 76–80% for agents scaled through self-consistency or multi-agent debate. In the HotpotQA benchmark, using the debate topology within Mass yielded a 3% improvement. In contrast, other topologies, such as reflect or summarize, failed to yield gains or even led to a 15% degradation. On LiveCodeBench, the Executor topology provided a +6% boost, but methods like reflection again saw negative results. These findings validate that only a fraction of the topological design space contributes positively and reinforce the need for targeted optimization, such as that used in Mass. Several Key Takeaways from the Research include: MAS design complexity is significantly influenced by prompt sensitivity and topological arrangement. Prompt optimization, both at the block and system level, is more effective than agent scaling alone, as evidenced by the 84% accuracy with enhanced prompts versus 76% with self-consistency scaling. Not all topologies are beneficial; debate added +3% in HotpotQA, while reflection caused a drop of up to -15%. The Mass framework integrates prompt and topology optimization in three phases, drastically reducing computational and design burden. Topologies like debate and executor are effective, while others, such as reflect and summarize, can degrade system performance. Mass avoids full search complexity by pruning the design space based on early influence analysis, improving performance while saving resources. The approach is modular and supports plug-and-play agent configurations, making it adaptable to various domains and tasks. Final MAS models from Mass outperform state-of-the-art baselines across multiple benchmarks like MATH, HotpotQA, and LiveCodeBench. In conclusion, this research identifies prompt sensitivity and topology complexity as major bottlenecks in multi-agent system (MAS) development and proposes a structured solution that strategically optimizes both areas. The Mass framework demonstrates a scalable, efficient approach to MAS design, minimizing the need for human input while maximizing performance. The research presents compelling evidence that better prompt design is more effective than merely adding agents and that targeted search within influential topology subsets leads to meaningful gains in real-world tasks. Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter. The post Google AI