

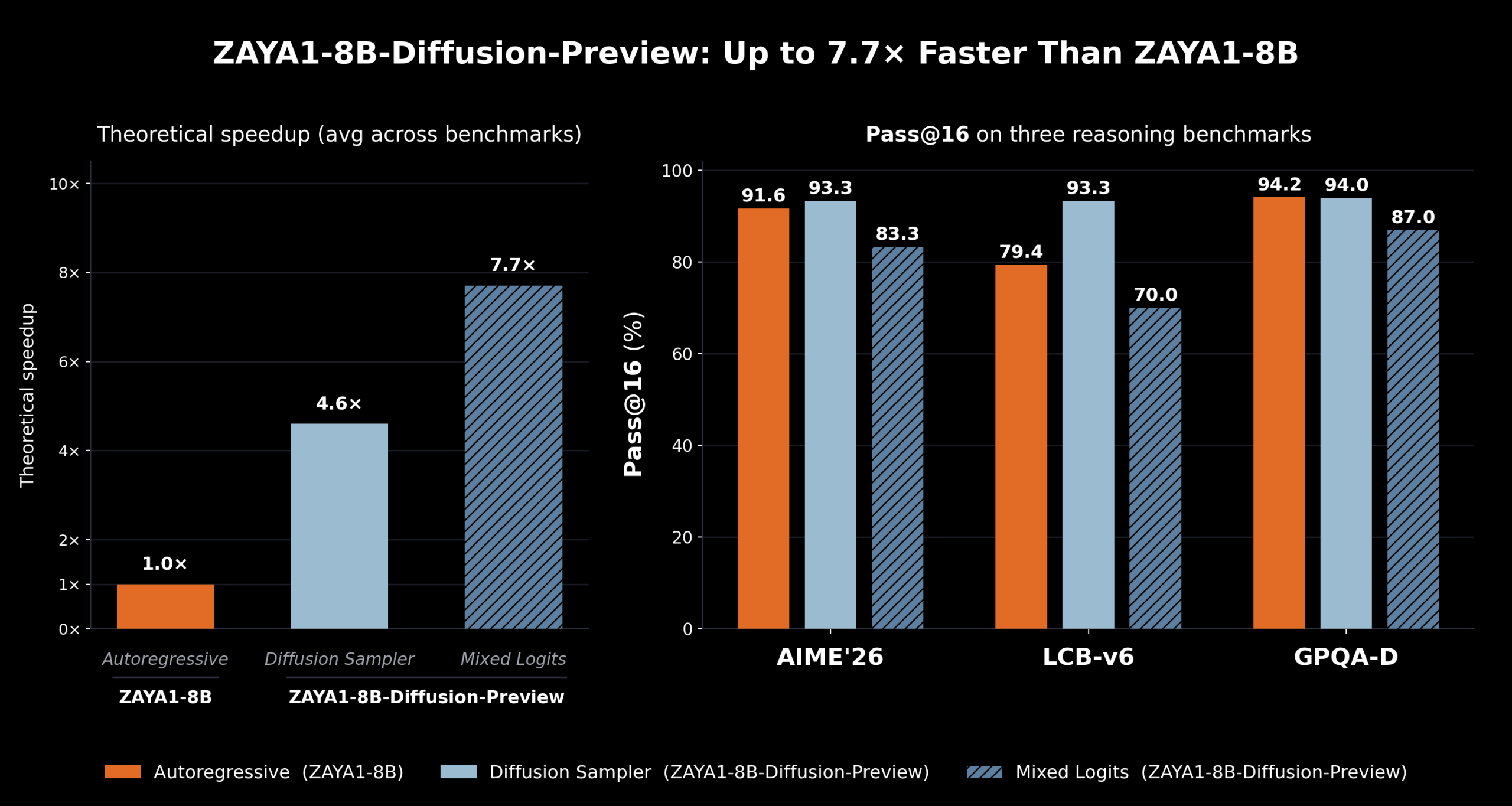
Zyphra Releases ZAYA1-8B-Diffusion-Preview: The First MoE Diffusion Model Converted From an Autoregressive LLM With Up to 7.7x Speedup
Zyphra, the San Francisco-based AI lab behind the ZAYA1 model family, released ZAYA1-8B-Diffusion-Preview — a...
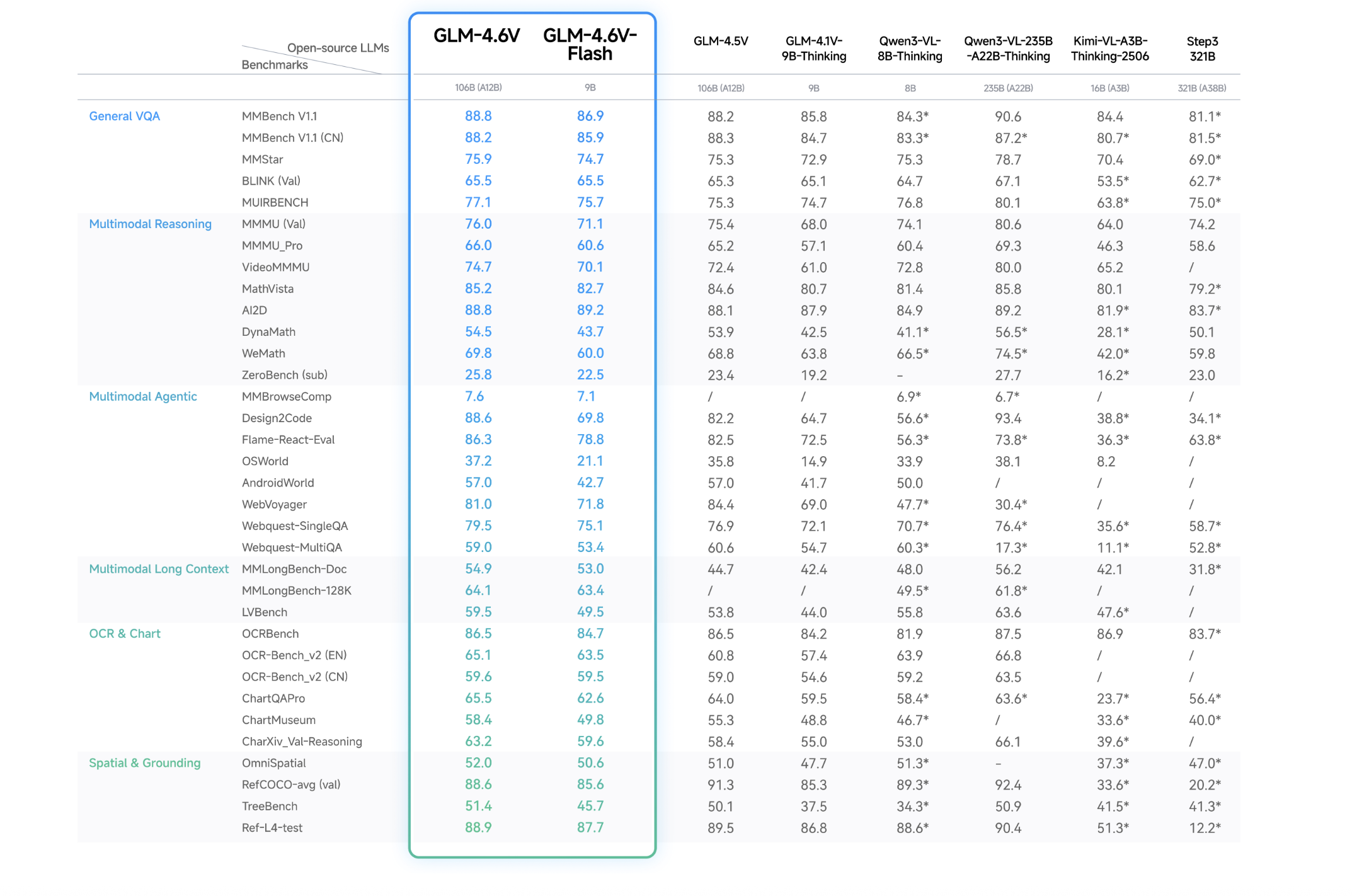
Zhipu AI Releases GLM-4.6V: A 128K Context Vision Language Model with Native Tool Calling
Zhipu AI has open sourced the GLM-4.6V series as a pair of vision language models...

Zhipu AI Introduces GLM-OCR: A 0.9B Multimodal OCR Model for Document Parsing and Key Information Extraction (KIE)
Why Document OCR Still Remains a Hard Engineering Problem? What does it take to make...
ZeroSearch: Incentivize the Search Capability of LLMs without Searching
arXiv:2505.04588v1 Announce Type: new Abstract: Effective information searching is essential for enhancing the reasoning and...
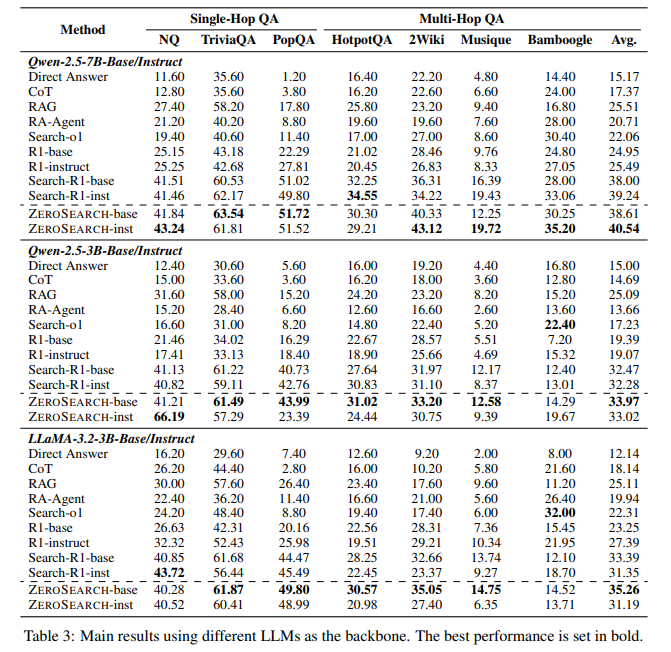
ZeroSearch from Alibaba Uses Reinforcement Learning and Simulated Documents to Teach LLMs Retrieval Without Real-Time Search
Large language models are now central to various applications, from coding to academic tutoring and...
Zero-Shot Tokenizer Transfer
arXiv:2405.07883v2 Announce Type: replace Abstract: Language models (LMs) are bound to their tokenizer, which maps...
Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning
arXiv:2507.16746v2 Announce Type: replace-cross Abstract: Humans often use visual aids, for example diagrams or sketches...
Z.AI Introduces GLM-5.1: An Open-Weight 754B Agentic Model That Achieves SOTA on SWE-Bench Pro and Sustains 8-Hour Autonomous Execution
Z.AI, the AI platform developed by the team behind the GLM model family, has released...

YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency
How can a trillion-parameter Large Language Model achieve state-of-the-art enterprise performance while simultaneously cutting its...

Your AI models are failing in production—Here’s how to fix model selection
The Allen Institute of AI updated its reward model evaluation RewardBench to better reflect real-life...
You have no choice in reading this article—maybe
Uri Maoz loved doing his human research, back when he was getting his PhD. He...
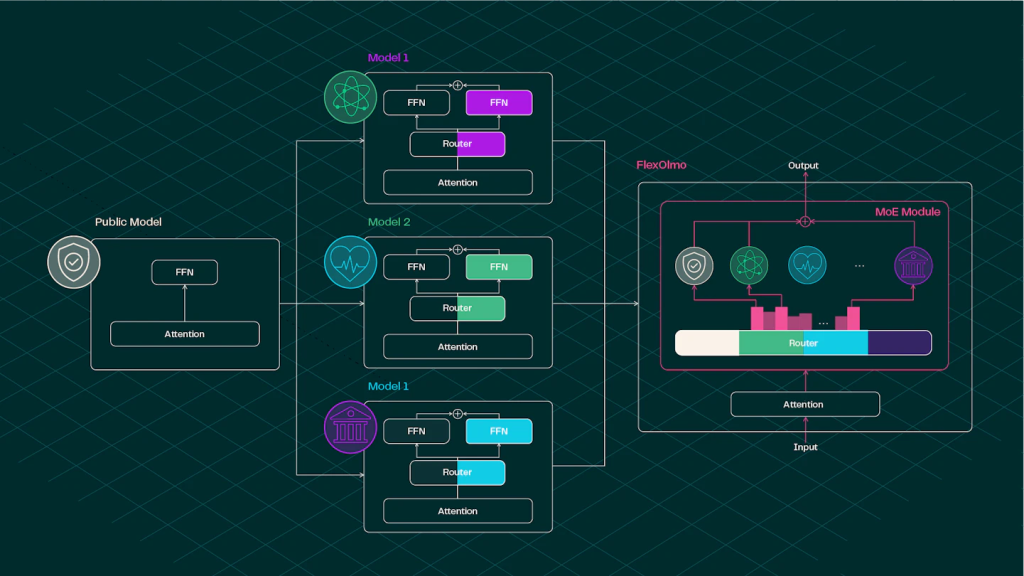
You Don’t Need to Share Data to Train a Language Model Anymore—FlexOlmo Demonstrates How
The development of large-scale language models (LLMs) has historically required centralized access to extensive datasets...