

Pre-trained Transformer-Based Approach for Arabic Question Answering : A Comparative Study
arXiv:2111.05671v2 Announce Type: replace Abstract: Question answering(QA) is one of the most challenging yet widely...
Pragmatic Reasoning improves LLM Code Generation
arXiv:2502.15835v3 Announce Type: replace Abstract: Large Language Models (LLMs) have demonstrated impressive potential in translating...
Post-LayerNorm Is Back: Stable, ExpressivE, and Deep
arXiv:2601.19895v1 Announce Type: cross Abstract: Large language model (LLM) scaling is hitting a wall. Widening...
Pose-Based Sign Language Appearance Transfer
arXiv:2410.13675v2 Announce Type: replace-cross Abstract: We introduce a method for transferring the signer’s appearance in...
Political Leaning and Politicalness Classification of Texts
arXiv:2507.13913v1 Announce Type: new Abstract: This paper addresses the challenge of automatically classifying text according...
PoE-World + Planner Outperforms Reinforcement Learning RL Baselines in Montezuma’s Revenge with Minimal Demonstration Data
The Importance of Symbolic Reasoning in World Modeling Understanding how the world works is key...
PLAN-TUNING: Post-Training Language Models to Learn Step-by-Step Planning for Complex Problem Solving
arXiv:2507.07495v1 Announce Type: new Abstract: Recently, decomposing complex problems into simple subtasks–a crucial part of...
PhysicsEval: Inference-Time Techniques to Improve the Reasoning Proficiency of Large Language Models on Physics Problems
arXiv:2508.00079v2 Announce Type: replace Abstract: The discipline of physics stands as a cornerstone of human...
Phonetic accommodation and inhibition in a dynamic neural field model
arXiv:2502.01210v2 Announce Type: replace Abstract: Short-term phonetic accommodation is a fundamental driver behind accent change...

Phonely’s new AI agents hit 99% accuracy—and customers can’t tell they’re not human
Phonely, Maitai and Groq achieve breakthrough in AI phone support with sub-second response times and...
Phantom: General Backdoor Attacks on Retrieval Augmented Language Generation
arXiv:2405.20485v3 Announce Type: replace-cross Abstract: Retrieval Augmented Generation (RAG) expands the capabilities of modern large...
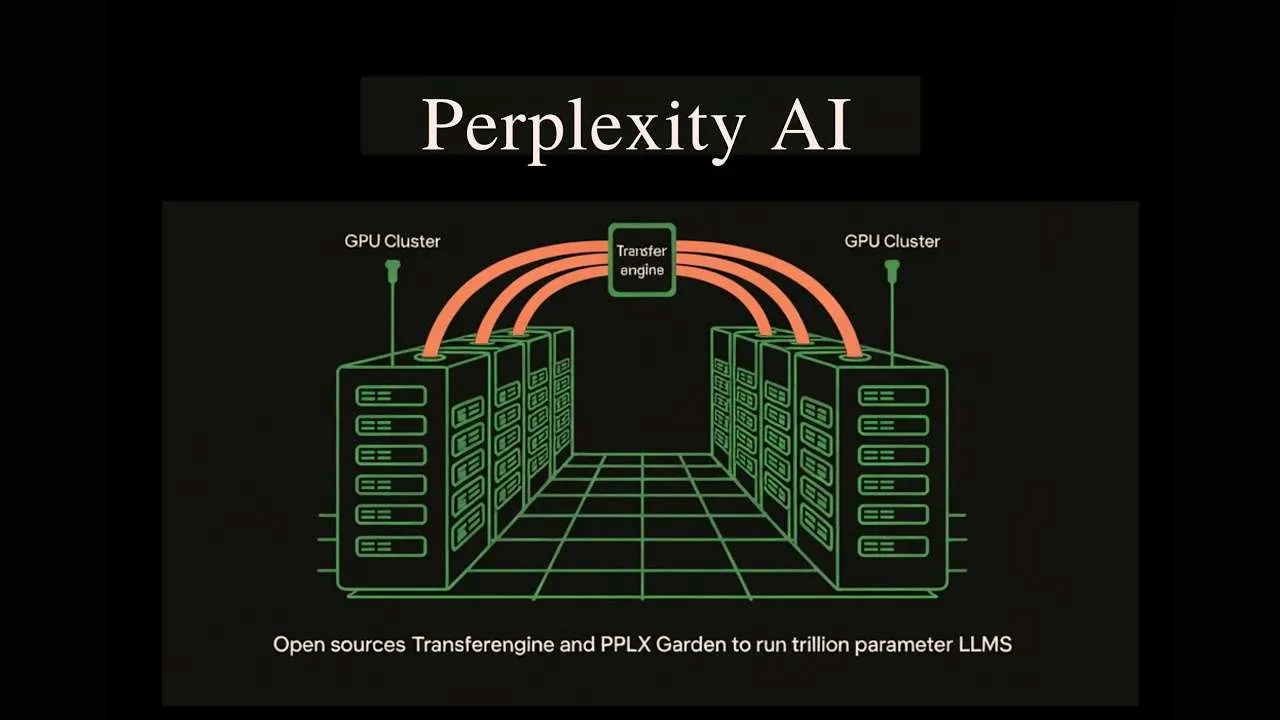
Perplexity AI Releases TransferEngine and pplx garden to Run Trillion Parameter LLMs on Existing GPU Clusters
How can teams run trillion parameter language models on existing mixed GPU clusters without costly...