

Simulated Reasoning is Reasoning
arXiv:2601.02043v1 Announce Type: cross Abstract: Reasoning has long been understood as a pathway between stages...
SimpleDeepSearcher: Deep Information Seeking via Web-Powered Reasoning Trajectory Synthesis
arXiv:2505.16834v3 Announce Type: replace Abstract: Retrieval-augmented generation (RAG) systems have advanced large language models (LLMs)...
Similarity-Distance-Magnitude Activations
arXiv:2509.12760v2 Announce Type: replace-cross Abstract: We introduce the Similarity-Distance-Magnitude (SDM) activation function, a more robust...
SignX: Continuous Sign Recognition in Compact Pose-Rich Latent Space
arXiv:2504.16315v3 Announce Type: replace-cross Abstract: The complexity of sign language data processing brings many challenges...
SignRAG: A Retrieval-Augmented System for Scalable Zero-Shot Road Sign Recognition
arXiv:2512.12885v1 Announce Type: cross Abstract: Automated road sign recognition is a critical task for intelligent...
SIGMA: Search-Augmented On-Demand Knowledge Integration for Agentic Mathematical Reasoning
arXiv:2510.27568v1 Announce Type: cross Abstract: Solving mathematical reasoning problems requires not only accurate access to...

Shrink exploit windows, slash MTTP: Why ring deployment is now a must for enterprise defense
Ring deployment slashes MTTP and legacy CVE risk. Learn how Ivanti and Southstar Bank are...
ShareChat: A Dataset of Chatbot Conversations in the Wild
arXiv:2512.17843v2 Announce Type: replace Abstract: While academic research typically treats Large Language Models (LLM) as...
SGPO: Self-Generated Preference Optimization based on Self-Improver
arXiv:2507.20181v1 Announce Type: new Abstract: Large language models (LLMs), despite their extensive pretraining on diverse...
SFT Doesn’t Always Hurt General Capabilities: Revisiting Domain-Specific Fine-Tuning in LLMs
arXiv:2509.20758v3 Announce Type: replace Abstract: Supervised Fine-Tuning (SFT) on domain-specific datasets is a common approach...
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
arXiv:2507.20185v1 Announce Type: new Abstract: Session history is a common way of recording user interacting...
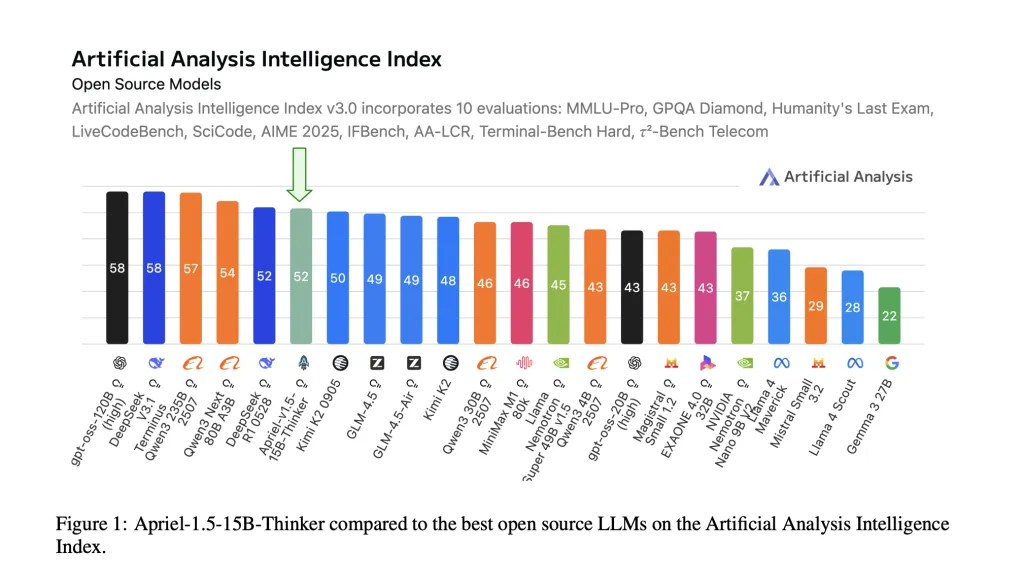
ServiceNow AI Releases Apriel-1.5-15B-Thinker: An Open-Weights Multimodal Reasoning Model that Hits Frontier-Level Performance on a Single-GPU Budget
ServiceNow AI Research Lab has released Apriel-1.5-15B-Thinker, a 15-billion-parameter open-weights multimodal reasoning model trained with...