


Researchers from the National University of Singapore Introduce ‘Thinkless,’ an Adaptive Framework that Reduces Unnecessary Reasoning by up to 90% Using DeGRPO
The effectiveness of language models relies on their ability to simulate human-like step-by-step deduction. However...
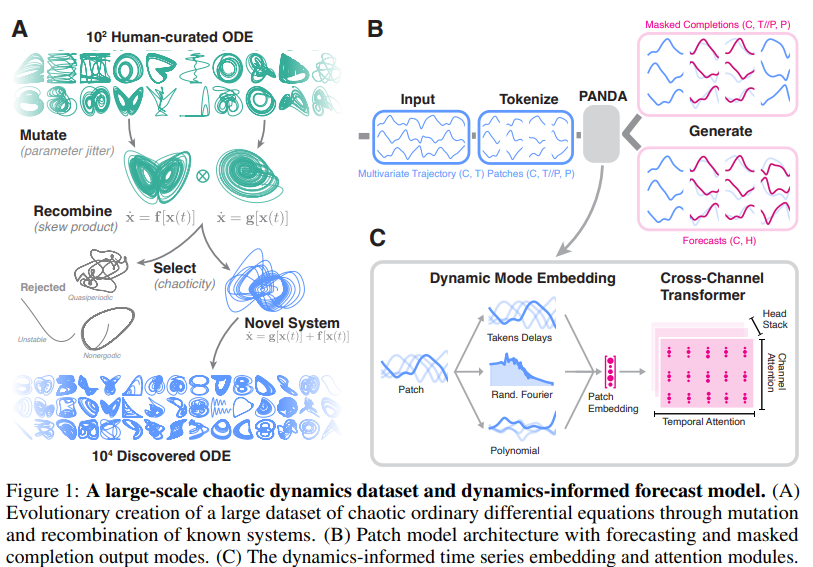
Researchers at UT Austin Introduce Panda: A Foundation Model for Nonlinear Dynamics Pretrained on 20,000 Chaotic ODE Discovered via Evolutionary Search
Chaotic systems, such as fluid dynamics or brain activity, are highly sensitive to initial conditions...
Research on the Integration of Embodied Intelligence and Reinforcement Learning in Textual Domains
arXiv:2510.01076v1 Announce Type: new Abstract: This article addresses embodied intelligence and reinforcement learning integration in...
Research on Multi-hop Inference Optimization of LLM Based on MQUAKE Framework
arXiv:2509.04770v1 Announce Type: new Abstract: Accurately answering complex questions has consistently been a significant challenge...
Representation Decomposition for Learning Similarity and Contrastness Across Modalities for Affective Computing
arXiv:2506.07086v1 Announce Type: new Abstract: Multi-modal affective computing aims to automatically recognize and interpret human...
REPA: Russian Error Types Annotation for Evaluating Text Generation and Judgment Capabilities
arXiv:2503.13102v2 Announce Type: replace Abstract: Recent advances in large language models (LLMs) have introduced the...
Remember Past, Anticipate Future: Learning Continual Multimodal Misinformation Detectors
arXiv:2507.05939v1 Announce Type: new Abstract: Nowadays, misinformation articles, especially multimodal ones, are widely spread on...
Reliably Bounding False Positives: A Zero-Shot Machine-Generated Text Detection Framework via Multiscaled Conformal Prediction
arXiv:2505.05084v2 Announce Type: replace Abstract: The rapid advancement of large language models has raised significant...
Release Note May 16, 2025
Added new features to the FORM page Updated pricing information on the pricing page Improved...

Release Note May 16, 2025
– Added new features to the FORM page – Updated pricing information on the pricing...
Reinforcement Learning Teachers of Test Time Scaling
arXiv:2506.08388v2 Announce Type: replace-cross Abstract: Training reasoning language models (LMs) with reinforcement learning (RL) for...
Reinforcement Learning on Pre-Training Data
arXiv:2509.19249v2 Announce Type: replace Abstract: The growing disparity between the exponential scaling of computational resources...