

Improving Detection of Watermarked Language Models
arXiv:2508.13131v1 Announce Type: new Abstract: Watermarking has recently emerged as an effective strategy for detecting...
Improving Data and Reward Design for Scientific Reasoning in Large Language Models
arXiv:2602.08321v1 Announce Type: new Abstract: Solving open-ended science questions remains challenging for large language models...
Improved Personalized Headline Generation via Denoising Fake Interests from Implicit Feedback
arXiv:2508.07178v1 Announce Type: new Abstract: Accurate personalized headline generation hinges on precisely capturing user interests...

Implementing Statistical Guardrails for Non-Deterministic Agents
Non-deterministic agents are those where the same input can lead to distinct outputs across multiple...
Implementing Prompt Compression to Reduce Agentic Loop Costs
Agentic loops in production can be synonymous with high costs, especially when it comes to...
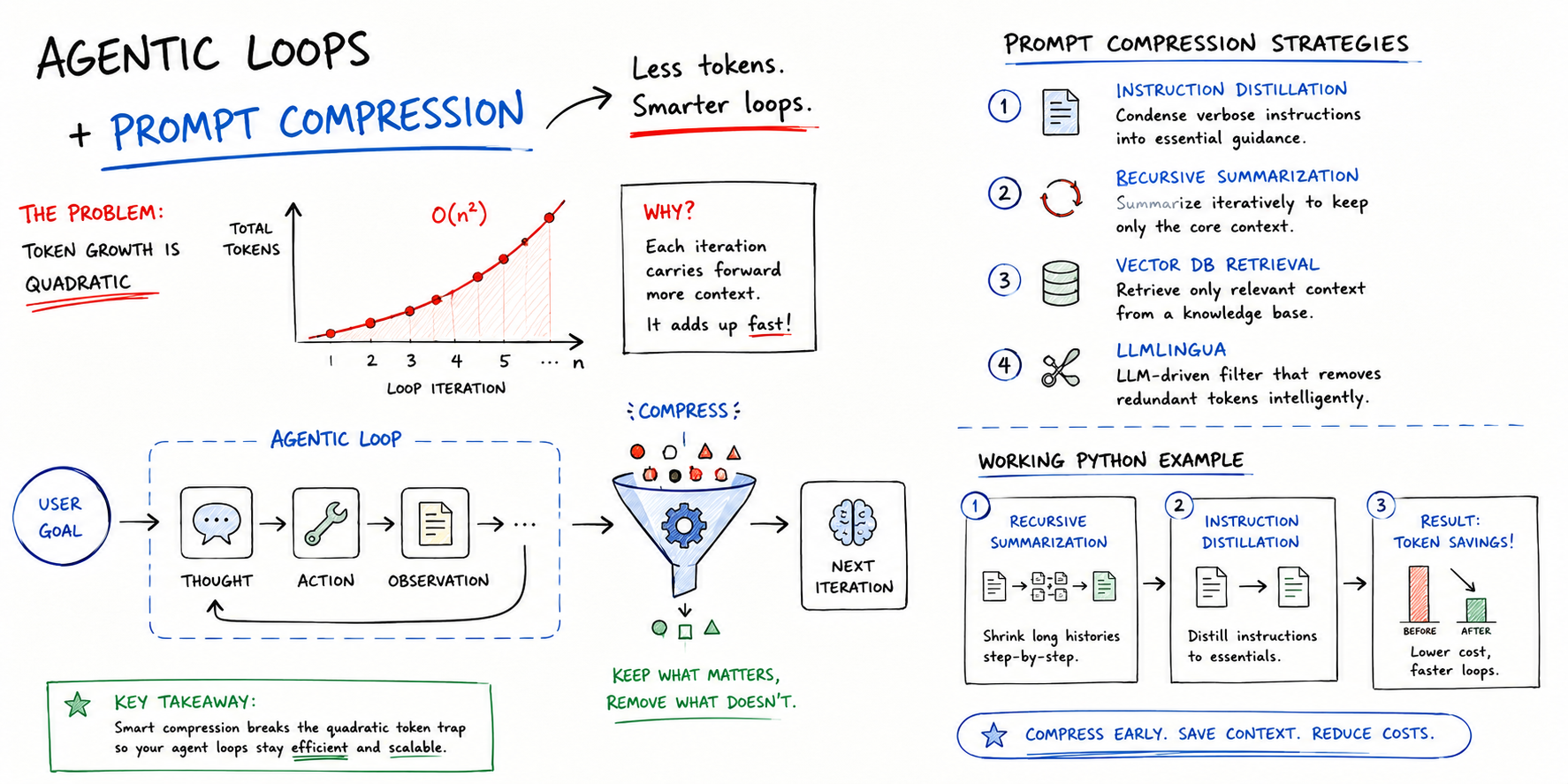
Implementing Prompt Compression to Reduce Agentic Loop Costs
Agentic loops in production can be synonymous with high costs, especially when it comes to...

Implementing Permission-Gated Tool Calling in Python Agents
AI agents have evolved beyond passive chatbots...

Implementing Hybrid Semantic-Lexical Search in RAG
Implementing hybrid search strategies is a critical step in building modern RAG (Retrieval-Augmented Generation) systems...
Implementing Hybrid Semantic-Lexical Search in RAG
Implementing hybrid search strategies is a critical step in building modern RAG (Retrieval-Augmented Generation) systems...
Implementing DeepSpeed for Scalable Transformers: Advanced Training with Gradient Checkpointing and Parallelism
In this advanced DeepSpeed tutorial, we provide a hands-on walkthrough of cutting-edge optimization techniques for...

Implementing advanced AI technologies in finance
In finance departments that have long been defined by precision and control, AI has arrived...
Impact of Stickers on Multimodal Sentiment and Intent in Social Media: A New Task, Dataset and Baseline
arXiv:2405.08427v2 Announce Type: replace Abstract: Stickers are increasingly used in social media to express sentiment...