
Mistral launches new code embedding model that outperforms OpenAI and Cohere in real-world retrieval tasks
Mistral’s Codestral Embed will help make RAG use cases faster and find duplicate code segments using natural language.Read More


Mistral’s Codestral Embed will help make RAG use cases faster and find duplicate code segments using natural language.Read More

Agentic AI played a decisive role in dismantling DanaBot, a Russian malware platform responsible for more than 50 million dollars in damages.Read More
DanaBot takedown shows how agentic AI cut months of SOC analysis to weeks Read Post »

Fearing sweeping layoffs driven by AI and automation, elite consultants and high performers are turning to shadow AI for a competitive edge.Read More
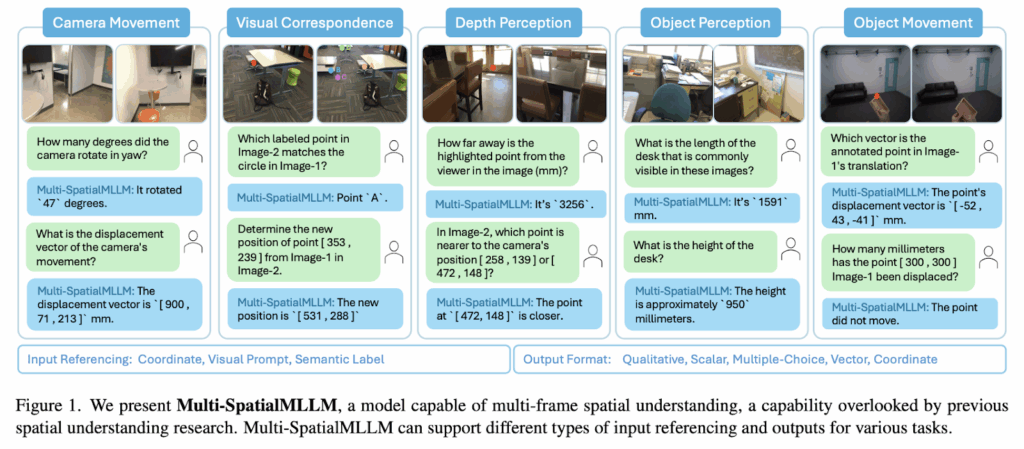
Multi-modal large language models (MLLMs) have shown great progress as versatile AI assistants capable of handling diverse visual tasks. However, their deployment as isolated digital entities limits their potential impact. The growing demand to integrate MLLMs into real-world applications like robotics and autonomous vehicles requires complex spatial understanding. Current MLLMs show fundamental spatial reasoning deficiencies, often failing at basic tasks such as distinguishing left from right. While previous research attributes these limitations to insufficient specialized training data and solves them through spatial data incorporation during training, these approaches focus on single-image scenarios, thus restricting the model’s perception to static field-of-view analysis without dynamic information. Several research methods have tried to address spatial understanding limitations in MLLMs. MLLMs incorporate image encoders that convert visual inputs into tokens processed alongside text in the language model’s latent space. Previous research has focused on single-image spatial understanding, evaluating inter-object spatial relations, or spatial recognition. Some benchmarks like BLINK, UniQA-3D, and VSIBench extend beyond single images. Existing improvements of MLLMs for spatial understanding include SpatialVLM, which fine-tunes models on curated spatial datasets, SpatialRGPT, which incorporates mask-based references and depth images, and SpatialPIN, which utilizes specialized perception models without fine-tuning. Researchers from FAIR Meta and the Chinese University of Hong Kong have proposed a framework to enhance MLLMs with robust multi-frame spatial understanding. This integrates three components: depth perception, visual correspondence, and dynamic perception to overcome the limitations of static single-image analysis. Researchers develop MultiSPA, a novel large-scale dataset containing over 27 million samples spanning diverse 3D and 4D scenes. The resulting Multi-SpatialMLLM model achieves significant improvements over baselines and proprietary systems, with scalable and generalizable multi-frame reasoning. Further, five tasks are introduced to generate training data: depth perception, visual correspondence, camera movement perception, object movement perception, and object size perception. The Multi-SpatialMLLM centers around the MultiSPA data generation pipeline and comprehensive benchmark system. The data format follows standard MLLM fine-tuning strategies, which have the format of QA pairs: User: <image>…<image>{description}{question} and Assistant: {answer}. Researchers used the GPT-4o to generate diverse templates for task descriptions, questions, and answers. Further, high-quality annotated scene datasets are used, including 4D datasets Aria Digital Twin and Panoptic Studio, along with 3D tracking annotations from TAPVid3D for object movement perception and ScanNet for other spatial tasks. The MultiSPA generates over 27M QA samples from 1.1M unique images, with 300 samples held out for each subtask evaluation, totaling 7,800 benchmark samples. On the MultiSPA benchmark, the Multi-SpatialMLLM achieves an average 36% gain over base models, reaching 80-90% accuracy on qualitative tasks compared to 50% for baseline models while outperforming all proprietary systems. Even on challenging tasks like predicting camera movement vectors, it attains 18% accuracy versus near-zero performance from other baselines. On the BLINK benchmark, Multi-SpatialMLLM achieves nearly 90% accuracy with an average 26.4% improvement over base models, surpassing several proprietary systems and showing transferable multi-frame spatial understanding. Standard VQA benchmark evaluations show rough parity with original performance, indicating the model maintains general-purpose MLLM proficiency without overfitting to spatial reasoning tasks. In this paper, researchers extend MLLMs’ spatial understanding to multi-frame scenarios, addressing a critical gap overlooked in previous investigations. They introduced MultiSPA, the first large-scale dataset and benchmark for multi-frame spatial reasoning tasks. Experimental validation shows the effectiveness, scalability, and strong generalization capabilities of the proposed Multi-SpatialMLLM across diverse spatial understanding challenges. The research reveals significant insights, including multi-task learning benefits and emergent behaviors in complex spatial reasoning. The model establishes new applications, including acting as a multi-frame reward annotator. Check out the Paper, Project Page and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter. The post Meta AI Introduces Multi-SpatialMLLM: A Multi-Frame Spatial Understanding with Multi-modal Large Language Models appeared first on MarkTechPost.

With the rollout of voice mode, Anthropic continues to broaden Claude’s functionality and accessibility to all users.Read More

Spott secures $3.2 million in funding to build an all-in-one AI-native recruitment platform that automates workflows and eliminates tech fragmentation for recruitment agencies seeking to focus on high-value activities.Read More
Spott’s AI-native recruiting platform scores $3.2M to end hiring software chaos Read Post »

Google is looking to compete in vibe coding with Stitch, which designs user interfaces (UIs) with one prompt. Read More

Learning machine learning can be challenging.
Using NotebookLM as Your Machine Learning Study Guide Read Post »

We are beginning a cognitive migration: Away from what AI now does well, and toward a redefinition of what humans are now made for.Read More
From disruption to reinvention: How knowledge workers can thrive after AI Read Post »
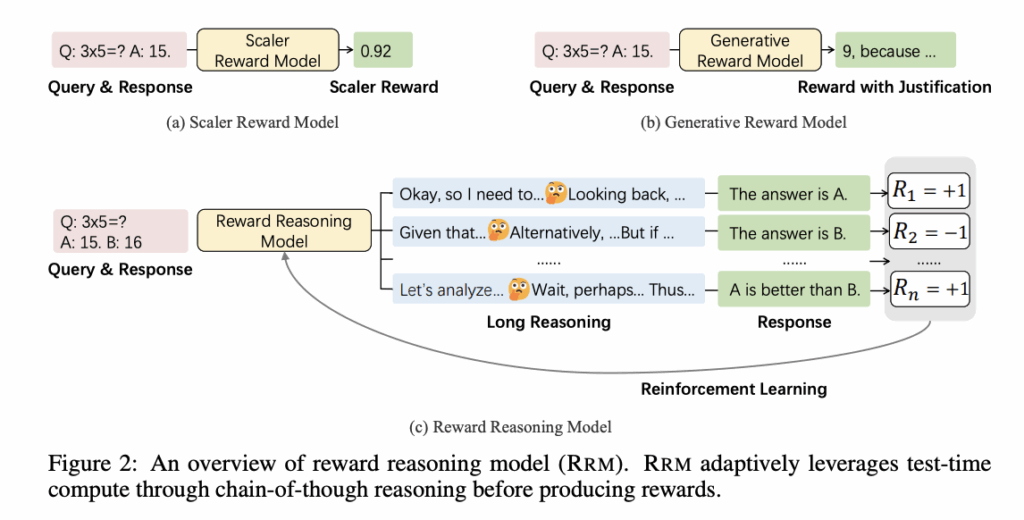
Reinforcement learning (RL) has emerged as a fundamental approach in LLM post-training, utilizing supervision signals from human feedback (RLHF) or verifiable rewards (RLVR). While RLVR shows promise in mathematical reasoning, it faces significant constraints due to dependence on training queries with verifiable answers. This requirement limits applications to large-scale training on general-domain queries where verification proves intractable. Further, current reward models, categorized into scalar and generative types, cannot effectively scale test-time compute for reward estimation. Existing approaches apply uniform computational resources across all inputs, lacking adaptability to allocate additional resources to challenging queries requiring nuanced analysis. Formulation strategies and scoring schemes characterize reward models. Numeric approaches assign scalar scores to query-response pairs, while generative methods produce natural language feedback. Scoring follows absolute evaluation of individual pairs or discriminative comparison of candidate responses. Generative reward models, aligned with the LLM-as-a-Judge paradigm, offer interpretable feedback but face reliability concerns due to biased judgments. Inference-time scaling methods dynamically adjust computational resources, including parallel strategies like multi-sampling and horizon-based scaling for extended reasoning traces. However, they lack systematic adaptation to input complexity, limiting their effectiveness across diverse query types. Researchers from Microsoft Research, Tsinghua University, and Peking University have proposed Reward Reasoning Models (RRMs), which perform explicit reasoning before producing final rewards. This reasoning phase allows RRMs to adaptively allocate additional computational resources when evaluating responses to complex tasks. RRMs introduce a dimension for enhancing reward modeling by scaling test-time compute while maintaining general applicability across diverse evaluation scenarios. Through chain-of-thought reasoning, RRMs utilize additional test-time compute for complex queries where appropriate rewards are not immediately apparent. This encourages RRMs to self-evolve reward reasoning capabilities without explicit reasoning traces as training data. RRMs utilize the Qwen2 model with a Transformer-decoder backbone, formulating reward modeling as text completion where RRMs autoregressively generate thinking processes followed by final judgments. Each input contains a query and two responses to determine preference without allowing ties. Researchers use the RewardBench repository to guide systematic analysis across evaluation criteria, including instruction fidelity, helpfulness, accuracy, harmlessness, and detail level. RRMs support multi-response evaluation through ELO rating systems and knockout tournaments, both combinable with majority voting for enhanced test-time compute utilization. This samples RRMs multiple times for pairwise comparisons, performing majority voting to obtain robust comparison results. Evaluation results show that RRMs achieve competitive performance against strong baselines on RewardBench and PandaLM Test benchmarks, with RRM-32B attaining 98.6% accuracy in reasoning categories. Comparing with DirectJudge models trained on identical data reveals substantial performance gaps, indicating RRMs effectively use test-time compute for complex queries. In reward-guided best-of-N inference, RRMs surpass all baseline models without additional test-time compute, with majority voting providing substantial improvements across evaluated subsets. Post-training experiments show steady downstream performance improvements on MMLU-Pro and GPQA. Scaling experiments across 7B, 14B, and 32B models confirm that longer thinking horizons consistently improve accuracy. In conclusion, researchers introduced RRMs to perform explicit reasoning processes before reward assignment to address computational inflexibility in existing reward modeling approaches. Rule-based-reward RL enables RRMs to develop complex reasoning capabilities without requiring explicit reasoning traces as supervision. RRMs efficiently utilize test-time compute through parallel and sequential scaling approaches. The effectiveness of RRMs in practical applications, including reward-guided best-of-N inference and post-training feedback, demonstrates their potential as strong alternatives to traditional scalar reward models in alignment techniques. Check out the Paper and Models on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter. The post Can LLMs Really Judge with Reasoning? Microsoft and Tsinghua Researchers Introduce Reward Reasoning Models to Dynamically Scale Test-Time Compute for Better Alignment appeared first on MarkTechPost.
We use cookies to improve your experience and performance on our website. You can learn more at นโยบายความเป็นส่วนตัว and manage your privacy settings by clicking Settings.