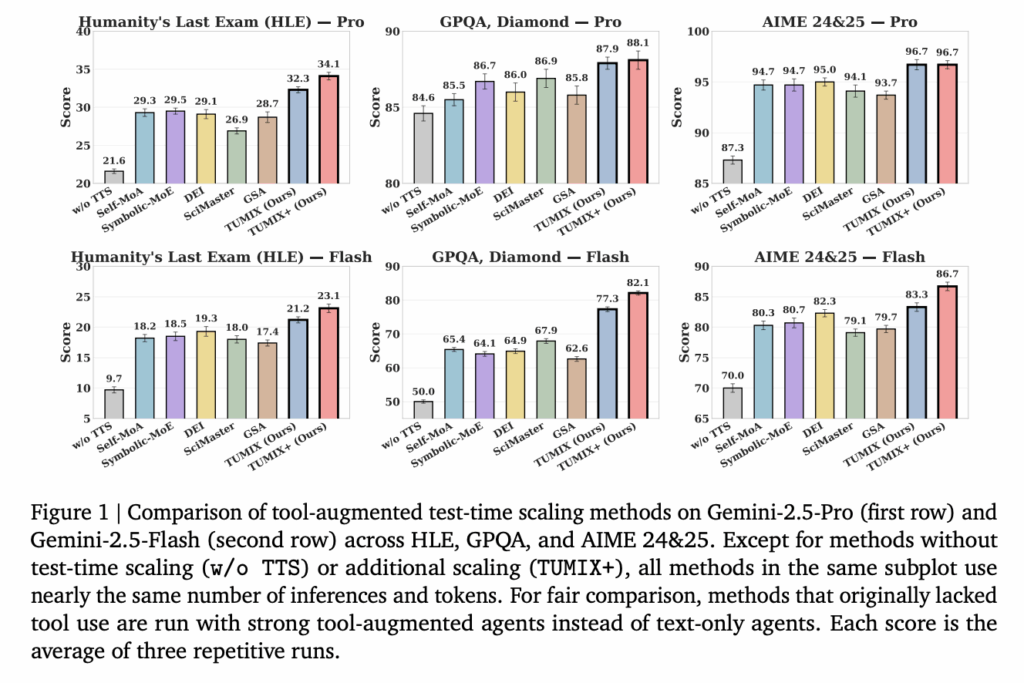
How to Evaluate Voice Agents in 2025: Beyond Automatic Speech Recognition (ASR) and Word Error Rate (WER) to Task Success, Barge-In, and Hallucination-Under-Noise
Table of contents Why WER Isn’t Enough ? What to Measure (and How) ? Benchmark Landscape: What Each Covers Filling the Gaps: What You Still Need to Add A Concrete, Reproducible Evaluation Plan References Optimizing only for Automatic Speech Recognition (ASR) and Word Error Rate (WER) is insufficient for modern, interactive voice agents. Robust evaluation must measure end-to-end task success, barge-in behavior and latency, and hallucination-under-noise—alongside ASR, safety, and instruction following. VoiceBench offers a multi-facet speech-interaction benchmark across general knowledge, instruction following, safety, and robustness to speaker/environment/content variations, but it does not cover barge-in or real-device task completion. SLUE (and Phase-2) target spoken language understanding (SLU); MASSIVE and Spoken-SQuAD probe multilingual and spoken QA; DSTC tracks add spoken, task-oriented robustness. Combine these with explicit barge-in/endpointing tests, user-centric task-success measurement, and controlled noise-stress protocols to obtain a complete picture. Why WER Isn’t Enough? WER measures transcription fidelity, not interaction quality. Two agents with similar WER can diverge widely in dialog success because latency, turn-taking, misunderstanding recovery, safety, and robustness to acoustic and content perturbations dominate user experience. Prior work on real systems shows the need to evaluate user satisfaction and task success directly—e.g., Cortana’s automatic online evaluation predicted user satisfaction from in-situ interaction signals, not only ASR accuracy. What to Measure (and How)? 1) End-to-End Task Success Metric: Task Success Rate (TSR) with strict success criteria per task (goal completion, constraints met), plus Task Completion Time (TCT) and Turns-to-Success.Why. Real assistants are judged by outcomes. Competitions like Alexa Prize TaskBot explicitly measured users’ ability to finish multi-step tasks (e.g., cooking, DIY) with ratings and completion. Protocol. Define tasks with verifiable endpoints (e.g., “assemble shopping list with N items and constraints”). Use blinded human raters and automatic logs to compute TSR/TCT/Turns. For multilingual/SLU coverage, draw task intents/slots from MASSIVE. 2) Barge-In and Turn-Taking Metrics: Barge-In Detection Latency (ms): time from user onset to TTS suppression. True/False Barge-In Rates: correct interruptions vs. spurious stops. Endpointing Latency (ms): time to ASR finalization after user stop. Why. Smooth interruption handling and fast endpointing determine perceived responsiveness. Research formalizes barge-in verification and continuous barge-in processing; endpointing latency continues to be an active area in streaming ASR. Protocol. Script prompts where the user interrupts TTS at controlled offsets and SNRs. Measure suppression and recognition timings with high-precision logs (frame timestamps). Include noisy/echoic far-field conditions. Classic and modern studies provide recovery and signaling strategies that reduce false barge-ins. 3) Hallucination-Under-Noise (HUN) Metric. HUN Rate: fraction of outputs that are fluent but semantically unrelated to the audio, under controlled noise or non-speech audio.Why. ASR and audio-LLM stacks can emit “convincing nonsense,” especially with non-speech segments or noise overlays. Recent work defines and measures ASR hallucinations; targeted studies show Whisper hallucinations induced by non-speech sounds. Protocol. Construct audio sets with additive environmental noise (varied SNRs), non-speech distractors, and content disfluencies. Score semantic relatedness (human judgment with adjudication) and compute HUN. Track whether downstream agent actions propagate hallucinations to incorrect task steps. 4) Instruction Following, Safety, and Robustness Metric Families. Instruction-Following Accuracy (format and constraint adherence). Safety Refusal Rate on adversarial spoken prompts. Robustness Deltas across speaker age/accent/pitch, environment (noise, reverb, far-field), and content noise (grammar errors, disfluencies). Why. VoiceBench explicitly targets these axes with spoken instructions (real and synthetic) spanning general knowledge, instruction following, and safety; it perturbs speaker, environment, and content to probe robustness. Protocol. Use VoiceBench for breadth on speech-interaction capabilities; report aggregate and per-axis scores. For SLU specifics (NER, dialog acts, QA, summarization), leverage SLUE and Phase-2. 5) Perceptual Speech Quality (for TTS and Enhancement) Metric. Subjective Mean Opinion Score via ITU-T P.808 (crowdsourced ACR/DCR/CCR).Why. Interaction quality depends on both recognition and playback quality. P.808 gives a validated crowdsourcing protocol with open-source tooling. Benchmark Landscape: What Each Covers VoiceBench (2024) Scope: Multi-facet voice assistant evaluation with spoken inputs covering general knowledge, instruction following, safety, and robustness across speaker/environment/content variations; uses both real and synthetic speech.Limitations: Does not benchmark barge-in/endpointing latency or real-world task completion on devices; focuses on response correctness and safety under variations. SLUE / SLUE Phase-2 Scope: Spoken language understanding tasks: NER, sentiment, dialog acts, named-entity localization, QA, summarization; designed to study end-to-end vs. pipeline sensitivity to ASR errors.Use: Great for probing SLU robustness and pipeline fragility in spoken settings. MASSIVE Scope: >1M virtual-assistant utterances across 51–52 languages with intents/slots; strong fit for multilingual task-oriented evaluation.Use: Build multilingual task suites and measure TSR/slot F1 under speech conditions (paired with TTS or read speech). Spoken-SQuAD / HeySQuAD and Related Spoken-QA Sets Scope: Spoken question answering to test ASR-aware comprehension and multi-accent robustness.Use: Stress-test comprehension under speech errors; not a full agent task suite. DSTC (Dialog System Technology Challenge) Tracks Scope: Robust dialog modeling with spoken, task-oriented data; human ratings alongside automatic metrics; recent tracks emphasize multilinguality, safety, and evaluation dimensionality.Use: Complementary for dialog quality, DST, and knowledge-grounded responses under speech conditions. Real-World Task Assistance (Alexa Prize TaskBot) Scope: Multi-step task assistance with user ratings and success criteria (cooking/DIY).Use: Gold-standard inspiration for defining TSR and interaction KPIs; the public reports describe evaluation focus and outcomes. Filling the Gaps: What You Still Need to Add Barge-In & Endpointing KPIsAdd explicit measurement harnesses. Literature offers barge-in verification and continuous processing strategies; streaming ASR endpointing latency remains an active research topic. Track barge-in detection latency, suppression correctness, endpointing delay, and false barge-ins. Hallucination-Under-Noise (HUN) ProtocolsAdopt emerging ASR-hallucination definitions and controlled noise/non-speech tests; report HUN rate and its impact on downstream actions. On-Device Interaction LatencyCorrelate user-perceived latency with streaming ASR designs (e.g., transducer variants); measure time-to-first-token, time-to-final, and local processing overhead. Cross-Axis Robustness MatricesCombine VoiceBench’s speaker/environment/content axes with your task suite (TSR) to expose failure surfaces (e.g., barge-in under far-field echo; task success at low SNR; multilingual slots under accent shift). Perceptual Quality for PlaybackUse ITU-T P.808 (with the open P.808 toolkit) to quantify user-perceived TTS quality in your end-to-end loop, not just ASR. A Concrete, Reproducible Evaluation Plan Assemble the Suite Speech-Interaction Core: VoiceBench for knowledge, instruction following, safety, and robustness axes. SLU Depth: SLUE/Phase-2 tasks (NER, dialog acts,