

Large language models (LLMs) very often generate “hallucinations”—confident yet incorrect outputs that appear plausible. Despite improvements in training methods and architectures, hallucinations persist. A new research from OpenAI provides a rigorous explanation: hallucinations stem from statistical properties of supervised versus self-supervised learning, and their persistence is reinforced by misaligned evaluation benchmarks.
What Makes Hallucinations Statistically Inevitable?
The research team explains hallucinations as errors inherent to generative modeling. Even with perfectly clean training data, the cross-entropy objective used in pretraining introduces statistical pressures that produce errors.
The research team reduce the problem to a supervised binary classification task called Is-It-Valid (IIV): determining whether a model’s output is valid or erroneous. They prove that the generative error rate of an LLM is at least twice its IIV misclassification rate. In other words, hallucinations occur for the same reasons misclassifications appear in supervised learning: epistemic uncertainty, poor models, distribution shift, or noisy data.
Why Do Rare Facts Trigger More Hallucinations?
One major driver is the singleton rate—the fraction of facts that appear only once in training data. By analogy to Good–Turing missing-mass estimation, if 20% of facts are singletons, at least 20% of them will be hallucinated. This explains why LLMs answer reliably about widely repeated facts (e.g., Einstein’s birthday) but fail on obscure or rarely mentioned ones.
Can Poor Model Families Lead to Hallucinations?
Yes. Hallucinations also emerge when the model class cannot adequately represent a pattern. Classic examples include n-gram models generating ungrammatical sentences, or modern tokenized models miscounting letters because characters are hidden inside subword tokens. These representational limits cause systematic errors even when the data itself is sufficient.
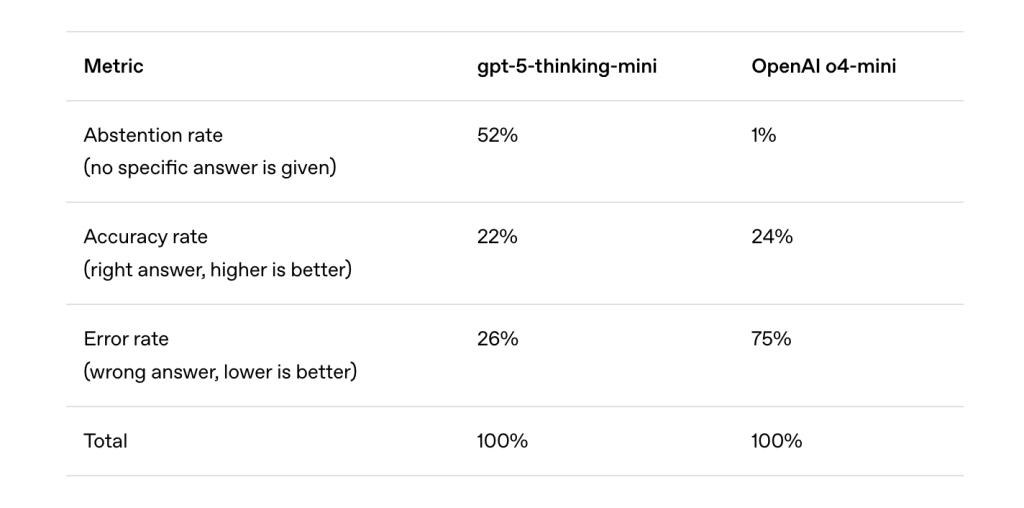
Why Doesn’t Post-Training Eliminate Hallucinations?
Post-training methods such as RLHF (reinforcement learning from human feedback), DPO, and RLAIF reduce some errors, especially harmful or conspiratorial outputs. But overconfident hallucinations remain because evaluation incentives are misaligned.
Like students guessing on multiple-choice exams, LLMs are rewarded for bluffing when unsure. Most benchmarks—such as MMLU, GPQA, and SWE-bench—apply binary scoring: correct answers get credit, abstentions (“I don’t know”) get none, and incorrect answers are penalized no more harshly than abstentions. Under this scheme, guessing maximizes benchmark scores, even if it fosters hallucinations.
How Do Leaderboards Reinforce Hallucinations?
A review of popular benchmarks shows that nearly all use binary grading with no partial credit for uncertainty. As a result, models that truthfully express uncertainty perform worse than those that always guess. This creates systemic pressure for developers to optimize models for confident answers rather than calibrated ones.
What Changes Could Reduce Hallucinations?
The research team argue that fixing hallucinations requires socio-technical change, not just new evaluation suites. They propose explicit confidence targets: benchmarks should clearly specify penalties for wrong answers and partial credit for abstentions.
For example: “Answer only if you are >75% confident. Mistakes lose 2 points; correct answers earn 1; ‘I don’t know’ earns 0.”
This design mirrors real-world exams like earlier SAT and GRE formats, where guessing carried penalties. It encourages behavioral calibration—models abstain when their confidence is below the threshold, producing fewer overconfident hallucinations while still optimizing for benchmark performance.
What Are the Broader Implications?
This work reframes hallucinations as predictable outcomes of training objectives and evaluation misalignment rather than inexplicable quirks. The findings highlight:
- Pretraining inevitability: Hallucinations parallel misclassification errors in supervised learning.
- Post-training reinforcement: Binary grading schemes incentivize guessing.
- Evaluation reform: Adjusting mainstream benchmarks to reward uncertainty can realign incentives and improve trustworthiness.
By connecting hallucinations to established learning theory, the research demystifies their origin and suggests practical mitigation strategies that shift responsibility from model architectures to evaluation design.
Check out the PAPER and Technical details here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post From Pretraining to Post-Training: Why Language Models Hallucinate and How Evaluation Methods Reinforce the Problem appeared first on MarkTechPost.