

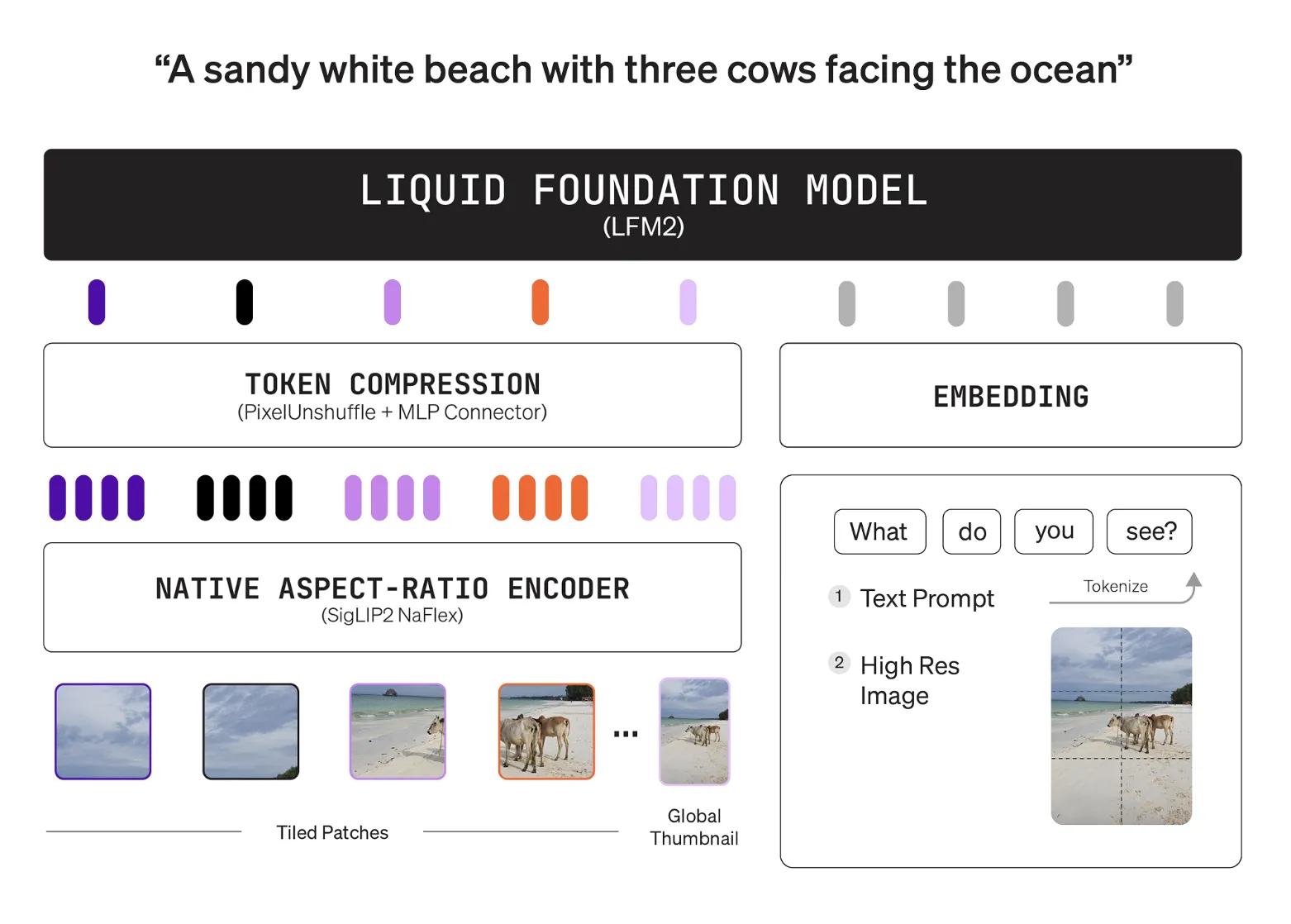
Liquid AI’s LFM2-VL-3B Brings a 3B Parameter Vision Language Model (VLM) to Edge-Class Devices
Liquid AI released LFM2-VL-3B, a 3B parameter vision language model for image text to text...
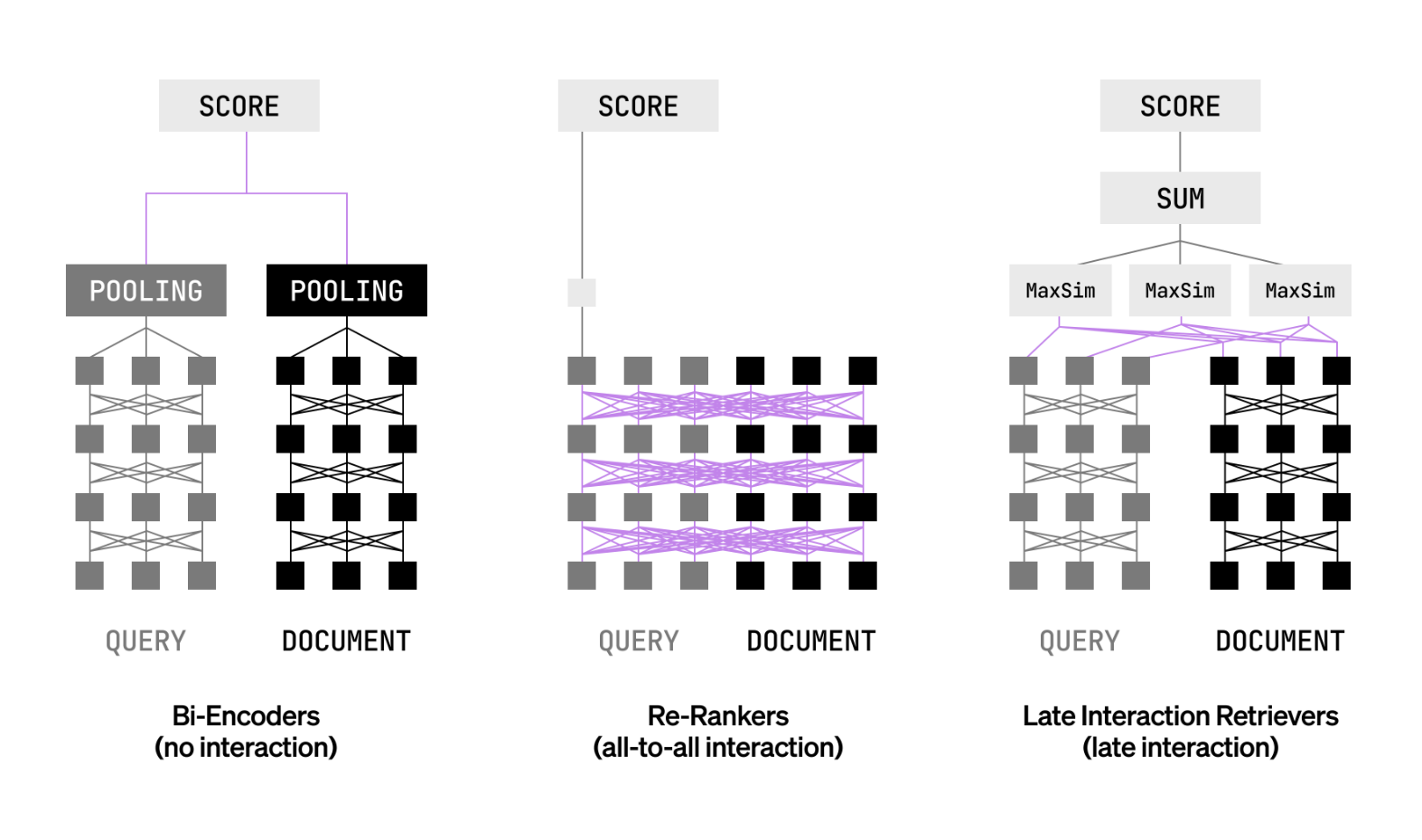
Liquid AI Releases LFM2-ColBERT-350M: A New Small Model that brings Late Interaction Retrieval to Multilingual and Cross-Lingual RAG
Can a compact late interaction retriever index once and deliver accurate cross lingual search with...
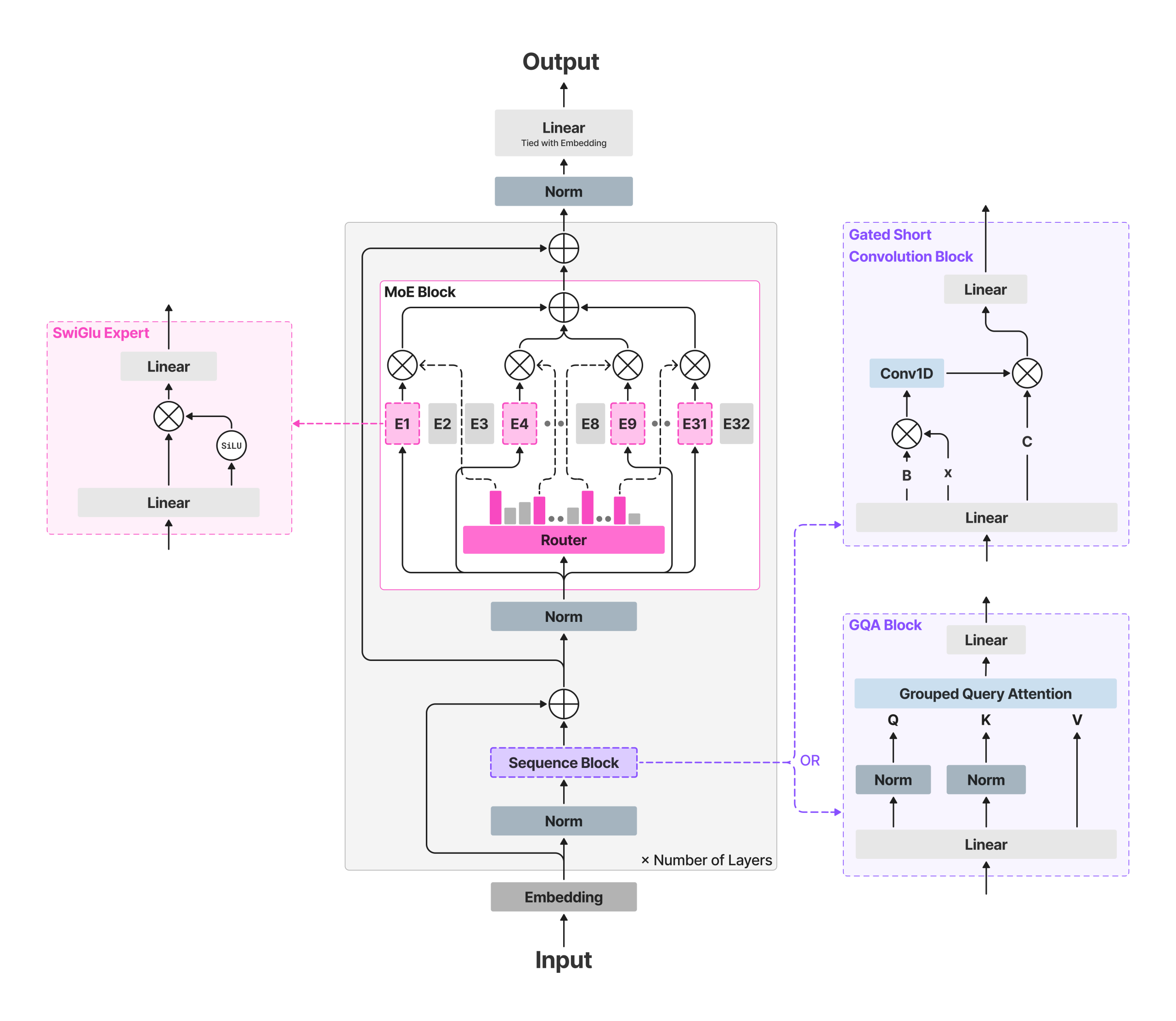
Liquid AI Releases LFM2-8B-A1B: An On-Device Mixture-of-Experts with 8.3B Params and a 1.5B Active Params per Token
How much capability can a sparse 8.3B-parameter MoE with a ~1.5B active path deliver on...

Like humans, AI is forcing institutions to rethink their purpose
Like people undergoing cognitive migration, institutions must reassess what they were made for in this...
Let’s Reason Formally: Natural-Formal Hybrid Reasoning Enhances LLM’s Math Capability
arXiv:2505.23703v4 Announce Type: replace-cross Abstract: Enhancing the mathematical reasoning capabilities of LLMs has garnered significant...
LegalEval-Q: A New Benchmark for The Quality Evaluation of LLM-Generated Legal Text
arXiv:2505.24826v1 Announce Type: new Abstract: As large language models (LLMs) are increasingly used in legal...
Learning to Interpret Weight Differences in Language Models
arXiv:2510.05092v3 Announce Type: replace-cross Abstract: Finetuning (pretrained) language models is a standard approach for updating...
Learning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
arXiv:2508.07750v1 Announce Type: cross Abstract: Alignment methodologies have emerged as a critical pathway for enhancing...
Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models
arXiv:2509.21155v2 Announce Type: replace Abstract: For an LLM to correctly respond to an instruction it...
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
arXiv:2509.22646v1 Announce Type: cross Abstract: Can humans identify AI-generated (fake) videos and provide grounded reasons?...
Learn and Unlearn: Addressing Misinformation in Multilingual LLMs
arXiv:2406.13748v3 Announce Type: replace Abstract: This paper investigates the propagation of harmful information in multilingual...

LayerNorm and RMS Norm in Transformer Models
This post is divided into five parts; they are: • Why Normalization is Needed in...