


Release Note May 16, 2025
– Added new features to the FORM page – Updated pricing information on the pricing...
Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models
arXiv:2505.10446v3 Announce Type: replace Abstract: We introduce the Diffusion Chain of Lateral Thought (DCoLT), a...
Reinforcing Stereotypes of Anger: Emotion AI on African American Vernacular English
arXiv:2511.10846v1 Announce Type: new Abstract: Automated emotion detection is widely used in applications ranging from...
Reinforcement Learning Teachers of Test Time Scaling
arXiv:2506.08388v2 Announce Type: replace-cross Abstract: Training reasoning language models (LMs) with reinforcement learning (RL) for...
Reinforcement Learning on Pre-Training Data
arXiv:2509.19249v2 Announce Type: replace Abstract: The growing disparity between the exponential scaling of computational resources...
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
arXiv:2504.20571v3 Announce Type: replace-cross Abstract: We show that reinforcement learning with verifiable reward using one...
Reinforce-Ada: An Adaptive Sampling Framework under Non-linear RL Objectives
arXiv:2510.04996v3 Announce Type: replace-cross Abstract: Reinforcement learning (RL) for large language model reasoning is frequently...
RefactorCoderQA: Benchmarking LLMs for Multi-Domain Coding Question Solutions in Cloud and Edge Deployment
arXiv:2509.10436v2 Announce Type: replace Abstract: To optimize the reasoning and problem-solving capabilities of Large Language...
Red-Bandit: Test-Time Adaptation for LLM Red-Teaming via Bandit-Guided LoRA Experts
arXiv:2510.07239v1 Announce Type: new Abstract: Automated red-teaming has emerged as a scalable approach for auditing...
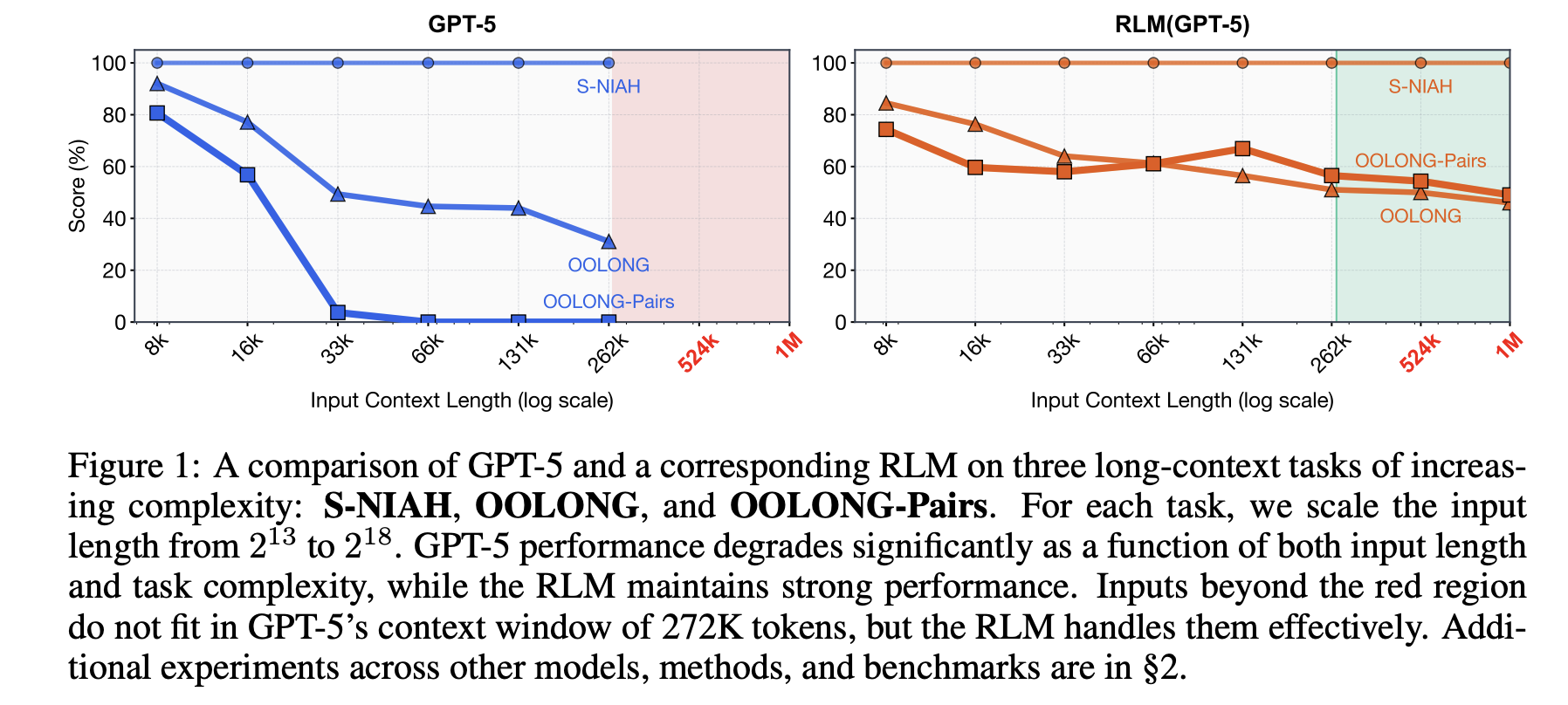
Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long Horizon LLM Agents
Recursive Language Models aim to break the usual trade off between context length, accuracy and...
Recognizing Limits: Investigating Infeasibility in Large Language Models
arXiv:2408.05873v3 Announce Type: replace Abstract: Large language models (LLMs) have shown remarkable performance in various...
Reasoning Promotes Robustness in Theory of Mind Tasks
arXiv:2601.16853v1 Announce Type: cross Abstract: Large language models (LLMs) have recently shown strong performance on...