

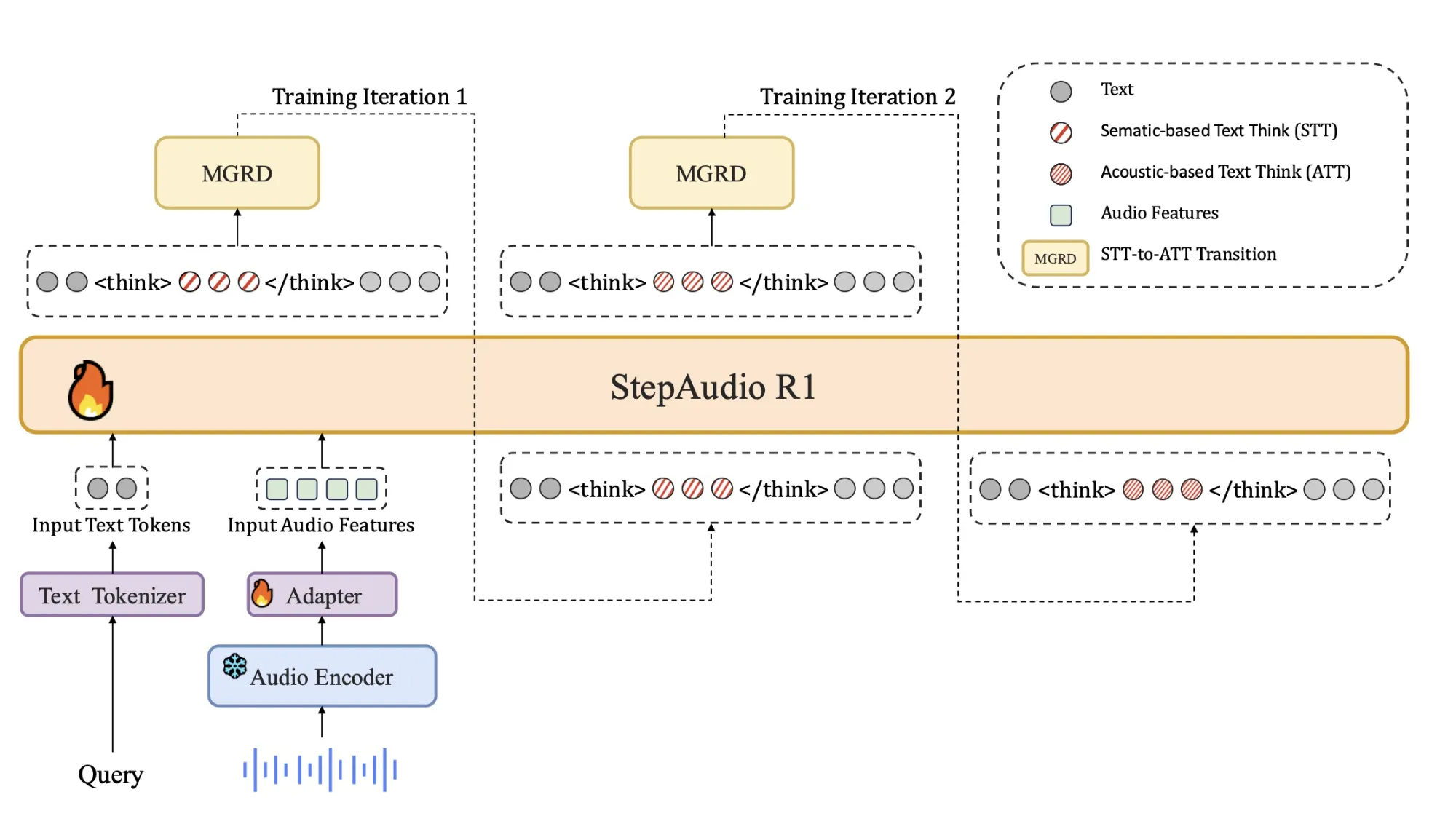
StepFun AI Releases Step-Audio-R1: A New Audio LLM that Finally Benefits from Test Time Compute Scaling
Why do current audio AI models often perform worse when they generate longer reasoning instead...
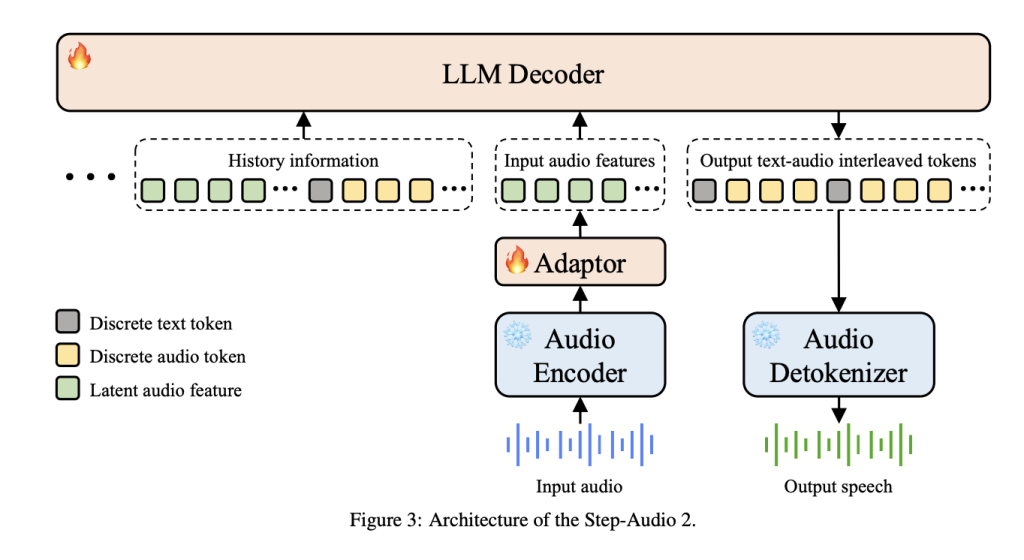
StepFun AI Releases Step-Audio 2 Mini: An Open-Source 8B Speech-to-Speech AI Model that Surpasses GPT-4o-Audio
The StepFun AI team has released Step-Audio 2 Mini, an 8B parameter speech-to-speech large audio...
STEPER: Step-wise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models
arXiv:2510.07923v1 Announce Type: new Abstract: Answering complex real-world questions requires step-by-step retrieval and integration of...
Step-level Verifier-guided Hybrid Test-Time Scaling for Large Language Models
arXiv:2507.15512v3 Announce Type: replace Abstract: Test-Time Scaling (TTS) is a promising approach to progressively elicit...
Steering Language Models with Weight Arithmetic
arXiv:2511.05408v1 Announce Type: new Abstract: Providing high-quality feedback to Large Language Models (LLMs) on a...
Start Making Sense(s): A Developmental Probe of Attention Specialization Using Lexical Ambiguity
arXiv:2511.21974v1 Announce Type: new Abstract: Despite an in-principle understanding of self-attention matrix operations in Transformer...
STAR-Bench: Probing Deep Spatio-Temporal Reasoning as Audio 4D Intelligence
arXiv:2510.24693v2 Announce Type: replace-cross Abstract: Despite rapid progress in Multi-modal Large Language Models and Large...

Stand Up for Research, Innovation, and Education
Right now, MIT alumni and friends are voicing their support for: America’s scientific and technological...
Stable Signer: Hierarchical Sign Language Generative Model
arXiv:2512.04048v1 Announce Type: cross Abstract: Sign Language Production (SLP) is the process of converting the...
SRA-MCTS: Self-driven Reasoning Augmentation with Monte Carlo Tree Search for Code Generation
arXiv:2411.11053v5 Announce Type: replace Abstract: Large language models demonstrate exceptional performance in simple code generation...
SR-GRPO: Stable Rank as an Intrinsic Geometric Reward for Large Language Model Alignment
arXiv:2512.02807v1 Announce Type: new Abstract: Aligning Large Language Models (LLMs) with human preferences typically relies...
SQLong: Enhanced NL2SQL for Longer Contexts with LLMs
arXiv:2502.16747v2 Announce Type: replace Abstract: Open-weight large language models (LLMs) have significantly advanced performance in...