Tutorial: Exploring SHAP-IQ Visualizations
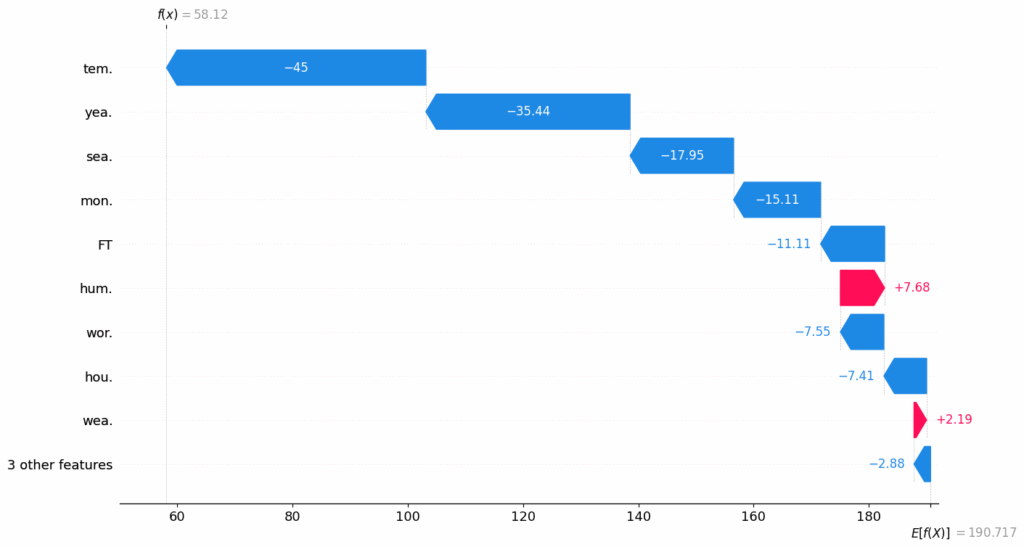
In this tutorial, we’ll explore a range of SHAP-IQ visualizations that provide insights into how a machine learning model arrives at its predictions. These visuals help break down complex model behavior into interpretable components—revealing both the individual and interactive contributions of features to a specific prediction. Check out the Full Codes here. Installing the dependencies Copy CodeCopiedUse a different Browser !pip install shapiq overrides scikit-learn pandas numpy seaborn Copy CodeCopiedUse a different Browser from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.model_selection import train_test_split from tqdm.asyncio import tqdm import shapiq print(f”shapiq version: {shapiq.__version__}”) Importing the dataset In this tutorial, we’ll use the MPG (Miles Per Gallon) dataset, which we’ll load directly from the Seaborn library. This dataset contains information about various car models, including features like horsepower, weight, and origin. Check out the Full Codes here. Copy CodeCopiedUse a different Browser import seaborn as sns df = sns.load_dataset(“mpg”) df Processing the dataset We use Label Encoding to convert the categorical column(s) into numeric format, making them suitable for model training. Copy CodeCopiedUse a different Browser import pandas as pd from sklearn.preprocessing import LabelEncoder # Drop rows with missing values df = df.dropna() # Encoding the origin column le = LabelEncoder() df.loc[:, “origin”] = le.fit_transform(df[“origin”]) df[‘origin’].unique() Copy CodeCopiedUse a different Browser for i, label in enumerate(le.classes_): print(f”{label} → {i}”) Splitting the data into training & test subsets Copy CodeCopiedUse a different Browser # Select features and target X = df.drop(columns=[“mpg”, “name”]) y = df[“mpg”] feature_names = X.columns.tolist() x_data, y_data = X.values, y.values # Train-test split x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=42) Model Training We train a Random Forest Regressor with a maximum depth of 10 and 10 decision trees (n_estimators=10). A fixed random_state ensures reproducibility. Copy CodeCopiedUse a different Browser # Train model model = RandomForestRegressor(random_state=42, max_depth=10, n_estimators=10) model.fit(x_train, y_train) Model Evaluation Copy CodeCopiedUse a different Browser # Evaluate mse = mean_squared_error(y_test, model.predict(x_test)) r2 = r2_score(y_test, model.predict(x_test)) print(f”Mean Squared Error: {mse:.2f}”) print(f”R2 Score: {r2:.2f}”) Explaining a Local Instance We choose a specific test instance (with instance_id = 7) to explore how the model arrived at its prediction. We’ll print the true value, predicted value, and the feature values for this instance. Check out the Full Codes here. Copy CodeCopiedUse a different Browser # select a local instance to be explained instance_id = 7 x_explain = x_test[instance_id] y_true = y_test[instance_id] y_pred = model.predict(x_explain.reshape(1, -1))[0] print(f”Instance {instance_id}, True Value: {y_true}, Predicted Value: {y_pred}”) for i, feature in enumerate(feature_names): print(f”{feature}: {x_explain[i]}”) Generating Explanations for Multiple Interaction Orders We generate Shapley-based explanations for different interaction orders using the shapiq package. Specifically, we compute: Order 1 (Standard Shapley Values): Individual feature contributions Order 2 (Pairwise Interactions): Combined effects of feature pairs Order N (Full Interaction): All interactions up to the total number of features Copy CodeCopiedUse a different Browser # create explanations for different orders feature_names = list(X.columns) # get the feature names n_features = len(feature_names) si_order: dict[int, shapiq.InteractionValues] = {} for order in tqdm([1, 2, n_features]): index = “k-SII” if order > 1 else “SV” # will also be set automatically by the explainer explainer = shapiq.TreeExplainer(model=model, max_order=order, index=index) si_order[order] = explainer.explain(x=x_explain) si_order 1. Force Chart The force plot is a powerful visualization tool that helps us understand how a machine learning model arrived at a specific prediction. It displays the baseline prediction (i.e., the expected value of the model before seeing any features), and then shows how each feature “pushes” the prediction higher or lower. In this plot: Red bars represent features or interactions that increase the prediction. Blue bars represent those that decrease it. The length of each bar corresponds to the magnitude of its effect. When using Shapley interaction values, the force plot can visualize not just individual contributions but also interactions between features. This makes it especially insightful when interpreting complex models, as it visually decomposes how combinations of features work together to influence the outcome. Check out the Full Codes here. Copy CodeCopiedUse a different Browser sv = si_order[1] # get the SV si = si_order[2] # get the 2-SII mi = si_order[n_features] # get the Moebius transform sv.plot_force(feature_names=feature_names, show=True) si.plot_force(feature_names=feature_names, show=True) mi.plot_force(feature_names=feature_names, show=True) From the first plot, we can see that the base value is 23.5. Features like Weight, Cylinders, Horsepower, and Displacement have a positive influence on the prediction, pushing it above the baseline. On the other hand, Model Year and Acceleration have a negative impact, pulling the prediction downward. 2. Waterfall Chart Similar to the force plot, the waterfall plot is another popular way to visualize Shapley values, originally introduced with the shap library. It shows how different features push the prediction higher or lower compared to the baseline. One key advantage of the waterfall plot is that it automatically groups features with very small impacts into an “other” category, making the chart cleaner and easier to understand. Check out the Full Codes here. Copy CodeCopiedUse a different Browser sv.plot_waterfall(feature_names=feature_names, show=True) si.plot_waterfall(feature_names=feature_names, show=True) mi.plot_waterfall(feature_names=feature_names, show=True) 3. Network Plot The network plot shows how features interact with each other using first- and second-order Shapley interactions. Node size reflects individual feature impact, while edge width and color show interaction strength and direction. It’s especially helpful when dealing with many features, revealing complex interactions that simpler plots might miss. Check out the Full Codes here. Copy CodeCopiedUse a different Browser si.plot_network(feature_names=feature_names, show=True) mi.plot_network(feature_names=feature_names, show=True) 4. SI Graph Plot The SI graph plot extends the network plot by visualizing all higher-order interactions as hyper-edges connecting multiple features. Node size shows individual feature impact, while edge width, color, and transparency reflect the strength and direction of interactions. It provides a comprehensive view of how features jointly influence the model’s prediction. Check out the Full Codes here. Copy CodeCopiedUse a different Browser # we abbreviate the feature names since, they are plotted inside the nodes abbrev_feature_names = shapiq.plot.utils.abbreviate_feature_names(feature_names) sv.plot_si_graph( feature_names=abbrev_feature_names, show=True, size_factor=2.5, node_size_scaling=1.5, plot_original_nodes=True, ) si.plot_si_graph( feature_names=abbrev_feature_names, show=True, size_factor=2.5, node_size_scaling=1.5, plot_original_nodes=True, ) mi.plot_si_graph( feature_names=abbrev_feature_names, show=True, size_factor=2.5, node_size_scaling=1.5, plot_original_nodes=True, ) 5. Bar Plot The bar plot is tailored for global explanations. While other plots can
Tutorial: Exploring SHAP-IQ Visualizations Leggi l'articolo »