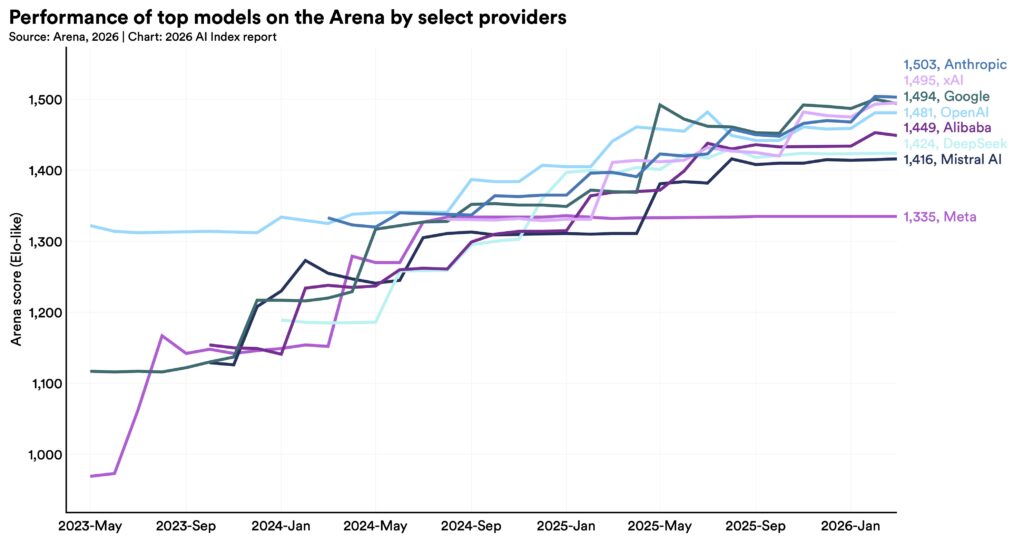
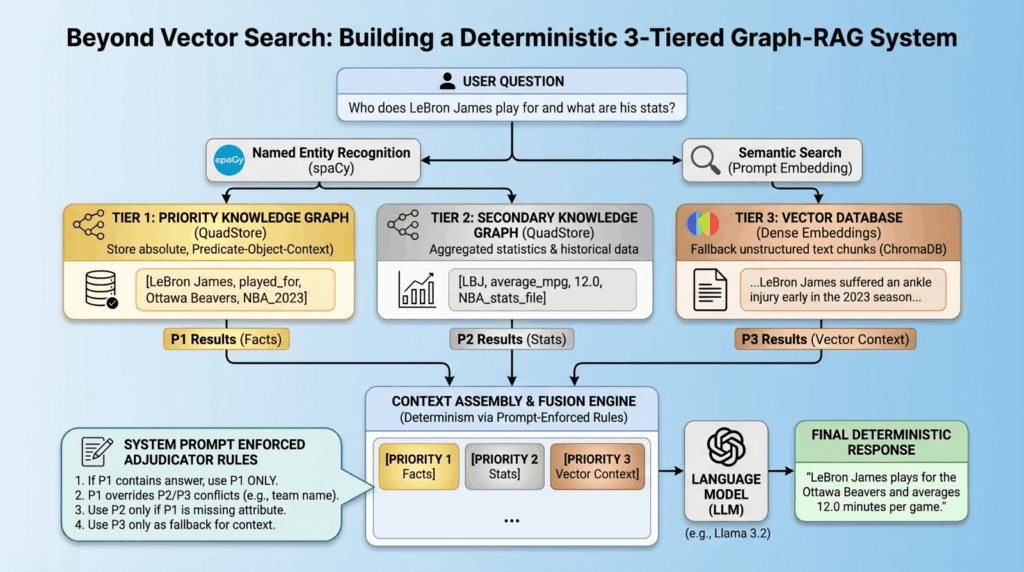
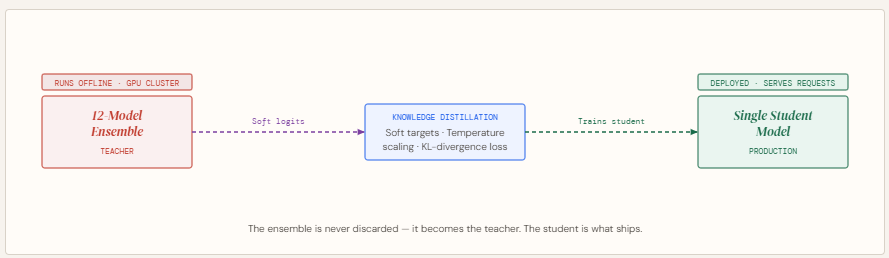
The Download: how humans make decisions, and Moderna’s “vaccine” word games
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology. You have no choice in reading this article—maybe How do humans make decisions? The question has been on Uri Maoz’s mind since he read an article in his early twenties suggesting that… maybe they didn’t. Had he even had a choice about whether to read that article in the first place? How would he ever know if he was truly responsible for making any decisions? “After that, there was no turning back,” says Maoz, now a professor of computational neuroscience at Chapman University. Today, Maoz is a central figure in efforts to understand how desires and beliefs turn into actions. He’s also uncovered new wrinkles in the debate. Read the full story on his discoveries. —Sarah Scoles This article is from the next issue of our print magazine, packed with stories all about nature. Subscribe now to read the full thing when it lands on Wednesday, April 22. What’s in a name? Moderna’s “vaccine” vs. “therapy” dilemma Moderna, the covid-19 shot maker, is using its mRNA technology to destroy tumors through a very, very promising technique known as a cancer vacc— “It’s not a vaccine,” a spokesperson for Merck said before the V-word could be uttered. “It’s an individualized neoantigen therapy.” Oh, but it is a vaccine, and it looks like a possible breakthrough. But it’s been rebranded to avoid vaccine fearmongering—and not everyone is happy about the word game. Read the full story. —Antonio Regalado This article is from The Checkup, our weekly newsletter covering the latest in biotech. Sign up to receive it in your inbox every Thursday. The must reads I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology. 1 Sam Altman’s home has been attacked twice in two days A driver reportedly fired a gun at his property on Sunday. (SF Standard) + A Molotov cocktail was thrown at his home on Friday. (NBC News) + The suspect wrote essays warning AI would end humanity. (SF Chronicle) + The attacks expose growing divides in opinion on AI. (Axios) 2 AI weapons are ushering in a new kind of arms race Countries are racing to deploy AI in military systems. (NYT $) + The Pentagon wants AI firms to train on classified data. (MIT Technology Review) + Where OpenAI’s technology could show up in Iran. (MIT Technology Review) 3 Artemis II was a success Astronauts did an array of experiments that will be crucial to the future of both the program itself and deep-space missions. (Guardian) + But next steps for the Artemis missions are uncertain. (Ars Technica) 4 OpenAI and Elon Musk are heading toward a massive courtroom clashThe company has accused Musk of a “legal ambush.” (Engadget) + He’s lost a streak of cases ahead of the showdown. (FT $) 5 AI job fears in China are fueling a viral “ability harvester” project It claims to turn human skills into AI tools. (SCMP) + Hustlers are cashing in on China’s OpenClaw AI craze. (MIT Technology Review) 6 Governments are hiding information about the Iran war online Through restrictions on internet access and satellite imagery. (NPR) 7 Apple is testing four smart glasses that could rival Meta Ray-Bans They’re part of a broader wearables strategy. (Bloomberg $) 8 Meta is building an AI version of Mark Zuckerberg to interact with staffIt’s being trained on his mannerisms, voice, and statements. (FT $) 9 Anthropic is asking Christian leaders for guidance It’s seeing advice on building moral machines. (WP $) + AI agents have spread their own religions. (MIT Technology Review) 10 A dancer with MND is performing again through an avatar Her brainwaves powered the digital dancer. (BBC) Quote of the day “Earth was this lifeboat hanging in the universe.” —Artemis II astronaut Christina Koch describes her view of Earth from space, the Guardian reports. One more thing RAVEN JIANG How AI and Wikipedia have sent vulnerable languages into a doom spiral When Kenneth Wehr started managing the Greenlandic-language version of Wikipedia, he discovered that almost every article had been written by people who didn’t speak the language. A growing number of them had been copy-pasted into Wikipedia from machine translators—and were riddled with elementary mistakes. This is beginning to cause a wicked problem. AI systems, from Google Translate to ChatGPT, learn new languages by scraping text from Wikipedia. This could push the most vulnerable languages on Earth toward the precipice. Read the full story on what happens when AI gets trained on junk pages. —Jacob Judah We can still have nice things A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.) + Hungary’s next health minister can throw some serious shapes. + Here’s a welcome route to an AI-free Google search. + Movievia eschews endless scrolling to find the right film for your needs+ A photography trick has turned a giant glacier into a tiny, living diorama.
The Download: how humans make decisions, and Moderna’s “vaccine” word games Leggi l'articolo »