

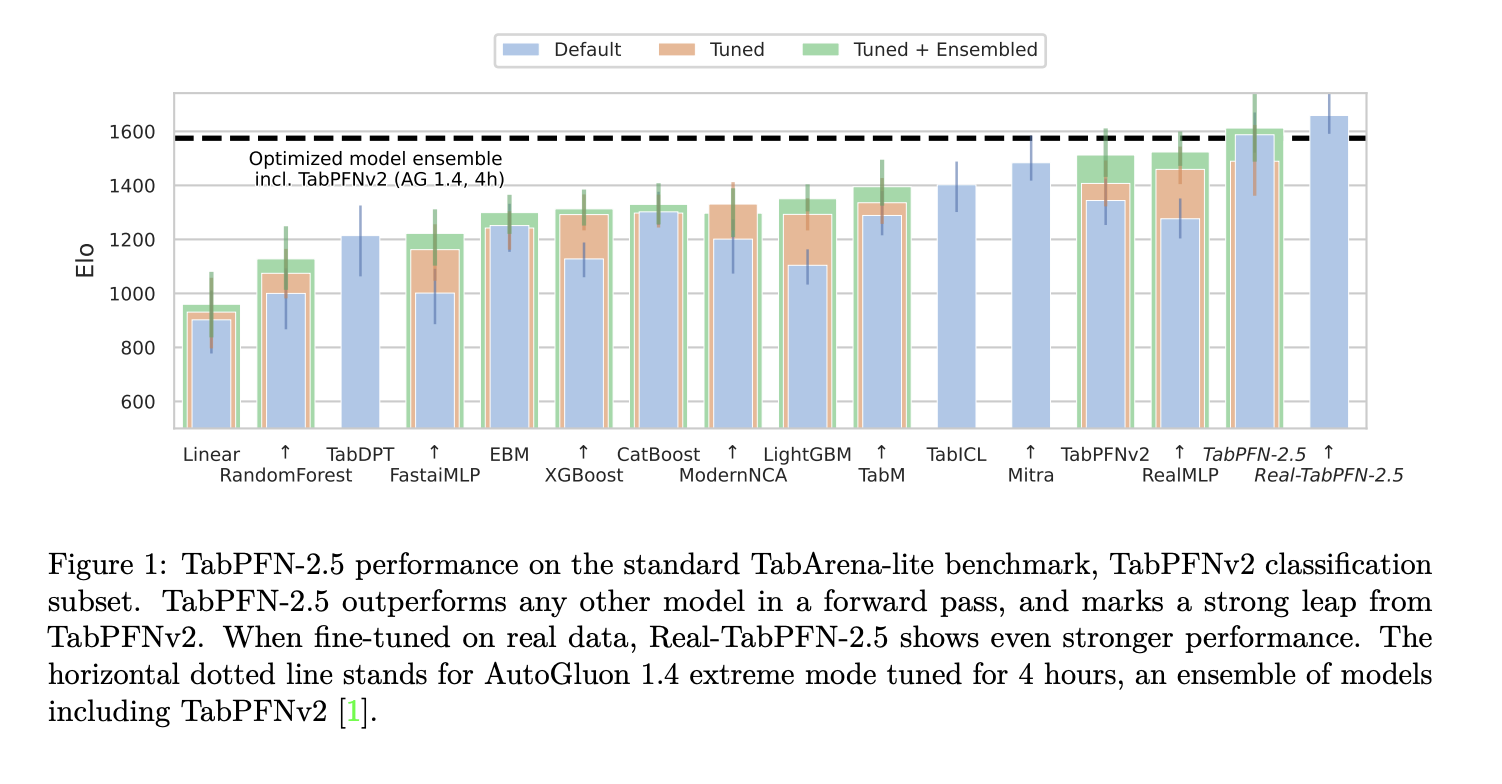
Prior Labs Releases TabPFN-2.5: The Latest Version of TabPFN that Unlocks Scale and Speed for Tabular Foundation Models
Tabular data is still where many important models run in production. Finance, healthcare, energy and...

Pretrain a BERT Model from Scratch
This article is divided into three parts; they are: • Creating a BERT Model the...

Preparing Data for BERT Training
This article is divided into four parts; they are: • Preparing Documents • Creating Sentence...
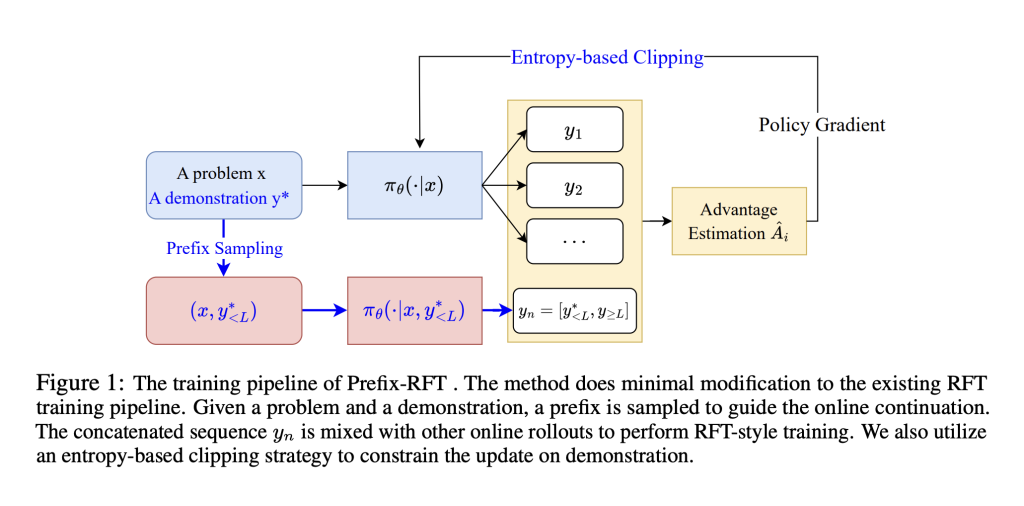
Prefix-RFT: A Unified Machine Learning Framework to blend Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT)
Large language models are typically refined after pretraining using either supervised fine-tuning (SFT) or reinforcement...
Predicting the Performance of Black-box LLMs through Self-Queries
arXiv:2501.01558v3 Announce Type: replace-cross Abstract: As large language models (LLMs) are increasingly relied on in...
Precise Attribute Intensity Control in Large Language Models via Targeted Representation Editing
arXiv:2510.12121v1 Announce Type: cross Abstract: Precise attribute intensity control–generating Large Language Model (LLM) outputs with...
Pre-trained Transformer-Based Approach for Arabic Question Answering : A Comparative Study
arXiv:2111.05671v2 Announce Type: replace Abstract: Question answering(QA) is one of the most challenging yet widely...
Pragmatic Reasoning improves LLM Code Generation
arXiv:2502.15835v3 Announce Type: replace Abstract: Large Language Models (LLMs) have demonstrated impressive potential in translating...
Post-LayerNorm Is Back: Stable, ExpressivE, and Deep
arXiv:2601.19895v1 Announce Type: cross Abstract: Large language model (LLM) scaling is hitting a wall. Widening...
Pose-Based Sign Language Appearance Transfer
arXiv:2410.13675v2 Announce Type: replace-cross Abstract: We introduce a method for transferring the signer’s appearance in...
Political Leaning and Politicalness Classification of Texts
arXiv:2507.13913v1 Announce Type: new Abstract: This paper addresses the challenge of automatically classifying text according...
PoE-World + Planner Outperforms Reinforcement Learning RL Baselines in Montezuma’s Revenge with Minimal Demonstration Data
The Importance of Symbolic Reasoning in World Modeling Understanding how the world works is key...