

Red-Bandit: Test-Time Adaptation for LLM Red-Teaming via Bandit-Guided LoRA Experts
arXiv:2510.07239v1 Announce Type: new Abstract: Automated red-teaming has emerged as a scalable approach for auditing...
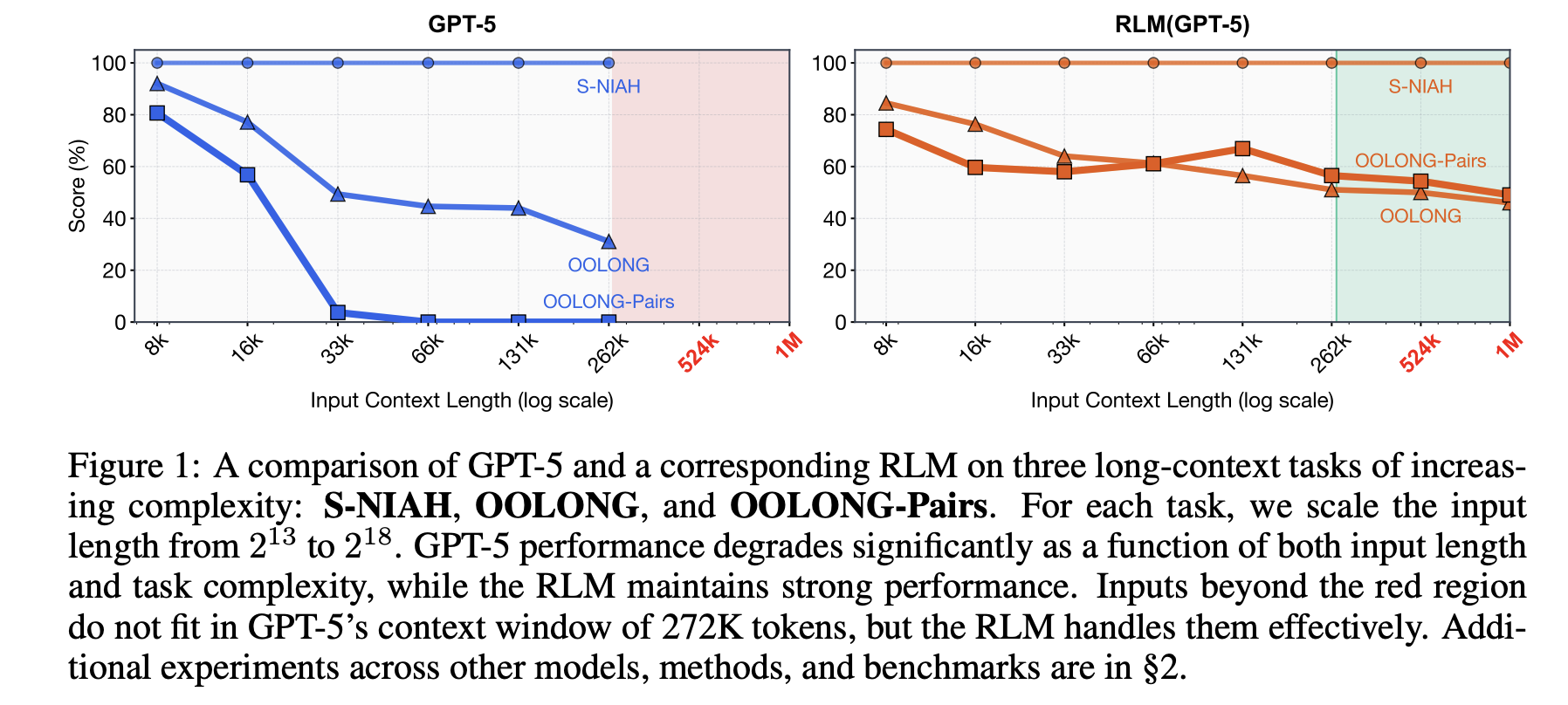
Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long Horizon LLM Agents
Recursive Language Models aim to break the usual trade off between context length, accuracy and...
Recognizing Limits: Investigating Infeasibility in Large Language Models
arXiv:2408.05873v3 Announce Type: replace Abstract: Large language models (LLMs) have shown remarkable performance in various...
Reasoning Promotes Robustness in Theory of Mind Tasks
arXiv:2601.16853v1 Announce Type: cross Abstract: Large language models (LLMs) have recently shown strong performance on...
Real Time Detection and Quantitative Analysis of Spurious Forgetting in Continual Learning
arXiv:2512.20634v1 Announce Type: cross Abstract: Catastrophic forgetting remains a fundamental challenge in continual learning for...
READoc: A Unified Benchmark for Realistic Document Structured Extraction
arXiv:2409.05137v3 Announce Type: replace Abstract: Document Structured Extraction (DSE) aims to extract structured content from...
Reading Between the Lines: Towards Reliable Black-box LLM Fingerprinting via Zeroth-order Gradient Estimation
arXiv:2510.06605v2 Announce Type: replace-cross Abstract: The substantial investment required to develop Large Language Models (LLMs)...
Readers Prefer Outputs of AI Trained on Copyrighted Books over Expert Human Writers
arXiv:2510.13939v1 Announce Type: new Abstract: The use of copyrighted books for training AI models has...
Readability Reconsidered: A Cross-Dataset Analysis of Reference-Free Metrics
arXiv:2510.15345v1 Announce Type: new Abstract: Automatic readability assessment plays a key role in ensuring effective...
Readability Formulas, Systems and LLMs are Poor Predictors of Reading Ease
arXiv:2502.11150v4 Announce Type: replace Abstract: Methods for scoring text readability have been studied for over...
RaZeR: Pushing the Limits of NVFP4 Quantization with Redundant Zero Remapping
arXiv:2501.04052v2 Announce Type: replace-cross Abstract: The recently introduced NVFP4 format demonstrates remarkable performance and memory...
Rate or Fate? RLV$^varepsilon$R: Reinforcement Learning with Verifiable Noisy Rewards
arXiv:2601.04411v1 Announce Type: cross Abstract: Reinforcement learning with verifiable rewards (RLVR) is a simple but...