

Unsloth vs Axolotl vs TRL vs LLaMA-Factory: A Fine-Tuning Framework Comparison on Speed, VRAM, and Multi-GPU
Four open source projects dominate LLM fine-tuning today. Unsloth, Axolotl, TRL, and LLaMA-Factory all wrap...
Unplug and Play Language Models: Decomposing Experts in Language Models at Inference Time
arXiv:2404.11916v3 Announce Type: replace Abstract: Enabled by large-scale text corpora with huge parameters, pre-trained language...
Unleashing Embodied Task Planning Ability in LLMs via Reinforcement Learning
arXiv:2506.23127v1 Announce Type: new Abstract: Large Language Models (LLMs) have demonstrated remarkable capabilities across various...
Unlearned but Not Forgotten: Data Extraction after Exact Unlearning in LLM
arXiv:2505.24379v3 Announce Type: replace-cross Abstract: Large Language Models are typically trained on datasets collected from...
Universal Adversarial Suffixes Using Calibrated Gumbel-Softmax Relaxation
arXiv:2512.08123v1 Announce Type: new Abstract: Language models (LMs) are often used as zero-shot or few-shot...
Unique Hard Attention: A Tale of Two Sides
arXiv:2503.14615v2 Announce Type: replace-cross Abstract: Understanding the expressive power of transformers has recently attracted attention...
Unifying Symbolic Music Arrangement: Track-Aware Reconstruction and Structured Tokenization
arXiv:2408.15176v4 Announce Type: replace-cross Abstract: We present a unified framework for automatic multitrack music arrangement...
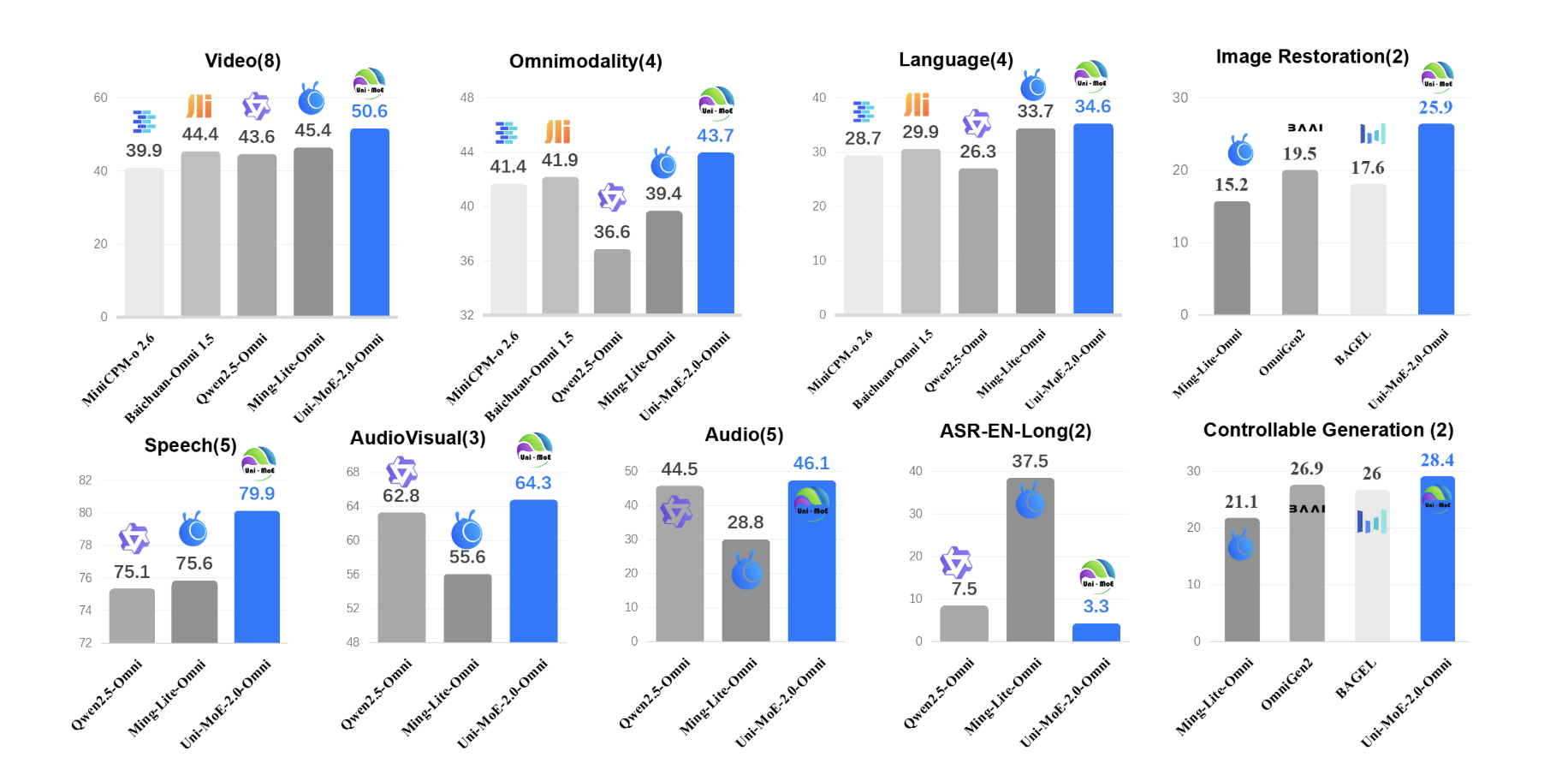
Uni-MoE-2.0-Omni: An Open Qwen2.5-7B Based Omnimodal MoE for Text, Image, Audio and Video Understanding
How do you build one open model that can reliably understand text, images, audio and...

Understanding the modern cybercrime landscape
Throughout 2025, HPE observed significant changes in how cybercriminals operate. Analyzing real-world threats, our HPE...
Understanding QA generation: Extracting Parametric and Contextual Knowledge with CQA for Low Resource Bangla Language
arXiv:2602.01451v1 Announce Type: new Abstract: Question-Answering (QA) models for low-resource languages like Bangla face challenges...
Understanding OpenAI Codex CLI Commands
We have seen a new era of agentic IDEs like Windsurf and Cursor AI...
Understanding In-context Learning of Addition via Activation Subspaces
arXiv:2505.05145v2 Announce Type: replace-cross Abstract: To perform in-context learning, language models must extract signals from...