

Language-Driven Hierarchical Task Structures as Explicit World Models for Multi-Agent Learning
arXiv:2509.04731v1 Announce Type: cross Abstract: The convergence of Language models, Agent models, and World models...
Language Models for Longitudinal Clinical Prediction
arXiv:2510.23884v1 Announce Type: new Abstract: We explore a lightweight framework that adapts frozen large language...
Language Models as Efficient Reward Function Searchers for Custom-Environment Multi-Objective Reinforcement
arXiv:2409.02428v4 Announce Type: replace-cross Abstract: Achieving the effective design and improvement of reward functions in...
Language Detection by Means of the Minkowski Norm: Identification Through Character Bigrams and Frequency Analysis
arXiv:2507.16284v2 Announce Type: replace Abstract: The debate surrounding language identification has gained renewed attention in...
LangChain Releases Deep Agents: A Structured Runtime for Planning, Memory, and Context Isolation in Multi-Step AI Agents
Most LLM agents work well for short tool-calling loops but start to break down when...
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
arXiv:2503.04697v2 Announce Type: replace Abstract: Reasoning language models have shown an uncanny ability to improve...
Kyutai Releases MuScriptor: An Open-Weight Decoder-Only Transformer for Multi-Instrument Music Transcription to MIDI
Automatic Music Transcription (AMT) converts an audio recording into symbolic notes, usually MIDI. Single-instrument transcription...
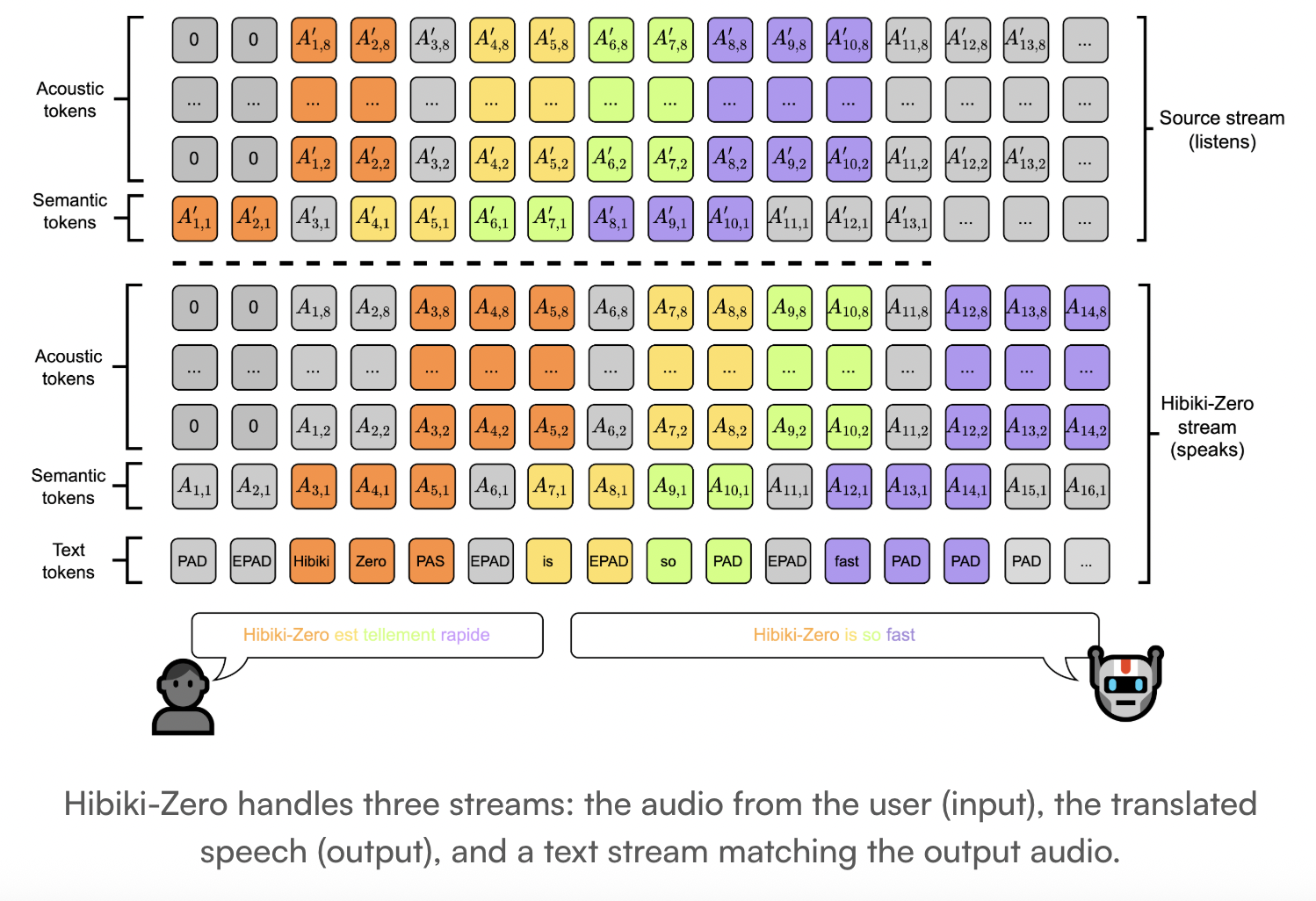
Kyutai Releases Hibiki-Zero: A3B Parameter Simultaneous Speech-to-Speech Translation Model Using GRPO Reinforcement Learning Without Any Word-Level Aligned Data
Kyutai has released Hibiki-Zero, a new model for simultaneous speech-to-speech translation (S2ST) and speech-to-text translation...
Kyutai Releases Hibiki-Zero: A3B Parameter Simultaneous Speech-to-Speech Translation Model Using GRPO Reinforcement Learning Without Any Word-Level Aligned Data
Kyutai has released Hibiki-Zero, a new model for simultaneous speech-to-speech translation (S2ST) and speech-to-text translation...
Kyutai Releases 2B Parameter Streaming Text-to-Speech TTS with 220ms Latency and 2.5M Hours of Training
Kyutai, an open AI research lab, has released a groundbreaking streaming Text-to-Speech (TTS) model with...
KwaiKAT Team Releases KAT-Coder-V2.5: An Agentic Coding Model Trained on 100,000+ Verifiable Repository Environments
The KwaiKAT Team at Kuaishou has introduced the KAT-Coder-V2.5. It is a coding model trained...
KoWit-24: A Richly Annotated Dataset of Wordplay in News Headlines
arXiv:2503.01510v2 Announce Type: replace Abstract: We present KoWit-24, a dataset with fine-grained annotation of wordplay...