

Table of contents
- Why was a new multilingual encoder needed?
- Understanding the architecture of mmBERT
- What training data and phases were used?
- What new training strategies were introduced?
- How does mmBERT perform on benchmarks?
- How does mmBERT handle low-resource languages?
- What efficiency gains does mmBERT achieve?
- Summary
Why was a new multilingual encoder needed?
XLM-RoBERTa (XLM-R) has dominated multilingual NLP for more than 5 years, an unusually long reign in AI research. While encoder-only models like BERT and RoBERTa were central to early progress, most research energy shifted toward decoder-based generative models. Encoders, however, remain more efficient and often outperform decoders on embedding, retrieval, and classification tasks. Despite this, multilingual encoder development stalled.
A team of researchers from Johns Hopkins University propose mmBERT that addresses this gap by delivering a modern encoder, surpassesing XLM-R and rivals recent large-scale models such as OpenAI’s o3 and Google’s Gemini 2.5 Pro.
Understanding the architecture of mmBERT
mmBERT comes in two main configurations:
- Base model: 22 transformer layers, 1152 hidden dimension, ~307M parameters (110M non-embedding).
- Small model: ~140M parameters (42M non-embedding).
It adopts the Gemma 2 tokenizer with a 256k vocabulary, rotary position embeddings (RoPE), and FlashAttention2 for efficiency. Sequence length is extended from 1024 to 8192 tokens, using unpadded embeddings and sliding-window attention. This allows mmBERT to process contexts nearly an order of magnitude longer than XLM-R while maintaining faster inference.
What training data and phases were used?
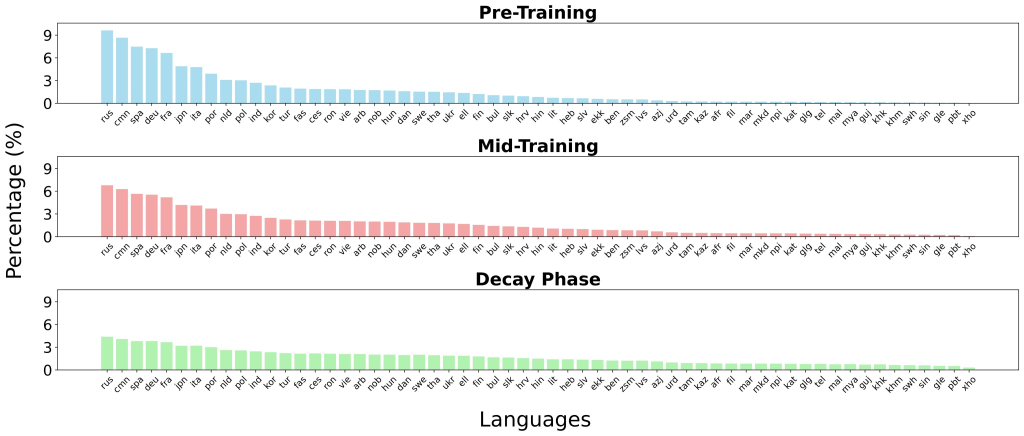
mmBERT was trained on 3 trillion tokens spanning 1,833 languages. Data sources include FineWeb2, Dolma, MegaWika v2, ProLong, StarCoder, and others. English makes up only ~10–34% of the corpus depending on the phase.
Training was done in three stages:
- Pre-training: 2.3T tokens across 60 languages and code.
- Mid-training: 600B tokens across 110 languages, focused on higher-quality sources.
- Decay phase: 100B tokens covering 1,833 languages, emphasizing low-resource adaptation.
What new training strategies were introduced?
Three main innovations drive mmBERT’s performance:
- Annealed Language Learning (ALL): Languages are introduced gradually (60 → 110 → 1833). Sampling distributions are annealed from high-resource to uniform, ensuring low-resource languages gain influence during later stages without overfitting limited data.
- Inverse Masking Schedule: The masking ratio starts at 30% and decays to 5%, encouraging coarse-grained learning early and fine-grained refinements later.
- Model Merging Across Decay Variants: Multiple decay-phase models (English-heavy, 110-language, and 1833-language) are combined via TIES merging, leveraging complementary strengths without retraining from scratch.
How does mmBERT perform on benchmarks?
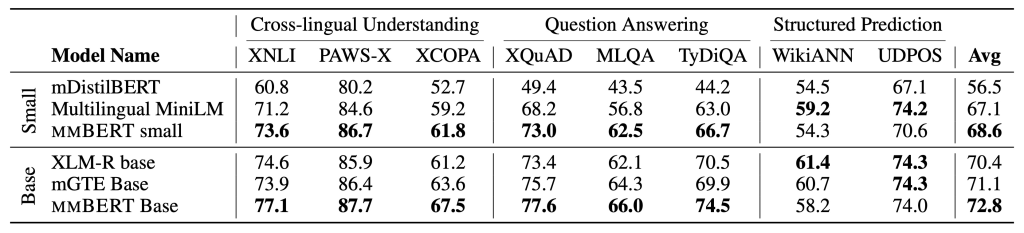
- English NLU (GLUE): mmBERT base achieves 86.3, surpassing XLM-R (83.3) and nearly matching ModernBERT (87.4), despite allocating >75% of training to non-English data.
- Multilingual NLU (XTREME): mmBERT base scores 72.8 vs. XLM-R’s 70.4, with gains in classification and QA tasks.
- Embedding tasks (MTEB v2): mmBERT base ties ModernBERT in English (53.9 vs. 53.8) and leads in multilingual (54.1 vs. 52.4 for XLM-R).
- Code retrieval (CoIR): mmBERT outperforms XLM-R by ~9 points, though EuroBERT remains stronger on proprietary data.

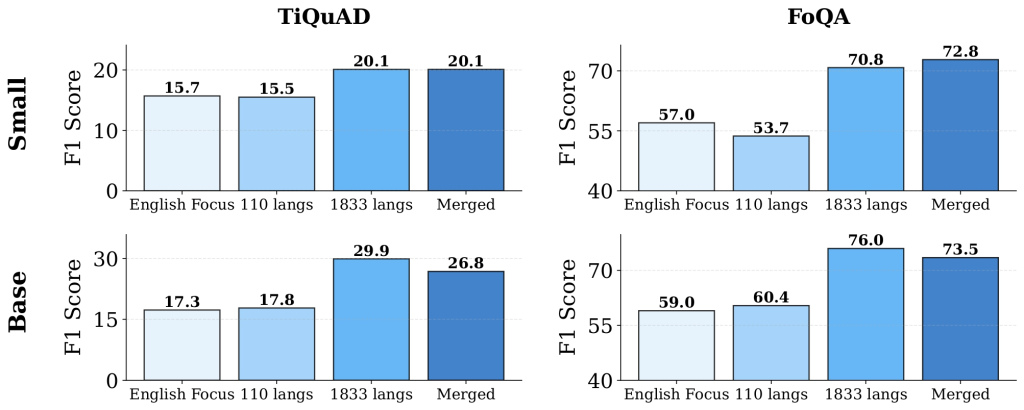
How does mmBERT handle low-resource languages?
The annealed learning schedule ensures that low-resource languages benefit during later training. On benchmarks like Faroese FoQA and Tigrinya TiQuAD, mmBERT significantly outperforms both o3 and Gemini 2.5 Pro. These results demonstrate that encoder models, if trained carefully, can generalize effectively even in extreme low-resource scenarios.
What efficiency gains does mmBERT achieve?
mmBERT is 2–4× faster than XLM-R and MiniLM while supporting 8192-token inputs. Notably, it remains faster at 8192 tokens than older encoders were at 512 tokens. This speed boost derives from the ModernBERT training recipe, efficient attention mechanisms, and optimized embeddings.
Summary
mmBERT comes as the long-overdue replacement for XLM-R, redefining what a multilingual encoder can deliver. It runs 2–4× faster, handles sequences up to 8K tokens, and outperforms prior models on both high-resource benchmarks and low-resource languages that were underserved in the past. Its training recipe—3 trillion tokens paired with annealed language learning, inverse masking, and model merging—shows how careful design can unlock broad generalization without excessive redundancy. The result is an open, efficient, and scalable encoder that not only fills the six-year gap since XLM-R but also provides a robust foundation for the next generation of multilingual NLP systems.
Check out the Paper, Model on Hugging Face, GitHub and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Meet mmBERT: An Encoder-only Language Model Pretrained on 3T Tokens of Multilingual Text in over 1800 Languages and 2–4× Faster than Previous Models appeared first on MarkTechPost.