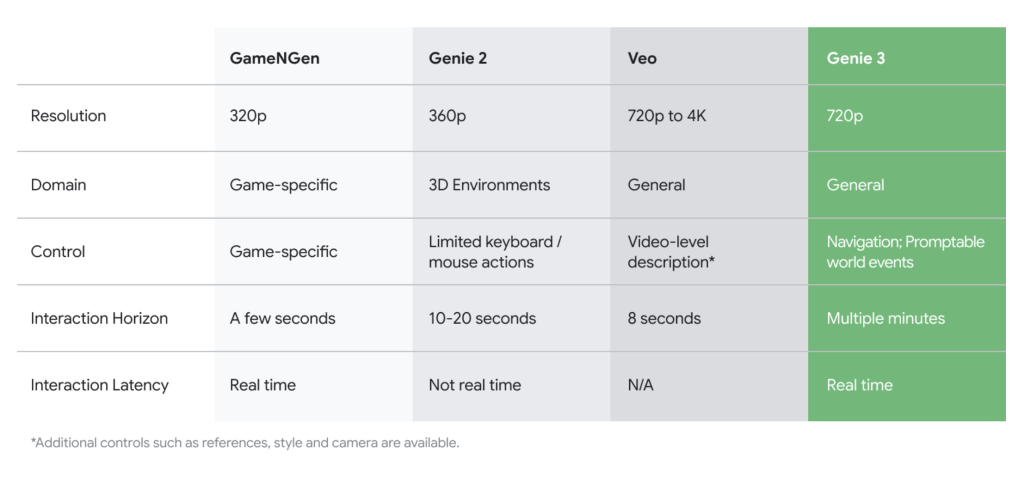
Google DeepMind has announced Genie 3, a revolutionary AI system capable of generating interactive, physically consistent virtual worlds from simple text prompts. This marks a substantial leap in the field of world models—a class of AI designed to understand and simulate environments, not merely render them, but produce dynamic spaces you can move through and interact with like a game engine in real-time. Technical Overview World Model Fundamentals: A world model, in this context, refers to a deep neural network trained to generate and simulate visually rich, interactive virtual environments. Genie 3 leverages advances in generative modeling and large-scale multimodal AI to produce entire worlds at 720p resolution and 24 frames per second that are truly navigable and reactive to user input. Natural Language Prompting: With Genie 3, users provide a plain English description (such as “a beach at sunset, with interactive sandcastles”) and the model synthesizes an environment fitting that description. Unlike traditional generative video or image models, Genie 3’s outputs are not just visual—they’re interactive. Users can walk, jump, or even paint within the environment, and those actions persist and remain consistent even as you explore other regions.youtube World Consistency and Memory: A key innovation is “world memory.” Genie 3’s generated environments retain changes introduced by the user. For example, if you alter an object or leave a mark, returning to that area shows the environment unchanged since your last interaction. This temporal and spatial persistence is crucial for use in training AI agents and robots, and for creating immersive, interactive scenarios that feel stable and real. Performance and Capabilities Smooth real-time interaction: Genie 3 runs at 24fps and 720p, allowing seamless navigation through the generated world. Extensible interaction: While not full-featured like established game engines, it supports fundamental inputs (walking, looking, jumping, painting) and can incorporate dynamic events on the fly (like altering weather, adding characters, etc.). High diversity: Genie 3 can render environments ranging from realistic city streets and schools to entirely fantastical realms, all via simple prompts. Longer horizons: Environments are physically consistent for several minutes—significantly longer than previous models, enabling more sustained play and interaction. Impact and Applications Game Design and Prototyping Genie 3 offers tremendous utility as a tool for ideation and rapid prototyping. Designers can test new mechanics, environments, or artistic ideas in seconds, accelerating creative iteration. It opens up the potential for on-the-fly generation of game scenarios that, while rough, could inspire new genres or gameplay experiences. Robotics and Embodied AI World models like Genie 3 are critical for training robots and embodied AI agents, allowing for extensive simulation-based learning before deployment in the real world. The ability to continuously generate interactive, diverse, and physically plausible environments provides virtually unlimited data for agent training and curriculum development. Beyond Gaming: XR, Education, and Simulation The text-to-world paradigm democratizes the creation of immersive XR experiences, letting smaller teams or even individuals generate new simulations rapidly for education, training, or research. It also paves the way for participatory simulations, digital twins, and agent-based decision-making in areas like urban planning, crisis management, and beyond. Genie 3 and the Future In my opinion, Genie 3 does not aim to replace traditional game engines yet, as it lacks their predictability, precision tools, and collaborative workflows. However, it represents a bridge: future pipelines may involve bouncing between neural world models and conventional engines, using each for what they do best—rapid creative synthesis and fine-grained polish, respectively. World models like Genie 3 are a significant milestone toward Artificial General Intelligence (AGI); they enable richer agent simulation, broader transfer learning, and a step closer to AI systems that understand and reason about the world at a foundational level. Genie 3’s emergence signals an exciting new chapter for AI, simulation, game design, and robotics. Its further development and integration could drastically change both how we build digital experiences and how intelligent agents learn, plan, and interact within complex environments. Check out the Technical Blog. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. The post Google DeepMind Introduces Genie 3: A General Purpose World Model that can Generate an Unprecedented Diversity of Interactive Environments appeared first on MarkTechPost.