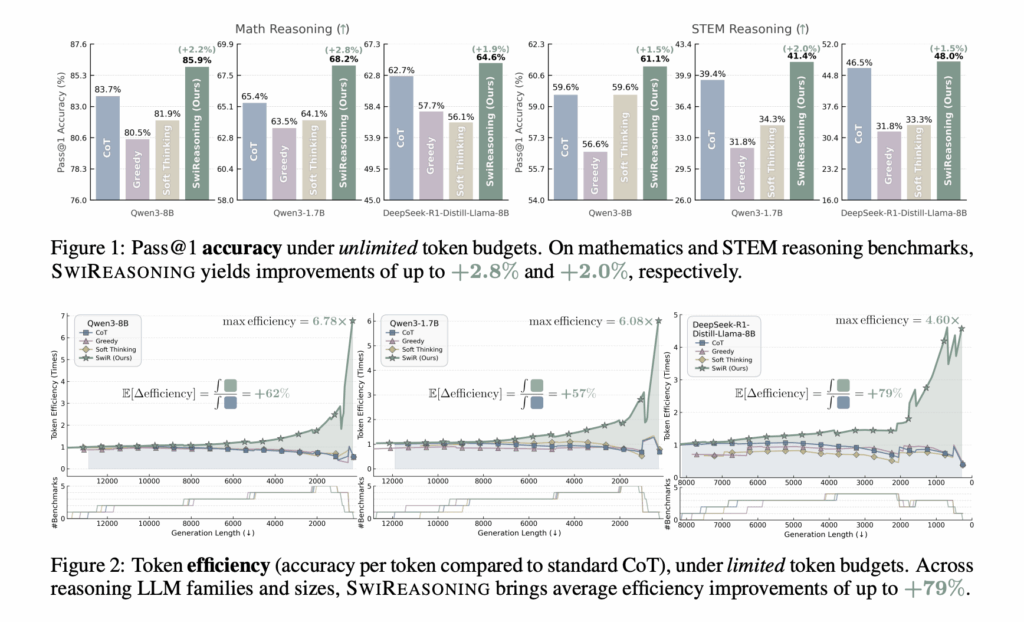
SwiReasoning is a decoding-time framework that lets a reasoning LLM decide when to think in latent space and when to write explicit chain-of-thought, using block-wise confidence estimated from entropy trends in next-token distributions. The method is training-free, model-agnostic, and targets Pareto-superior accuracy/efficiency trade-offs on mathematics and STEM benchmarks. Reported results show +1.5%–2.8% average accuracy improvements with unlimited tokens and +56%–79% average token-efficiency gains under constrained budgets; on AIME’24/’25, it reaches maximum reasoning accuracy earlier than standard CoT. What SwiReasoning changes at inference time? The controller monitors the decoder’s next-token entropy to form a block-wise confidence signal. When confidence is low (entropy trending upward), it enters latent reasoning—the model continues to reason without emitting tokens. When confidence recovers (entropy trending down), it switches back to explicit reasoning, emitting CoT tokens to consolidate and commit to a single path. A switch count control limits the maximum number of thinking-block transitions to suppress overthinking before finalizing the answer. This dynamic alternation is the core mechanism behind the reported accuracy-per-token gains. https://arxiv.org/pdf/2510.05069 Results: accuracy and efficiency on standard suites It reports improvements across mathematics and STEM reasoning tasks: Pass@1 (unlimited budget): accuracy lifts up to +2.8% (math) and +2.0% (STEM) in Figure 1 and Table 1, with a +2.17% average over baselines (CoT with sampling, CoT greedy, and Soft Thinking). Token efficiency (limited budgets): average improvements up to +79% (Figure 2). A comprehensive comparison shows SwiReasoning attains the highest token efficiency in 13/15 evaluations, with an +84% average improvement over CoT across those settings (Figure 4). Pass@k dynamics: with Qwen3-8B on AIME 2024/2025, maximum reasoning accuracies are achieved +50% earlier than CoT on average (Figure 5), indicating faster convergence to the ceiling with fewer sampled trajectories. Why switching helps? Explicit CoT is discrete and readable but locks in a single path prematurely, which can discard useful alternatives. Latent reasoning is continuous and information-dense per step, but purely latent strategies may diffuse probability mass and impede convergence. SwiReasoning adds a confidence-guided alternation: latent phases broaden exploration when the model is uncertain; explicit phases exploit rising confidence to solidify a solution and commit tokens only when beneficial. The switch count control regularizes the process by capping oscillations and limiting prolonged “silent” wandering—addressing both accuracy loss from diffusion and token waste from overthinking cited as challenges for training-free latent methods. Positioning vs. baselines The project compares against CoT with sampling, CoT greedy, and Soft Thinking, reporting a +2.17% average accuracy lift at unlimited budgets (Table 1) and consistent efficiency-per-token advantages under budget constraints. The visualized Pareto frontier shifts outward—either higher accuracy at the same budget or similar accuracy with fewer tokens—across different model families and scales. On AIME’24/’25, the Pass@k curves show that SwiReasoning reaches the performance ceiling with fewer samples than CoT, reflecting improved convergence behavior rather than only better raw ceilings. https://arxiv.org/pdf/2510.05069 https://arxiv.org/pdf/2510.05069 Key Takeaways Training-free controller: SwiReasoning alternates between latent reasoning and explicit chain-of-thought using block-wise confidence from next-token entropy trends. Efficiency gains: Reports +56–79% average token-efficiency improvements under constrained budgets versus CoT, with larger gains as budgets tighten. Accuracy lifts: Achieves +1.5–2.8% average Pass@1 improvements on mathematics/STEM benchmarks at unlimited budgets. Faster convergence: On AIME 2024/2025, reaches maximum reasoning accuracy earlier than CoT (improved Pass@k dynamics). Editorial Comments SwiReasoning is a useful step toward pragmatic “reasoning policy” control at decode time: it’s training-free, slots behind the tokenizer, and exposes measurable gains on math/STEM suites by toggling between latent and explicit CoT using an entropy-trend confidence signal with a capped switch count. The open-source BSD implementation and clear flags (–max_switch_count, –alpha) make replication straightforward and lower the barrier to stacking with orthogonal efficiency layers (e.g., quantization, speculative decoding, KV-cache tricks). The method’s value proposition is “accuracy per token” rather than raw SOTA accuracy, which is operationally important for budgeted inference and batching. Check out the Paper and Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well. The post SwiReasoning: Entropy-Driven Alternation of Latent and Explicit Chain-of-Thought for Reasoning LLMs appeared first on MarkTechPost.